
点击上方的****蓝字关注我吧
程序那些事

简介
我们知道在JVM中为了加快编译速度,引入了JIT即时编译的功能。那么JIT什么时候开始编译的,又是怎么编译的,作为一个高傲的程序员,有没有办法去探究JIT编译的秘密呢?答案是有的,今天和小师妹一起带大家来看一看这个编译背后的秘密。
LogCompilation简介
小师妹:F师兄,JIT这么神器,但是好像就是一个黑盒子,有没有办法可以探寻到其内部的本质呢?
追求真理和探索精神是我们作为程序员的最大优点,想想如果没有玻尔关于原子结构的新理论,怎么会有原子体系的突破,如果没有海森堡的矩阵力学,怎么会有量子力学的建立?
JIT的编译日志输出很简单,使用
-XX:+LogCompilation
就够了。
如果要把日志重定向到一个日志文件中,则可以使用
-XX:LogFile=
但是要开启这些分析的功能,又需要使用
-XX:+UnlockDiagnosticVMOptions
所以总结一下,我们需要这样使用:
-XX:+UnlockDiagnosticVMOptions -XX:+LogCompilation -XX:LogFile=www.flydean.com.log
LogCompilation的使用
根据上面的介绍,我们现场来生成一个JIT的编译日志,为了体现出专业性,这里我们需要使用到JMH来做性能测试。
JMH的全称是Java Microbenchmark Harness,是一个open JDK中用来做性能测试的套件。该套件已经被包含在了JDK 12中。
如果你使用的不是JDK 12,那么需要添加如下依赖:
<dependency>
更多详情可以参考我之前写的:在java中使用JMH(Java Microbenchmark Harness)做性能测试一文。
