
文章目录
(一)Linux系统和大数据
(二)Hadoop
(1)Hadoop包含哪些模块?
(2)Hadoop的生态成员
(3)哪些人在使用Hadoop?
(三)Spark
(1)Scala
(2)RDD
(3)主件
(四)云计算
(1)虚拟化技术
(2)云计算特点
(3)云计算应用
(五)Python数据分析工具
(1)Pandas
(2)matplotlib
(3)scikit-learn
附:参考资料
(一)Linux系统和大数据
- 大数据分析需要可扩展,易用,灵活的计算分析,大量的数据需要通过一个硬件的集群制造一个计算资源之外的可扩展优势
- Linux的低门槛使得集群架设可以以低成本完成,这使得Linux成为这些年在处理数据上显得更有更好的表现和更高效
- Linux容器运行你去打包和隔离应用使得你可以在各种环境(开发,测试,生产…)下移动数据,对于完成大数据的数据处理工作,容器是一个快速简单的方式
- Linux系统在这方面的优势:用户社区庞大,开源免费,可跨平台,多用户多任务,高能高效,安全稳定,硬件计算快速,网络功能完善
(二)Hadoop
Apache Hadoop 是一款支持数据密集型分布式应用程序并以Apache 2.0许可协议发布的开源软件框架。它支持在商品硬件构建的大型集群上运行的应用程序。Hadoop 是根据谷歌公司发表的MapReduce和Google文件系统的论文自行实现而成。所有的Hadoop模块都有一个基本假设,即硬件故障是常见情况,应该由框架自动处理。

(1)Hadoop包含哪些模块?
- 常用模块(Hadoop Common):常用模块可以为其他模块提供效用
- HDFS:HDFS是分布式文件系统(Hadoop Distributed FIle Syetem )的简称,分布式文件系统可以为应用数据提供高吞吐量的处理
- YARN:一个为工作调度和集群资源管理而设计的框架
- MapReduce:一个为庞大数据集所用的可并行YARN基础系统
- Ozone:一个Hadoop的对象存储
(2)Hadoop的生态成员
- HBase:HBase是一个开源的非关系型分布式数据库,它参考了谷歌的BigTable建模,实现的编程语言为Java。
- Hive:Hive是一个建立在Hadoop架构之上的数据仓库。它能够提供数据的精炼,查询和分析。
- ZooKeeper:ZooKeeper是Apache软件基金会的一个软件项目,它为大型分布式计算提供开源的分布式配置服务、同步服务和命名注册。 ZooKeeper曾经是Hadoop的一个子项目,但现在是一个独立的顶级项目。 ZooKeeper的架构通过冗余服务实现高可用性。

- Pig:Pig是一个基于Apache Hadoop的大规模数据分析平台,它提供的SQL-LIKE语言叫Pig Latin,该语言的编译器会把类SQL的数据分析请求转换为一系列经过优化处理的MapReduce运算。
(3)哪些人在使用Hadoop?
- Amazon
- Fox Interactive Media
- 华为
- IBM
- ImageShack
- 信息学研究院
- 纽约时报
- 中国移动
… …
(三)Spark
Spark是一个开源集群运算框架,最初是由加州大学柏克莱分校AMPLab所开发。相对于Hadoop的MapReduce会在运行完工作后将中介数据存放到磁盘中,Spark使用了存储器内运算技术,能在数据尚未写入硬盘时即在存储器内分析运算。
Spark在存储器内运行程序的运算速度能做到比Hadoop MapReduce的运算速度快上100倍,即便是运行程序于硬盘时,Spark也能快上10倍速度。Spark允许用户将数据加载至集群存储器,并多次对其进行查询,非常适合用于机器学习算法

