
上篇的 存储引擎技术进化与MergeTree 介绍了存储算法的演进。
存储引擎是一个数据库的底盘,一定要稳和动力澎湃。
接下来我们将一起来探索下 ClickHouse MergeTree 列式存储引擎,解构下这台“跑车”最重要的部件。
所有的存储引擎,无论精良与粗制滥造,最终都是要把数据回写到磁盘,来满足存储和索引目的。
磁盘文件的构造可以说是算法的物理体现,我们甚至可以通过这些存储结构反推出其算法实现。
所以,要想深入了解一个存储引擎,最好的入手点是它的磁盘存储结构,然后再反观它的读、写机制就会有一种水到渠成的感觉。
如果这个分析顺序搞反了,会有一种生硬的感觉,网上大部分教程都是这种“生硬”式教学,本文将直击灵魂从最底层谈起,彻底搞明白4个问题:
MergeTree 有哪些文件?
MergeTree 数据如何分布?
MergeTree 索引如何组织?
MergeTree 如何利用索引加速?
话不多说,上表:
CREATE TABLE default.mt( `a` Int32, `b` Int32, `c` Int32, INDEX `idx_c` (c) TYPE minmax GRANULARITY 1)ENGINE = MergeTreePARTITION BY a ORDER BY bSETTINGS index_granularity=3
造点数据:
insert into default.mt(a,b,c) values(1,1,1);insert into default.mt(a,b,c) values(5,2,2),(5,3,3);insert into default.mt(a,b,c) values(3,10,4),(3,9,5),(3,8,6),(3,7,7),(3,6,8),(3,5,9),(3,4,10);
磁盘文件
ls ckdatas/data/default/mt/1_4_4_0 3_6_6_0 5_5_5_0 detached format_version.txt
可以看到,生成了 3 个数据目录,每个目录在 ClickHouse 里称作一个分区(part),目录名的前缀正是我们写入时字段 a 的值: 1,3,5,因为表分区是这样定位的:PARTITION BY a。
现在我们看看 a=3 分区:
ls ckdatas/data/default/mt/3_6_6_0/a.bin a.mrk2 b.bin b.mrk2 c.bin checksums.txt c.mrk2 columns.txt count.txt minmax_a.idx partition.dat primary.idx skp_idx_idx_c.idx skp_idx_idx_c.mrk2
*.bin 是列数据文件,按主键排序(ORDER BY),这里是按照字段 b 进行排序
*.mrk2 mark 文件,目的是快速定位 bin 文件数据位置
minmax_a.idx 分区键 min-max 索引文件,目的是加速分区键 a 查找
primay.idx 主键索引文件,目的是加速主键 b 查找
skp_idx_idx_c.* 字段 c 索引文件,目的是加速 c 的查找
在磁盘上,MergeTree 只有一种物理排序,就是 ORDER BY 的主键序,其他文件(比如 .mrk/.idx)是一种逻辑加速,围绕仅有的一份物理排序,要解决的问题是:
在以字段 b 物理排序上,如何实现字段 a、字段 c 的快速查找?