之前有的朋友说,代码也用图片,看起来好看,从本文之后,我们会尽量把代码也转成图片来展示:
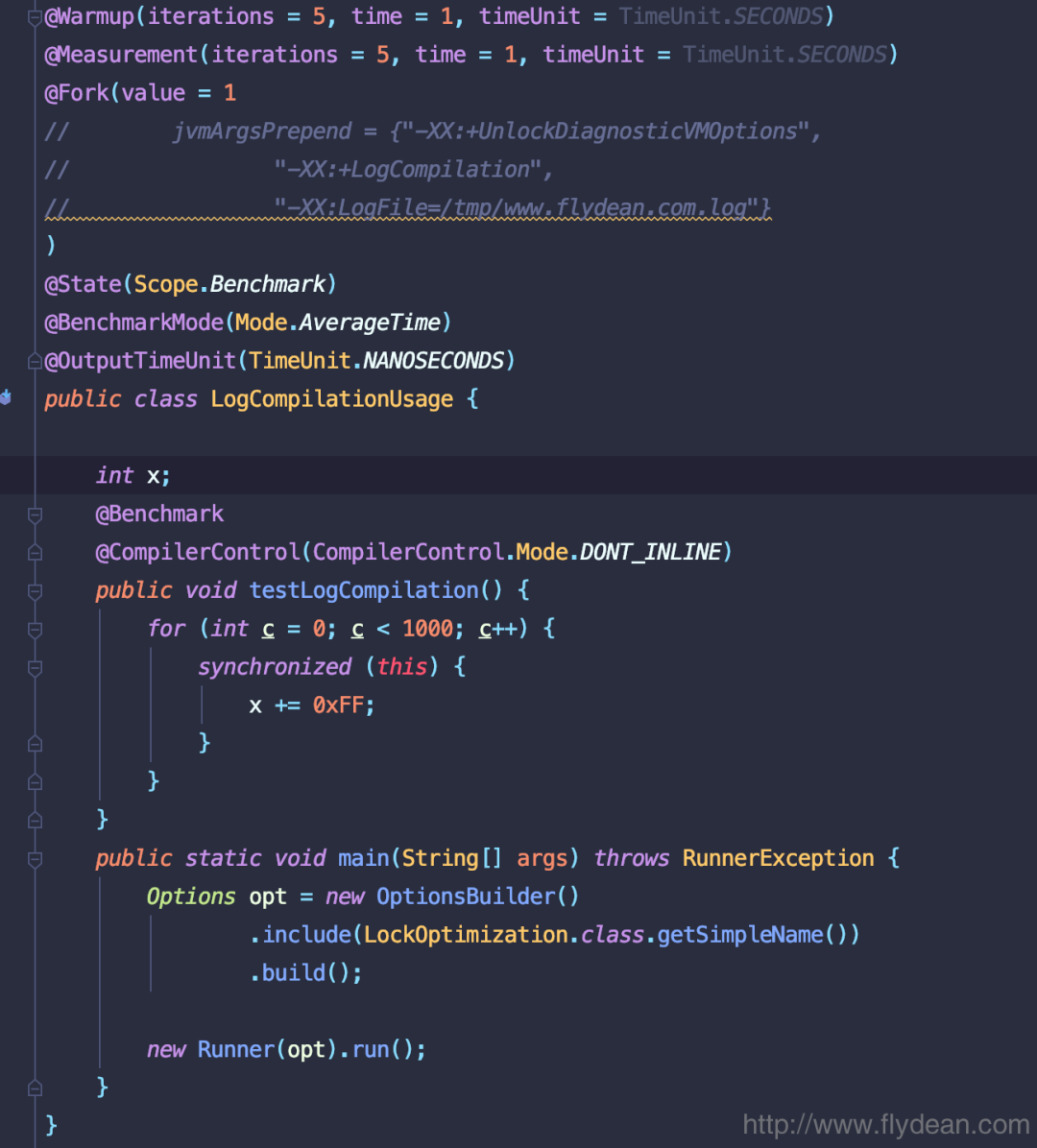
看完我的JMH的介绍,上面的例子应该很清楚了,主要就是做一个累加操作,然后warmup 5轮,测试5轮。
在@Fork注解里面,我们可以配置jvm的参数,为什么我注释掉了呢?因为我发现在jvmArgsPrepend中的-XX:LogFile是不生效的。
没办法,我只好在运行配置中添加:
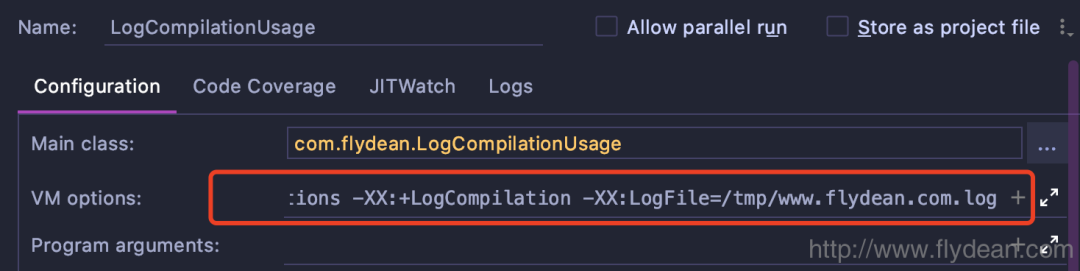
运行之后,你就可以得到输出的编译日志文件。
解析LogCompilation文件
小师妹:F师兄,我看了一下生成的文件好复杂啊,用肉眼能看得明白吗?
别怕,只是内容的多一点,如果我们细细再细细的分析一下,你会发现其实它真的非常非常……复杂!
其实写点简单的小白文不好吗?为什么要来分析这么复杂,又没人看,看了也没人懂的JVM底层…..
大概,这就是专业吧!
LogCompilation文件其实是xml格式的,我们现在来大概分析一下,它的结构,让大家下次看到这个文件也能够大概了解它的重点。
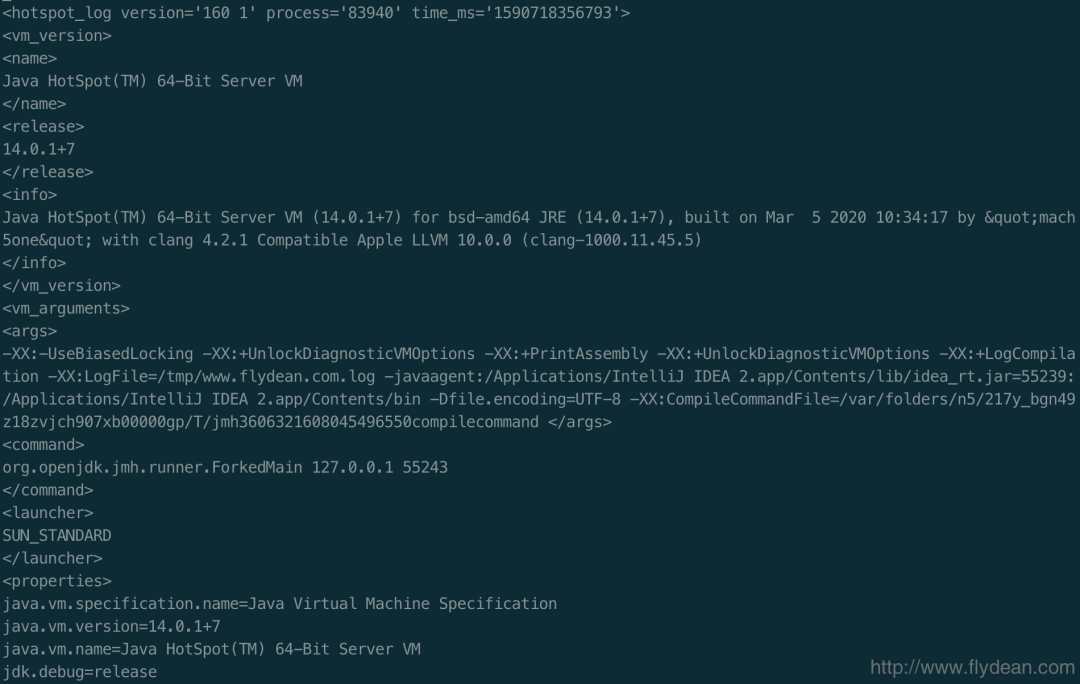
首先最基本的信息就是JVM的信息,包括JVM的版本,JVM运行的参数,还有一些properties属性。
我们收集到的日志其实是分两类的,第一类是应用程序本身的的编译日志,第二类就是编译线程自己内部产生的日志。
第二类的日志会以hs_c*.log的格式存储,然后在JVM退出的时候,再将这些文件跟最终的日志输出文件合并,生成一个整体的日志文件。
比如下面的两个就是编译线程内部的日志:

