作为一名普通上班族,每个星期都在无休止的上班(没准还加班)之中度过。几个月前一直心心念念的可就是这十一的“小长假”(还调班两天)。
朱小五这次爬取分析携程国内150个热点城市的景点数据,简单的分析一下哪些景点比较受欢迎。用来预计分析一下这个十一哪里最可能人从众从人?
让我们来分析一下。
获取数据
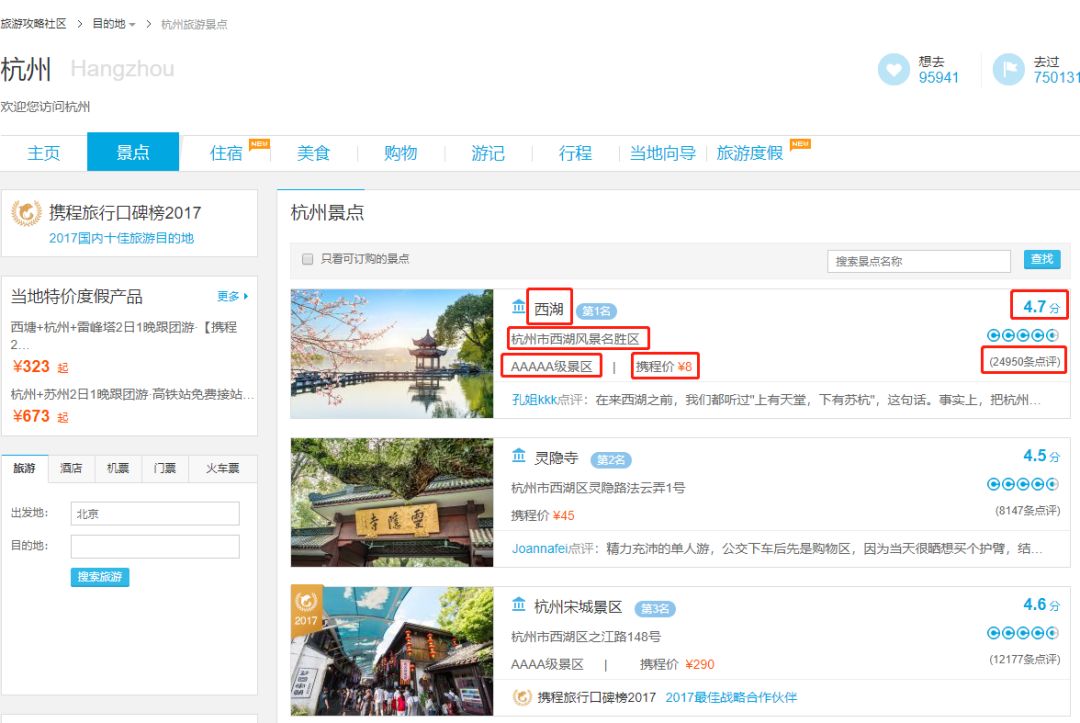
首先,我们来明确一下我们想要爬取的数据是哪些,这里为了方便起见,我们先以目前国内最热门的城市——杭州为例:
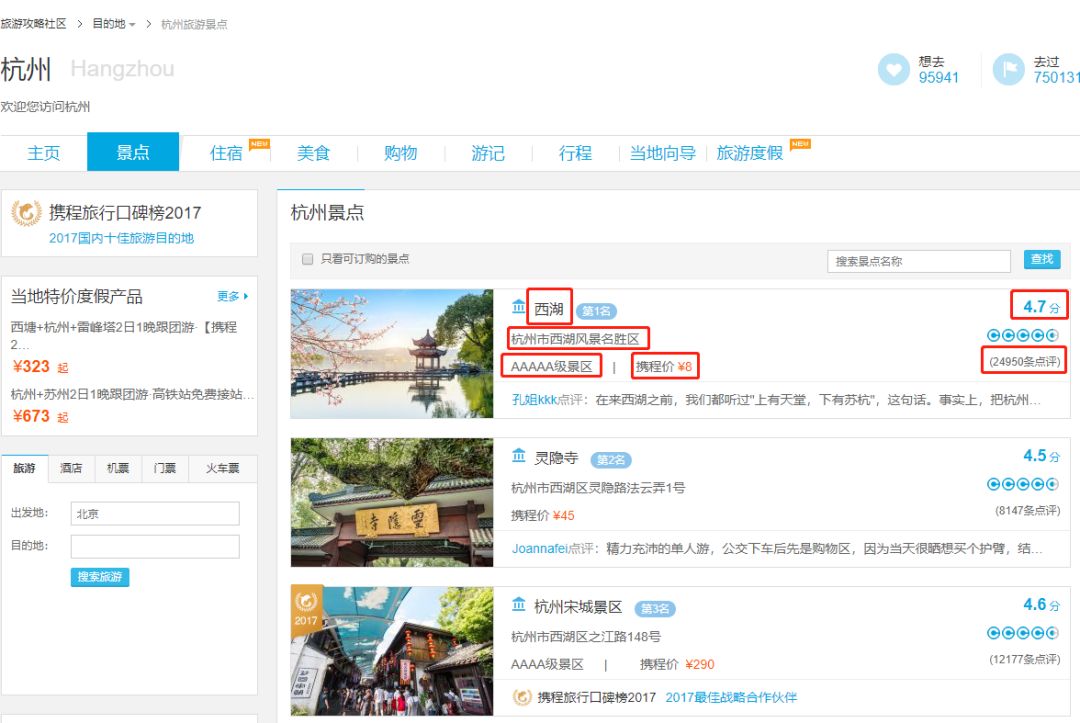
图中的景点名称,地址,评分,景区质量等级、点评数量就是我们本次要获取的数据。其中点评数量正是本次作为判断该景点是否人数会多的重要依据。
翻页即可发现页码变化的规律

这次采用requests+美丽的汤(BeautifulSoup)来爬取。
`def get_list(urls,city):` `data = []
for i in range(1,3):
#爬取n页
url = 'https://you.ctrip.com/sight/'+str(urls)+'/s0-p'+str(i)+'.html#sightname'
results = {}
doc = requests.get(url, headers=headers)
while (doc is None or doc == {'code': -460, 'msg': 'Cheating'}):
print('重新获取!')
time.sleep(random.random())
doc = restaurant(url)
soup = BeautifulSoup(doc.text, features='lxml')
list_wide_mod2 = soup.find_all('div', class_='list_wide_mod2')[0]
for each1, each2 in zip(list_wide_mod2.find_all('dl'), list_wide_mod2.find_all('ul', class_='r_comment')):
name = each1.dt.a.text
addr = each1.find_all('dd')[0].text.strip()
level = each1.find_all('dd')[1].text.strip().split('|')[0].strip()
if '携程' in level:
level = ''
try:
price = each1.find_all('span', class_='price')[0].text.strip().replace('¥', '')