MergeTree 引擎概括起来很简单:整个数据集通过分区字段被划分为多个物理分区,每个分区內又通过逻辑文件围绕仅有的一种物理排序进行加速查找。
存储结构
数据文件
对于单个物理分区內的存储结构,首先要明确一点,MergeTree 的数据只有一份:*.bin。
a.bin 是字段 a 的数据,b.bin 是字段 b 的数据,c.bin 是字段 c 的数据,也就是大家熟悉的列存储。
各个 bin 文件以 b.bin排序对齐(b 是排序键),如图:
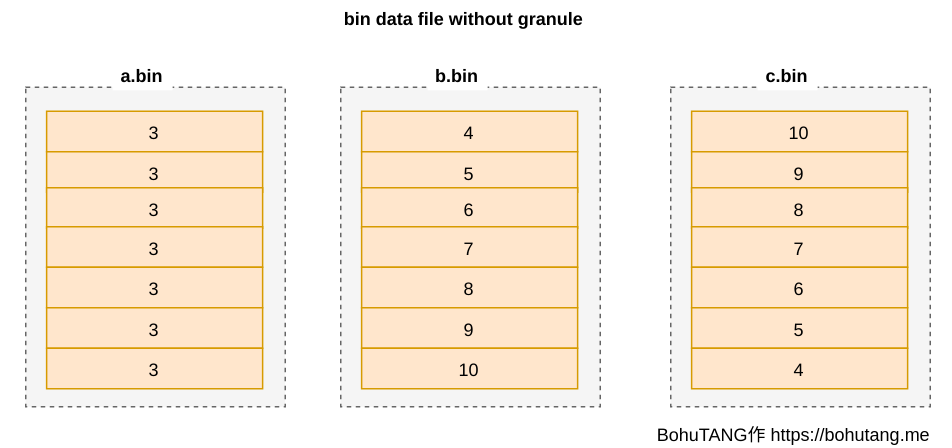
这样会有一个比较严重的问题:如果 *.bin 文件较大,即使读取一行数据,也要加载整个 bin 文件,浪费了大量的 IO,没法忍。
granule
高、黑科技来了,ClickHouse MergeTree 把 bin 文件根据颗粒度(GRANULARITY)划分为多个颗粒(granule),每个 granule 单独压缩存储。
SETTINGS index_granularity=3 表示每 3 行数据为一个 granule,分区目前只有 7 条数据,所以被划分成 3 个 granule(三个色块):
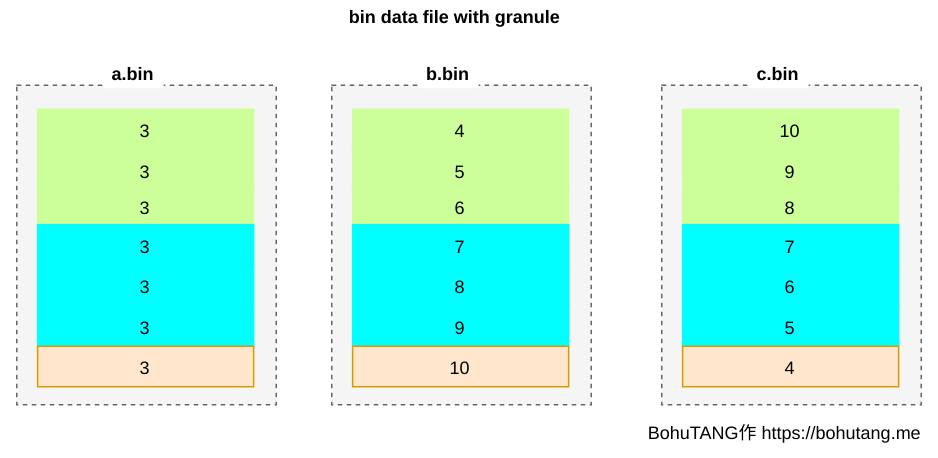
为方便读取某个 granule,使用 *.mrk 文件记录每个 granule 的 offset,每个 granule 的 header 里会记录一些元信息,用于读取解析:
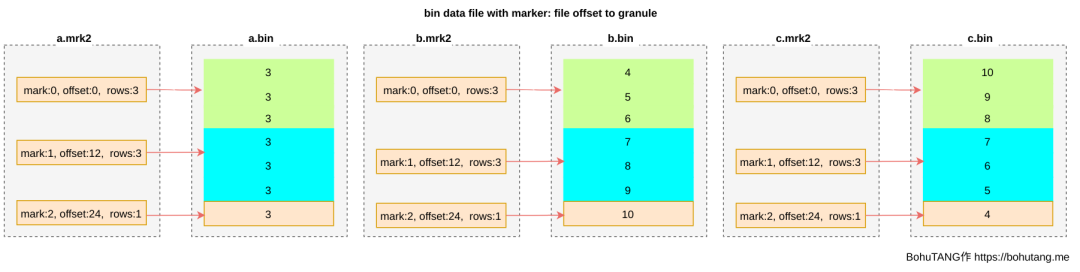
这样,我们就可以根据 mark 文件,直接定位到想要的 granule,然后对这个单独的 granule 进行读取、校验。
目前,我们还有缺少一种映射:每个 mark 与字段值之间的对应,哪些值区间落在 mark0,哪些落在 mark1 ...?