(1)Scala
Scala是一门多范式的编程语言,设计初衷是要集成面向对象编程和函数式编程的各种特性。
def qsort(list: List[Int]): List[Int] = list match {
case Nil => Nil
case pivot :: tail =>
val(smaller, rest) = tail.partition(_ < pivot)
qsort(smaller) ::: pivot :: qsort(rest)
}
(2)RDD
Spark RDD(英语:Resilient Distributed Dataset,弹性分布式数据集)是一种数据存储集合。只能由它支持的数据源或是由其他RDD经过一定的转换(Transformation)来产生。在RDD上可以执行的操作有两种转换(Transformation)和行动(Action),每个 RDD 都记录了自己是如何由持久化存储中的源数据计算得出的,即其血统(Lineage)。
(3)主件
- Spark SQL:Spark用来操作结构化数据的组件
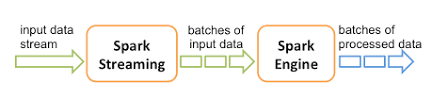
- Spark Streaming:Spark平台上针对实时数据进行流式计算的组件
- MLlib:Spark提供的一个机器学习算法库
- GraphX:Spark面向图计算提供的框架与算法库
(四)云计算
云计算(cloud computing)是一种基于互联网的计算方式,通过这种方式,共享的软硬件资源和信息可以按需求提供给计算机各种终端和其他设备,使用服务商提供的电脑基建作计算和资源
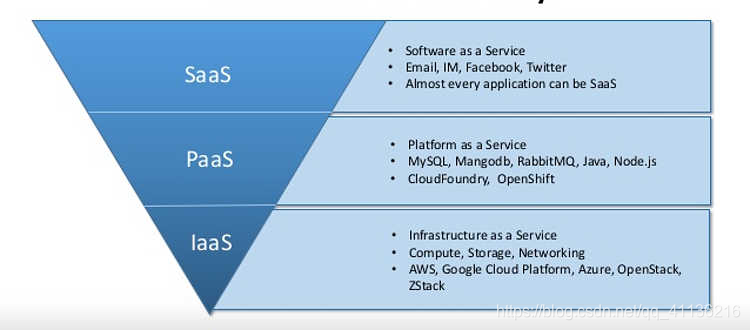
- SaaS:软件服务,Software-as-a-service
- PaaS:平台服务,Platform-as-a-service
- IaaS:基础设施服务,Infrastructure-as-a-service
(1)虚拟化技术
云计算虚拟化技术支持用户在任意位置、使用各种终端获取服务。虚拟化技术是实现云计算基础架构层面(IaaS)的核心技术
(2)云计算特点
根据美国国家标准和技术研究院的定义,云计算服务应该具备以下几条 特征:
- 随需应变自助服务。
- 随时随地用任何网络设备访问。
- 多人共享资源池。
- 快速重新部署灵活度。
- 可被监控与量测的服务。
从研究现状来看,云计算具有以下 特点:
- (1)超大规模。
- (2)虚拟化。
- (3)高可靠性。
- (4)通用性。
- (5)高可伸缩性。
- (6)按需服务。
- (7)极其廉价。
(3)云计算应用
- 云教育
- 云物联
- 云安全
- 云政务
- 云存储
(五)Python数据分析工具
(1)Pandas
Pandas 是一个由Python编程语言为了数据操作和分析而建立的软件库

(2)matplotlib
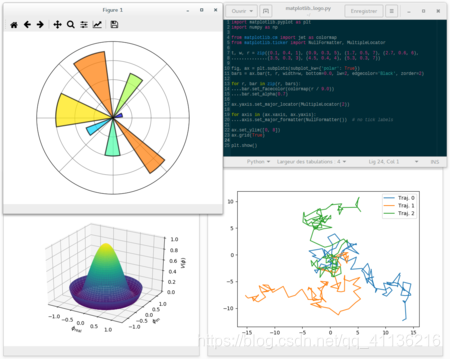
matplotlib 是Python编程语言及其数值数学扩展包 NumPy的可视化操作界面。它利用通用的图形用户界面工具包,如Tkinter, wxPython, Qt或GTK+,向应用程序嵌入式绘图提供了应用程序接口(API)
(3)scikit-learn
scikit-learn 是Python的开源机器学习库,它的特色是多种多样的分类,回归,线性等算法包含了提供向量化,随机森林,梯度推进,K-means和DBSCAN,并且依赖于Python数值库NumPy和科学库SciPy设计为互操作

附:参考资料
《Why Linux is the powerhouse for big data》
https://www.computerweekly.com/blog/Open-Source-Insider/Why-Linux-is-the-powerhouse-for-big-data
维基百科·Hadoop
Hadoop官网
维基百科·Spark
维基百科·Panda
维基百科·matplotlib
scikit-learn官网