except:
price = '0'
score = each2.find_all('a', class_='score')[0].text.strip().replace('\xa0分', '')
comments = each2.find_all('a', class_='recomment')[0].text.strip()[1: -3].replace('条', '')
results = [city, name, addr, level, price, score, comments]
data.append(results)
final_result = pd.DataFrame(data)
final_result.columns=['city', 'name', 'addr', 'level', 'price', 'score', 'comments']
final_result.to_csv("%s景点数据.csv"%city,encoding="utf_8",index = False)
return final_result`依次爬取150个热门城市
汇总后就获得了3万余条景点数据。
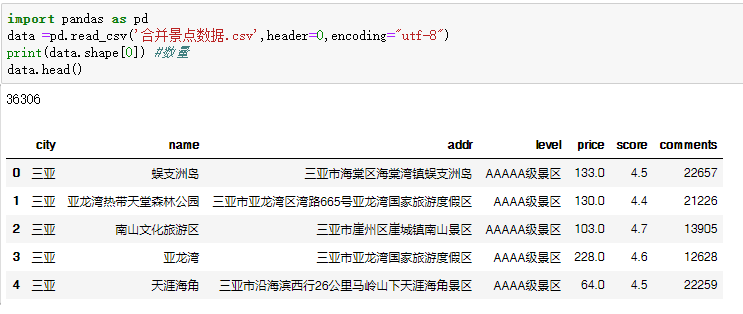
数据分析
清洗填充一下。
def data_cleaning(data):
cols = data.columns
for col in cols:
if data[col].dtype == 'object':
data[col].fillna('缺失数据', inplace = True)
else:
data[col].fillna(0, inplace = True)
return(data)按照评论数量排序,筛选前20的景点。
#排序TOP20
data['comments'] = data['comments'].astype('int')
df = data.sort_values(by="comments",ascending=False)
df.head(20)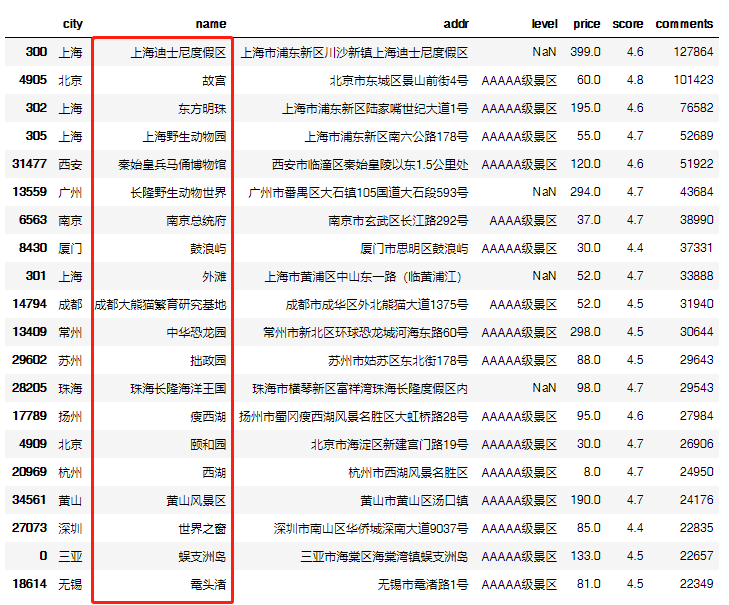
以上这些景点城市是之前的热门,也是仍旧是这次十一最可能人挤人的地方,请注意。
详情数据分析报告请点击:
数据可视化
首先我们将上面的Top20做个词云,更加直观地展示。

消费价格也是衡量景区的一个方面,所以打算区分一下景区的消费价格。
python中对列表以区间进行统计,可以使用下面这个方法:
from itertools import groupby
lst = [1, 1, 1, 2, 3, 4, 4, 5, 5, 6, 7, 7, 7, 7, 8, 9, 9, 9, 10, 99, 99, 99, 100, 101]