有了这个映射,就可以实现最小化读取 granule 来加速查询:
根据查询条件确定需要哪些 mark
根据 mark 读取相应的 granule
存储排序
在了解 MergeTree 索引机制之前,需要明白以下两点:
只有一份全量数据,存储在 *.bin 文件
*.bin 按照 ORDER BY 字段降序存储

稀疏索引
因为数据只有一份且只有一种物理排序,MergeTree在索引设计上选择了简单、高效的稀疏索引模式。
什么是稀疏索引呢?就是从已经排序的全量数据里,间隔性的选取一些点,并记录这些点属于哪个 mark。
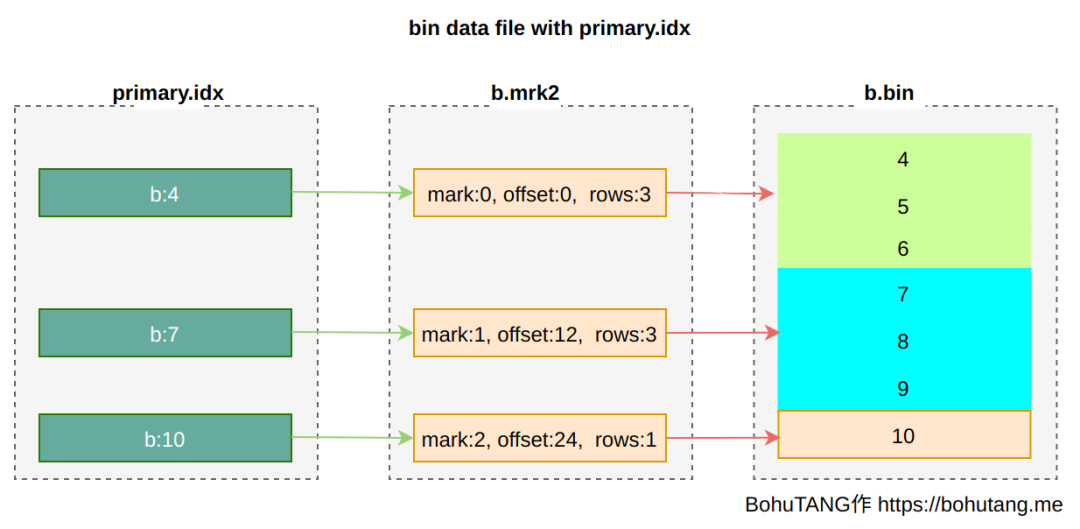
1. primary index
主键索引,可通过[PRIMARY KEY expr]指定,默认是 ORDER BY 字段值。
注意 ClickHouse primary index 跟 MySQL primary key 不是一个概念。
在稀疏点的选择上,取每个 granule 最小值:
2. skipping index
普通索引。
INDEXidx_c(c) TYPE minmax GRANULARITY 1 针对字段 c 创建一个 minmax 模式索引。
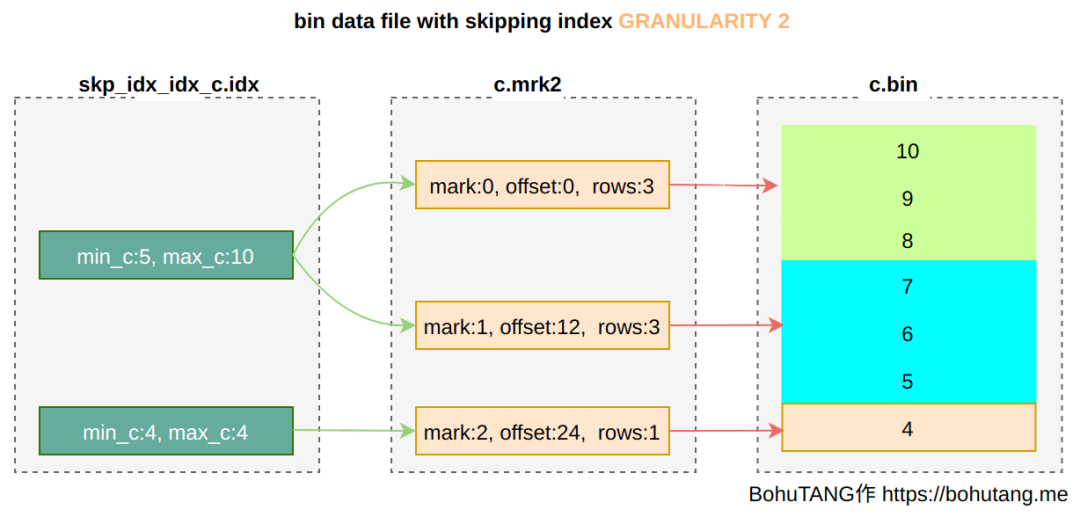
GRANULARITY 是稀疏点选择上的 granule 颗粒度,GRANULARITY 1 表示每 1 个 granule 选取一个:
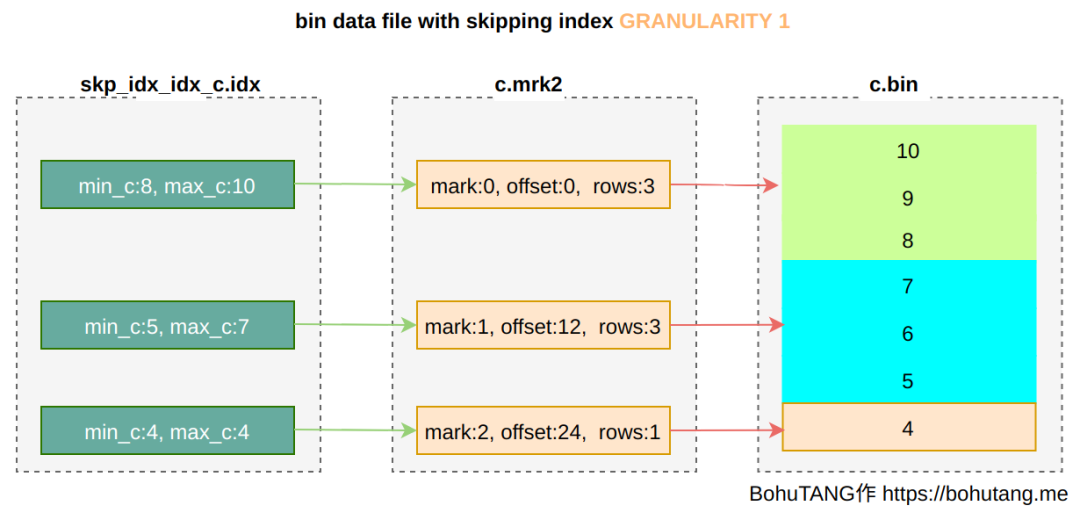
如果定义为GRANULARITY 2 ,则 2 个 granule 选取一个:
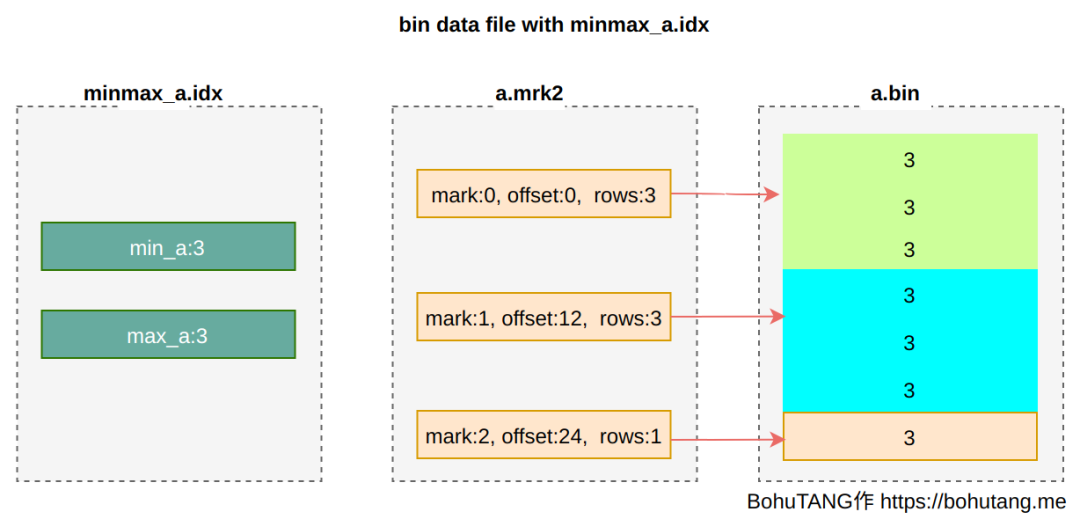
3. partition minmax index
针对分区键,MergeTree 还会创建一个 min/max 索引,来加速分区选择。
4. 全景图

查询优化
现在熟悉了 MergeTree 的存储结构,我们通过几个查询来体验下。
1. 分区键查询
语句:
select * from default.mt where a=3
查询会直接根据 a=3 定位到单个分区:
