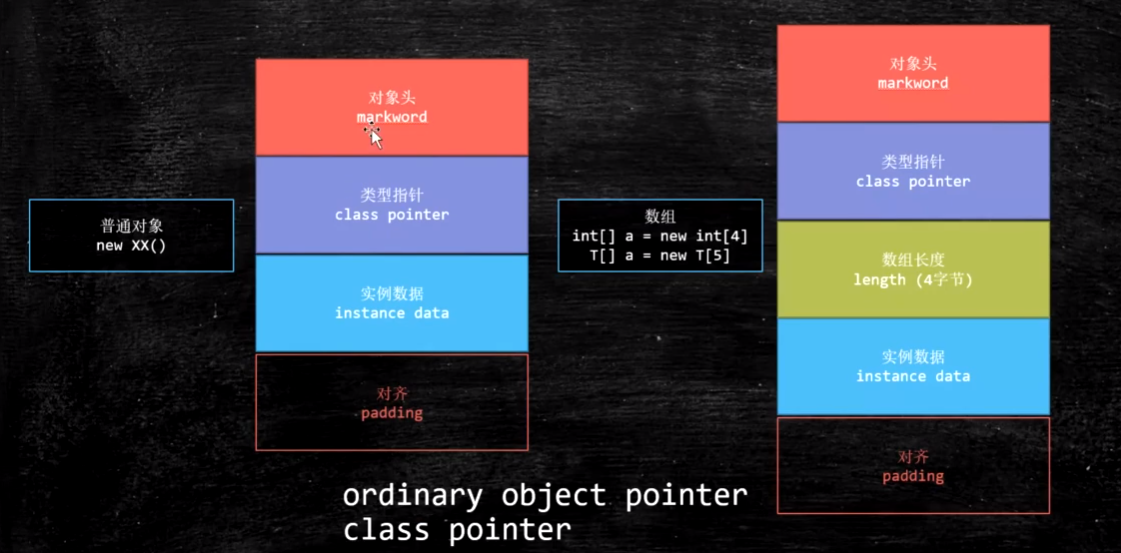
先来看看Java对象在内存中的布局
一 Java对象的内存布局
在HotSpot虚拟机中,对象在内存中的布局分为3个区域 对象头(Header) Mark Word(在32bit和64bit虚拟机上长度分别为32bit和64bit)存储对象自身的运行时数据,包括哈希码,GC分代年龄,锁状态标志,线程持有的锁,偏向线程ID,偏向时 间戳等
类型指针 即对象指向它的类元数据的指针,虚拟机通过这个指针来确定这个对象是哪个类的实例.但是并不是所有类型虚拟机实现都必须在对象数据上保留类型指针,如果对象是一个java数组,那在对象头中还必须有一块用于记录数组长度的数据,因为虚拟机可以通过普通java对象的元数据信息确定Java对象的大小,但是从数组的元数据中却无法确定数据的大小
实例数据(Instance Data) 对象真正存储信息的地方,也是代码中所定义的各种类型的字段内容.无论是继承下来的,还是子类中定义的,都需要记录起来.
对象填充(Padding) 并不是必然存在的,也没有特别的含义仅仅起到点位符的作用.由于HotSpot的自动管理内存系统要求对象起始地址是8字节的整数倍,换句话说就是对象的大小必须是8字节的整数倍,而对象头正好是8字节的倍数(1倍或者2倍),因此当对象实例部分没有对齐时,就需要通过对齐填充来补全 知道了Java对象的内存布局,那么如何定位到对象呢?
二 Java对象的访问定位
对立对象是为了使用对象.Java程序需要通过在栈上的reference数据操作堆上的具体对象. 由于reference类型在Java虚拟机规范中只规定了一个指向对象的引用,并没有定义这个引用应该通过何种方式去定位,访问堆中的对象的具体位置,所以对象的访问方式取决于虚拟机的实现而定的. 目前主流的访问对象的方式有两种
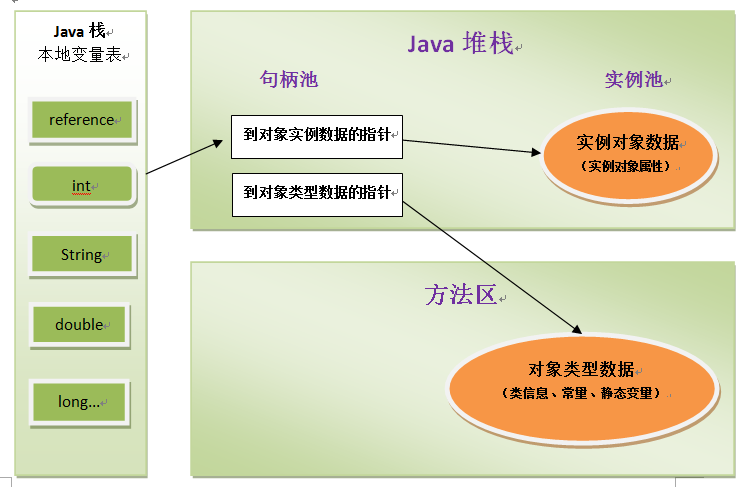
句柄
- 定义: Java堆中将会划分出一块内存来作为句柄池,refenerce中存储的就是对象的句柄的地址,而句柄中包 含了对象实例数据与类型数据各自的具体地址信息
- 优点 : 最大的好处就是reference中存储的是稳定的句柄的地址,在对象被移动(垃圾回收时移动对象是很常见的行为)时只会改变句柄中的实例数据的地址,而reference本身不需要修改
直接指针
- 定义 : reference中存储直接对象的地址,但是必须考虑放置访问类型数据的相关信息
- 优点 : 访问速度快,节省了一次指针定位的时间开销
注:HotSpot使用第2种方法,但是使用句柄的方法也很常见
这两种对象访问用两张图表示如下:
第一种: 使用句柄方式:
第二种:直接指针方式:
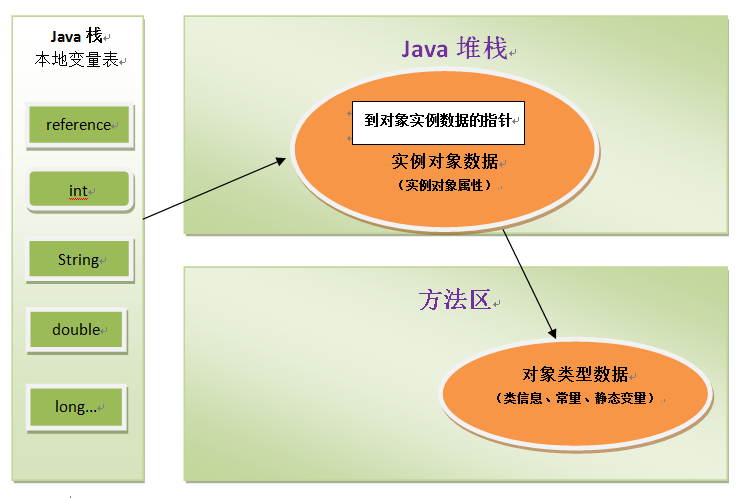
以上两张图明确的表示出句柄和指针两种方法.