dic = {}
for k, g in groupby(lst, key=lambda x: (x-1)//10):
dic['{}-{}'.format(k*10+1, (k+1)*10)] = len(list(g))
print(dic)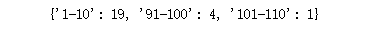
根据得到的结果,我们可以绘制热门旅游景区消费价格区间分布饼图。
from matplotlib import pyplot as plt
#调节图形大小,宽,高
plt.figure(figsize=(5,8))
#定义饼状图的标签,标签是列表
labels = ['0-50元 ', '50-100元 ', '100-150元 ', '150-200元 ', '200及以上 ']
#每个标签占多大
sizes = [33660, 1542, 539, 289, 276]
colors = ['red', 'orange', 'green', 'blue', 'gray', 'goldenrod']
explode = (0, 0, 0, 0, 0.1)
patches,l_text,p_text = plt.pie(sizes,explode=explode,labels=labels,colors=colors,
labeldistance = 1.1,autopct = '%3.1f%%',shadow = False,
startangle = 90,pctdistance = 0.6)
plt.title(u'热门旅游景区消费价格区间分布', fontsize=20)
for t in l_text:
t.set_size=(30)
for t in p_text:
t.set_size=(50)
# 设置x,y轴刻度一致,这样饼图才能是圆的
plt.axis('equal')
plt.legend()
plt.show()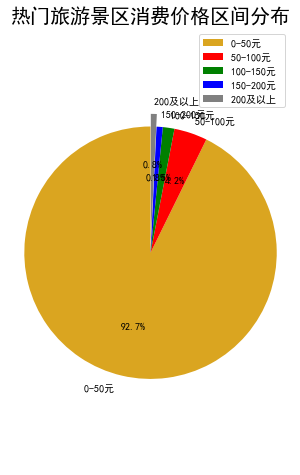
其实国内大部分的景点门票费用并不贵,我们旅途中花销最大的是车票+酒店。
国庆出去玩一趟,实在太难了,每一个国庆去热门景区洗礼过的朋友,都是抱着关关难过关关过的悲壮心态,努力留下几张美好的照片,多吃几口当地的美食,以安慰自己,这一趟,值得。
无论你选择家里蹲七天享受难得的闲暇,还是出去走走见识更大的世界,都祝你国庆七天,跟随本心,快快乐乐~
转载请尽量带上二维码或者结尾注明来源,谢谢了。


本文转转自微信公众号凹凸数据原创https://mp.weixin.qq.com/s/IVSyG-3Mc2AVq3i8vXQYAA,可扫描二维码进行关注:
 如有侵权,请联系删除。
如有侵权,请联系删除。