<Debug> InterpreterSelectQuery: MergeTreeWhereOptimizer: condition "a = 3" moved to PREWHERE<Debug> default.mt (SelectExecutor): Key condition: unknown<Debug> default.mt (SelectExecutor): MinMax index condition: (column 0 in [3, 3])<Debug> default.mt (SelectExecutor): Selected 1 parts by a, 1 parts by key, 3 marks by primary key, 3 marks to read from 1 ranges┌─a─┬──b─┬──c─┐│ 3 │ 4 │ 10 ││ 3 │ 5 │ 9 ││ 3 │ 6 │ 8 ││ 3 │ 7 │ 7 ││ 3 │ 8 │ 6 ││ 3 │ 9 │ 5 ││ 3 │ 10 │ 4 │└───┴────┴────┘
2. 主键索引查询
语句:
select * from default.mt where b=5
查询会先从 3 个分区读取 prmary.idx,然后定位到只有一个分区符合条件,找到要读取的 mark:
<Debug> default.mt (SelectExecutor): Key condition: (column 0 in [5, 5])<Debug> default.mt (SelectExecutor): MinMax index condition: unknown<Debug> default.mt (SelectExecutor): Selected 3 parts by a, 1 parts by key, 1 marks by primary key, 1 marks to read from 1 ranges┌─a─┬─b─┬─c─┐│ 3 │ 5 │ 9 │└───┴───┴───┘
3. 索引查询
语句:
select * from default.mt where b=5
查询会先从 3 个分区读取 prmary.idx 和 skp_idx_idx_c.idx 进行 granule 过滤(没用的 drop 掉),然后定位到只有 3_x_x_x 分区的一个 granule 符合条件:
