
Kubernetes,又称为 k8s(_首字母为 k、首字母与尾字母之间有 8 个字符、尾字母为 s_,所以简称 k8s)或者简称为 “kube” ,是一种可自动实施 Linux 容器操作的开源平台。它可以帮助用户省去应用容器化过程的许多手动部署和扩展操作。也就是说,您可以将运行 Linux 容器的多组主机聚集在一起,由 Kubernetes 帮助您轻松高效地管理这些集群。而且,这些集群可跨公共云、私有云或混合云部署主机。因此,对于要求快速扩展的云原生应用而言(例如借助 Apache Kafka 进行的实时数据流处理),Kubernetes 是理想的托管平台。
Kubernetes 最初由 Google 的工程师开发和设计。Google 是最早研发 Linux 容器技术的企业之一,曾公开分享介绍 Google 如何将一切都运行于容器之中(这是 Google 云服务背后的技术)。Google 每周会启用超过 20 亿个容器——全都由内部平台 Borg 支撑。Borg 是 Kubernetes 的前身,多年来开发 Borg 的经验教训成了影响 Kubernetes 中许多技术的主要因素。
趣事:Kubernetes 徽标的七个轮辐代表着项目最初的名称“九之七项目”(Project Seven of Nine)。
真正的生产型应用会涉及多个容器。这些容器必须跨多个服务器主机进行部署。容器安全性需要多层部署,因此可能会比较复杂。但 Kubernetes 有助于解决这一问题。Kubernetes 可以提供所需的编排和管理功能,以便您针对这些工作负载大规模部署容器。借助 Kubernetes 编排功能,您可以构建跨多个容器的应用服务、跨集群调度、扩展这些容器,并长期持续管理这些容器的健康状况。有了 Kubernetes,您便可切实采取一些措施来提高 IT 安全性。
Kubernetes 还需要与联网、存储、安全性、遥测和其他服务整合,以提供全面的容器基础架构。
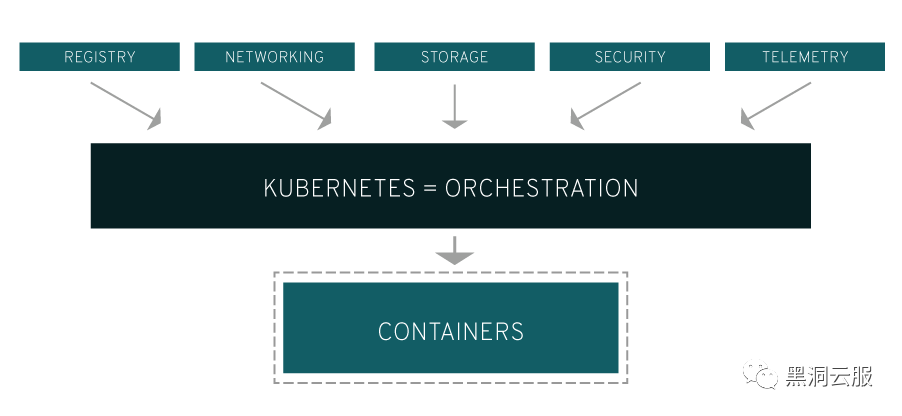
当然,这取决于您如何在您的环境中使用容器。Linux 容器中的基本应用将它们视作高效、快速的虚拟机。一旦把它部署到生产环境或扩展为多个应用,您显然需要许多托管在相同位置的容器来协同提供各种服务。随着这些容器的累积,您运行环境中容器的数量会急剧增加,复杂度也随之增长。
Kubernetes 通过将容器分类组成 “容器集” (pod),解决了容器增殖带来的许多常见问题容器集为分组容器增加了一个抽象层,可帮助您调用工作负载,并为这些容器提供所需的联网和存储等服务。Kubernetes 的其它部分可帮助您在这些容器集之间达成负载平衡,同时确保运行正确数量的容器,充分支持您的工作负载。
如果能正确实施 Kubernetes,再辅以其它开源项目(例如 Atomic 注册表、Open vSwitch、heapster、OAuth 以及 SELinux),您就能够轻松编排容器基础架构的各个部分。
在您生产环境中(尤其是当您要面向云优化应用开发时)使用 Kubernetes 的主要优势在于,它提供了一个便捷有效的平台,让您可以在物理机和虚拟机集群上调度和运行容器。更广泛一点说,它可以帮助您在生产环境中,完全实施并依托基于容器的基础架构运营。由于 Kubernetes 的实质在于实现操作任务自动化,所以您可以将其它应用平台或管理系统分配给您的许多相同任务交给容器来执行。
利用 Kubernetes,您能够达成以下目标:
跨多台主机进行容器编排。
更加充分地利用硬件,最大程度获取运行企业应用所需的资源。
有效管控应用部署和更新,并实现自动化操作。
挂载和增加存储,用于运行有状态的应用。
快速、按需扩展容器化应用及其资源。
对服务进行声明式管理,保证所部署的应用始终按照部署的方式运行。
利用自动布局、自动重启、自动复制以及自动扩展功能,对应用实施状况检查和自我修复。
但是,Kubernetes 需要依赖其它项目来全面提供这些经过编排的服务。因此,借助其它开源项目可以帮助您将 Kubernetes 的全部功用发挥出来。这些功能包括:
注册表,通过 Atomic 注册表或 Docker 注册表等项目实现。
联网,通过 OpenvSwitch 和智能边缘路由等项目实现。
遥测,通过 heapster、kibana、hawkular 和 elastic 等项目实现。
安全性,通过 LDAP、SELinux、RBAC 和 OAUTH 等项目以及多租户层来实现。
自动化,参照 Ansible 手册进行安装和集群生命周期管理。
服务,可通过自带预建版常用应用模式的丰富内容目录来
和其它技术一样,Kubernetes 也会采用一些专用的词汇,这可能会对初学者理解和掌握这项技术造成一定的障碍。为了帮助您了解 Kubernetes,我们在下面来解释一些常用术语。
主机(Master): 用于控制 Kubernetes 节点的计算机。所有任务分配都来自于此。
节点(Node):负责执行请求和所分配任务的计算机。由 Kubernetes 主机负责对节点进行控制。
容器集(Pod):被部署在单个节点上的,且包含一个或多个容器的容器组。同一容器集中的所有容器共享同一个 IP 地址、IPC、主机名称及其它资源。容器集会将网络和存储从底层容器中抽象出来。这样,您就能更加轻松地在集群中移动容器。
复制控制器(Replication controller):用于控制应在集群某处运行的完全相同的容器集副本数量。
服务(Service):将工作内容与容器集分离。Kubernetes 服务代理会自动将服务请求分发到正确的容器集——无论这个容器集会移到集群中的哪个位置,甚至可以被替换掉。
Kubelet:运行在节点上的服务,可读取容器清单(container manifest),确保指定的容器启动并运行。
kubectl: Kubernetes 的命令行配置工具。
学习参考链接:
本文分享自微信公众号 - 云服务圈(heidcloud)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。











