
SQL Server数据库基础知识
存储过程概述
什么是存储过程?
存储过程的种类
如何创建、修改、删除、调用存储过程?
存储过程的优缺点
存储过程和触发器的区别?
存储过程和函数的区别?
存储过程的使用
1. 什么是存储过程?
存储过程是一个预编译的SQL语句,优点是允许模块化的设计,就是说只需创建一次,以后在程序中就可以调用多次。如果某次操作需要执行多次SQL,使用存储过程比单纯SQL语句执行要快。可以用一个“execute 存储过程名 参数”命令来调用存储过程。
2. 存储过程的种类
1 系统存储过程
以sp_开头,用来进行系统的各项设定.取得信息.相关管理工作。
2 自定义存储过程(本地存储过程)
以cp_开头,是用户为了完成某一特定功能而创建的存储过程,一般所说的存储过程就是指本地存储过程。
3 临时存储过程
分为两种存储过程:
一是本地临时存储过程,以井字号(#)作为其名称的第一个字符,则该存储过程将成为一个存放在tempdb数据库中的本地临时存储过程,且只有创建它的用户才能执行它;
二是全局临时存储过程,以两个井字号(##)号开始,则该存储过程将成为一个存储在tempdb数据库中的全局临时存储过程,全局临时存储过程一旦创建,以后连接到服务器的任意用户都可以执行它,而且不需要特定的权限。
4 远程存储过程
在SQL Server2005中,远程存储过程(Remote Stored Procedures)是位于远程服务器上的存储过程,通常可以使用分布式查询和EXECUTE命令执行一个远程存储过程。
5 扩展存储过程
扩展存储过程(Extended Stored Procedures)是用户可以使用外部程序语言编写的存储过程,而且扩展存储过程的名称通常以xp_开头。
3. 如何创建、修改、删除、调用存储过程?
–创建存储过程
create proc 存储过程名字
as
语句–修改存储过程
alter proc 存储过程名字
as
语句–卸载存储过程
drop proc 存储过程名字–调用存储过程
exec 存储过程名称
4. 存储过程的优缺点
优点:
1.存储过程只在创造时进行编译,以后每次执行存储过程都不需再重新编译,而一般SQL语句每执行一次就编译一次,所以使用存储过程可提高数据库执行速度。
2.当对数据库进行复杂操作时(如对多个表进行Update,Insert,Query,Delete时),可将此复杂操作用存储过程封装起来与数据库提供的事务处理结合一起使用。
3.存储过程可以重复使用,可减少数据库开发人员的工作量(复用性高,面向对象的编程思想)
4.安全性高,可设定只有某些用户才具有对指定存储过程的使用权
缺点:
1:调试麻烦,但是用 PL/SQL Developer 调试很方便!弥补这个缺点。
2:移植问题,数据库端代码当然是与数据库相关的。但是如果是做工程型项目,基本不存在移植问题。
3:重新编译问题,因为后端代码是运行前编译的,如果带有引用关系的对象发生改变时,受影响的存储过 程、包将需要重新编译(不过也可以设置成运行时刻自动编译)。
4: 如果在一个程序系统中大量的使用存储过程,到程序交付使用的时候随着用户需求的增加会导致数据结构的变 化,接着就是系统的相关问题了,最后如果用户想维护该系统可以说是很难很难、而且代价是空前的,维护起来更麻烦。
5. 存储过程和触发器的区别?
触发器与存储过程的主要区别在于触发器的运行方式。存储过程必须有用户、应用程序或者触发器来显示的调用并执行,而触发器是当特定时间出现的时候,自动执行或者激活的,与连接用数据库中的用户、或者应用程序无关。
6. 存储过程和函数的区别?
存储过程是用户定义的一系列SQL语句的集合,而函数通常是数据库已定义的方法,具体区别如下:
1.对于存储过程来说可以返回参数,而函数只能返回值或者表对象.
2.函数必须有返回值,存储过程可有可无
3.存储过程一般是作为一个独立的部分来执行,而函数可以作为查询语句的一部分来调用
7. 存储过程的使用
接下来以两张表来向大家演示存储过程的使用。
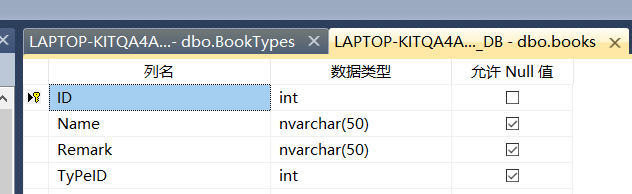
书籍分类表(BookTypes)和书籍表(books)结构设计
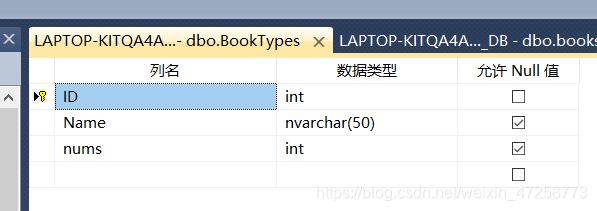
书籍分类表(BookTypes)
ID
Name(分类名称)
Nums(数量)
1
科技类
10
2
文学类
10
3
军事类
10
书籍表(books)
ID
Name(书籍名称)
Remark(备注)
TypeID(分类ID)
1
数据库
NULL
1
2
西游记
NULL
2
3
百团大战
NULL
3
4
数据库
NULL
1
5
数据库
NULL
1
6
数据库
NULL
1
7
数据库
NULL
1
1:不带参数的存储过程
--创建存储过程查询数据
create proc cp_select_book_bybook --创建一个叫cp_select_book_bybook的存储过程
as --要执行的操作
select * from books --从books表中查询数据
--调用存储过程
exec cp_select_book_bybook
2:带输入参数的存储过程
--根据名称参数查询数据
create proc cp_select_book_ByName
(
@name varchar(50)
)
as
select*from books where name like '%'+@name+'%'
--调用
exec cp_select_book_ByName'数据库'
3:带输出参数的存储过程
--根据名称查询,返回记录,同时返回记录数
go
create proc cp_select_book_ByNameExt
(
@name varchar(50),
@recordRows int out --out表示输出类型
)
as
select*from books where name like '%'+@name+'%'
select @recordRows=count(*) from books
--调用
--定义一个变量,接收返回参数@recordRows的值
declare @rs int --定义一个变量接收@recordRows的数据
exec cp_select_book_ByNameExt'数据库',@rs out
print '查询到的记录数是:'+convert(varchar(50),@rs)
4:简单的分页的存储过程的创建和调用
--根据名称,页码,每页显示的条数 --输入参数
--返回查询条件的总记录数 --输出参数
--显示查询结果
go
create proc cp_page
(
@name varchar(50),
@pageIndex int, --页码
@pageSize int, --每页显示条数
@rs int out --总记录数,out表示输出类型
)
as
select top (@pageSize)*from books
where id not in(
select top (@pageSize*(@pageIndex-1)) id from books where name like '%'+@name+'%'
order by id
)
and name like '%'+@name+'%' order by id
select @rs= count(*) from books where name like '%'+@name+'%'
--调用
--定义一个变量,接收返回参数@totalcount的值
declare @rows int --定义一个变量接收@totalcount的数据
exec cp_page'数据库',1,5,@rows out
print '查询到的总记录数是:'+convert(varchar(50),@rows)