<Debug> InterpreterSelectQuery: MergeTreeWhereOptimizer: condition "c = 5" moved to PREWHERE<Debug> default.mt (SelectExecutor): Key condition: unknown<Debug> default.mt (SelectExecutor): MinMax index condition: unknown<Debug> default.mt (SelectExecutor): Index `idx_c` has dropped 1 / 1 granules.<Debug> default.mt (SelectExecutor): Index `idx_c` has dropped 1 / 1 granules.<Debug> default.mt (SelectExecutor): Index `idx_c` has dropped 2 / 3 granules.<Debug> default.mt (SelectExecutor): Selected 3 parts by a, 1 parts by key, 5 marks by primary key, 1 marks to read from 1 ranges┌─a─┬─b─┬─c─┐│ 3 │ 9 │ 5 │└───┴───┴───┘
总结
本文从磁盘存储结构入手,分析 ClickHouse MergeTree 的存储、索引设计。
只有了解了这些底层机制,我们才好对自己的 SQL 和表结构进行优化,使其执行更加高效。
ClickHouse MergeTree 设计简单、高效,它首要解决的问题是:在一种物理排序上,如何实现快速查找。
针对这个问题,ClickHouse使用稀疏索引来解决。
在官方 roadmap 上,列举了一个有意思的索引方向:Z-Order Indexing,目的是把多个维度编码到一维存储,当我们给出多维度条件的时候,可以快速定位到这个条件点集的空间位置,目前 ClickHouse 针对这个索引设计暂无进展。
延伸阅读
全文完。
Enjoy ClickHouse :)
叶老师的「MySQL核心优化」大课已升级到MySQL 8.0,扫码开启MySQL 8.0修行之旅吧

本文分享自微信公众号 - 老叶茶馆(iMySQL_WX)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。