<thread_logfile thread='22275' filename='/var/folders/n5/217y_bgn49z18zvjch907xb00000gp/T//hs_c22275_pid83940.log'/>
<thread_logfile thread='41731' filename='/var/folders/n5/217y_bgn49z18zvjch907xb00000gp/T//hs_c41731_pid83940.log'/>

上面列出了编译线程的id=22275,如果我们顺着22275找下去,则可以找到具体编译线程的日志:
<compilation_log thread='22275'>...</compilation_log>
上面由compilation_log围起来的部分就是编译日志了。
接下来的部分表示,编译线程开始执行了,其中stamp表示的是启动时间,下图列出了一个完整的编译线程的日志:
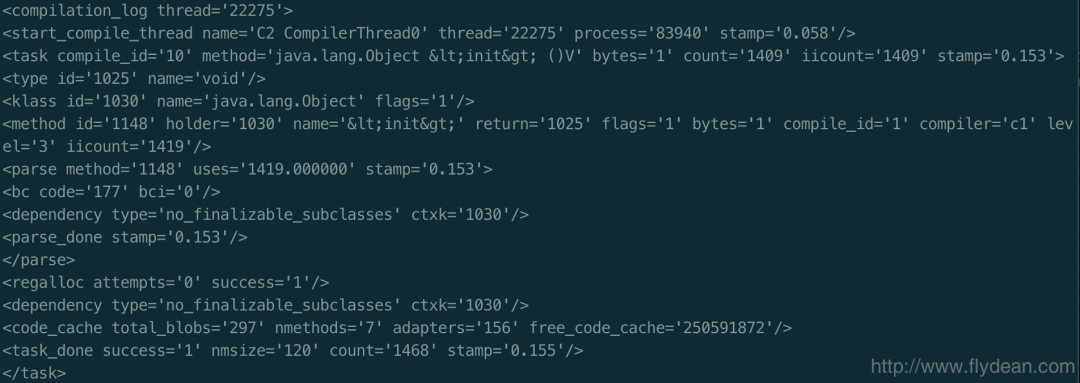
<start_compile_thread name='C2 CompilerThread0' thread='22275' process='83940' stamp='0.058'/>
接下来描述的是要编译的方法信息:
<task compile_id='10' method='java.lang.Object
上面列出了要编译的方法名,compile_id表示的是系统内部分配的编译id,bytes是方法中的字节数,count表示的是该方法的调用次数,注意,这里的次数并不是方法的真实调用次数,只能做一个估计。
iicount是解释器被调用的次数。
task执行了,自然就会执行完成,执行完成的内容是以task_done标签来表示的:
<task_done success='1' nmsize='120' count='1468' stamp='0.155'/>
其中success表示是否成功执行,nmsize表示编译器编译出来的指令大小,以byte为单位。如果有内联的话,还有个inlined_bytes属性,表示inlined的字节个数。
type表示的是方法的返回类型。
klass表示的是实例和数组类型。
<method id='1148' holder='1030' name='
method表示执行的方法,holder是前面的klass的id,表示的是定义该方法的实例或者数组对象。method有名字,有
return,return对应的是上面的type。
flags表示的是方法的访问权限。
接下来是parse,是分析阶段的日志:
上面有parse的方法id。uses是使用次数。
bc是byte Count的缩写,code是byte的个数,bci是byte code的索引。
dependency分析的是类的依赖关系,type表示的是什么类型的依赖,ctkx是依赖的context class。
我们注意有的parse中,可能会有uncommon_trap:
<uncommon_trap bci='10' reason='unstable_if' action='reinterpret' debug_id='0' comment='taken never'/>
怎么理解uncommon_trap呢?字面上意思就是捕获非常用的代码,就是说在解析代码的过程中发现发现这些代码是uncommon的,然后解析产生一个uncommon_trap,不再继续进行了。
它里面有两个比较重要的字段,reason表示的是被标记为uncommon_trap的原因。action表示的出发uncommon_trap的事件。
有些地方还会有call:
<call method='1150' count='5154' prof_factor='1.000000' inline='1'/>
call的意思是,在该代码中将会调用其他的方法。count是执行次数。
总结
复杂的编译日志终于讲完了,可能讲的并不是很全,还有一些其他情况这里并没有列出来,后面如果遇到了,我再添加进去。

作者小F,金融科技从业多年,懂技术又懂金融,主攻Java和区块链方向,篇篇都是用心之作,笔耕不辍,持续更新!
微信号 : 程序那些事
● 扫码关注我吧
喜欢本篇文章?帮忙点个「在看」再走吧

本文分享自微信公众号 - 程序那些事(flydean-tech)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。












