
前言
现在很多人都在从事区块链方面的研究,作者也一直在基于Hyperledger Fabric做一些开发工作。为了方便后来人更快的入门,本着“开源”的精神,在本文中向大家讲解一下Hyperledger Fabric账本的结构和原理。作者解析的Fabric的工程版本为v1.0.1,在新版本中可能会有些许偏差。
ps:作者默认各位读者已经具备了一定的区块链基本知识,不再做一些基础知识的阐述。
Hyperledger Fabric账本的结构
在作者最初了解bitcoin的时候有一个疑问:矿工如何校验一笔交易中引入的Utxo是否合法呢?如果过是从创世块开始遍历工作量会随着块的增加而逐渐变大。当作者研究过Bitcoin的源码后发现,在Bitcoin中有一部分模块是用来存储当前所有Utxo的,它采用的是levelDB数据库,在校验一笔交易中的Utxo是否合法时直接去DB中检索即可。
Bitcoin的这种做法给作者总结为如下:“单纯”的区块链账本存储区块数据即可,而为了方便支持各种功能往往会提取出一些数据(重要的、频繁访问的)独立存储。在Bitcoin的世界中矿工的共识实际上是对当前Utxo的共识,所以它将Utxo从区块量账本中提取出来独立的存储,那在Hyperledger Fabric中需要从区块账本中提取出的数据是什么?
Fabric中是一个针对商业应用的分布式账本技术,本身并不存在代币,你可以在它的基础上进行二次开发,利用Fabric的智能合约实现自己需要的各种业务--包括发放代币。在它的智能合约模块中有两个最关键的接口中:shim.PutState(Key, Value) 和 shim.GetState(Key),这个是用来向节点本地读写数据的指令,它呈现给智能合约的是一个key-value结构的非关系形数据库。然后Client通过调用智能合约执行业务逻辑,智能合约来进行数据的读写操作的(在区块链的世界中调用智能合约的Request统称为Transaction,这是约定俗称的,虽然在Fabric中没有代币),这和传统的中心化Web服务十分相似,只不过Tomcat换成了Fabric,而后台的jar包换成了智能合约,中心化的APP变成了分布式的DAPP。
现在参照作者从Bitcoin中总结的规律,在Fabric智能合约中读写的业务数据符合重要的、频繁访问的特征,应该独立存储,这个数据库的名称为StateDB 。除了StateDB以外我们还要保存区块数据,在Fabric里面它有一个自己的FileSystem,用来存储区块数据,这个文件系统是存储在本地的文件中的。区块数据被连续的写入到本地的BlockFile中,通过File.io来读写数据,Fabric工程是用go语言编写的,工程中操作文件IO的包是os ,包中常用操作文件的函数如下:
type File
func Create(name string) (*File, error)
func NewFile(fd uintptr, name string) *File
func Open(name string) (*File, error)
func OpenFile(name string, flag int, perm FileMode) (*File, error)
func Pipe() (r *File, w *File, err error)
func (f *File) Chdir() error
func (f *File) Chmod(mode FileMode) error
func (f *File) Chown(uid, gid int) error
func (f *File) Close() error
func (f *File) Fd() uintptr
func (f *File) Name() string
func (f *File) Read(b []byte) (n int, err error)
func (f *File) ReadAt(b []byte, off int64) (n int, err error)
func (f *File) Readdir(n int) ([]FileInfo, error)
func (f *File) Readdirnames(n int) (names []string, err error)
func (f *File) Seek(offset int64, whence int) (ret int64, err error)
func (f *File) SetDeadline(t time.Time) error
func (f *File) SetReadDeadline(t time.Time) error
func (f *File) SetWriteDeadline(t time.Time) error
func (f *File) Stat() (FileInfo, error)
func (f *File) Sync() error
func (f *File) Truncate(size int64) error
func (f *File) Write(b []byte) (n int, err error)
func (f *File) WriteAt(b []byte, off int64) (n int, err error)
func (f *File) WriteString(s string) (n int, err error)
type FileInfo
func Lstat(name string) (FileInfo, error)
func Stat(name string) (FileInfo, error)
type FileMode
func (m FileMode) IsDir() bool
func (m FileMode) IsRegular() bool
func (m FileMode) Perm() FileMode
func (m FileMode) String() string
Q1:以上所有的接口都不支持复杂的查询功能,读者们可以想象一下,当要去BlockFile中读取一个块的时候要什么样的条件才能快速的找到对应块?
A1: 如果查询者能知道一个Block数据在文件中的便宜量则可以快速定位到Block,相反则只能通过遍历的方式。为了解决这个问题Fabric 将Block在BlockFile文件中的偏移量记载到了一个非关系形DB中,这个DB的名称为indexDB。
Q2:区块数据是不可篡改的,也就是说BlockFile的size是持续增长的,如果size过大超过了位置偏移量的最大范围怎么办?
A2: 将区块数据存储在多个文件块中,以blockfile_ 为前缀,以块的生成次序为后缀。
解决了上面的两个问题后,查询一个块数据的过程如下:
setup1: 从indexDB中读取Block的位置信息(blockfile的编号、位置偏移量);
setup2: 打开对应的blockfile,位移到指定位置,读取Block数据。
Fabric账本的整体结构图来如下图所示:
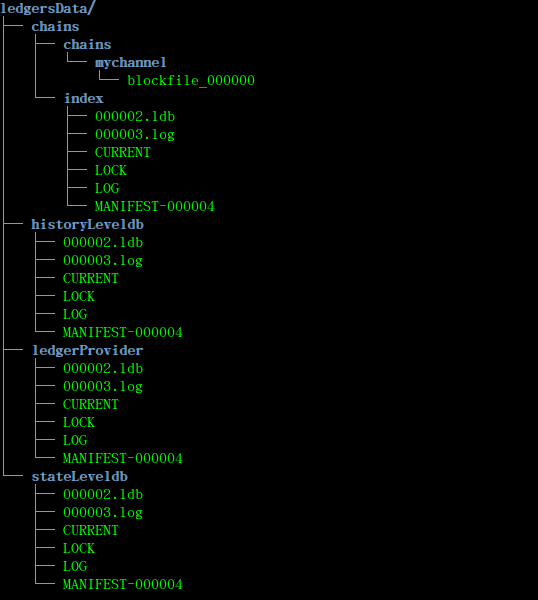
其中ledgersData是整个账本的根目录,作者会逐个文件夹进行解析:
(1)_chains_:chains/chains下包含的mychannel是对应的channel的名称,因为Fabric是有多channel的机制,而channel之间的账本是隔离的,每个channel都有自己的账本空间。chains/index下面包含的是levelDB数据库文件,在Fabric中默认所有的数据库都是LevelDB,这个原因作者下面会讲到,DB中存储的就是我们上面说的区块索引部分。chains/chains和chains/index就是上面所说的File System和indexDB;
(2)_stateLeveldb:_ 同样是levelDB数据库,存储的就是我们上面所说的智能合约putstate写入的数据;
(3)_ledgerProvider:_数据库内存储的是当前节点所包含channel的信息(已经创建的channel id 和正在创建中的channel id),主要是为了Fabric的多channel机制服务的;
(4)_historyLeveldb:_数据库内存储的是智能合约中写入的key的历史记录的索引地址。
Hyperledger Fabric账本详解
这一部分作者会结合几个问题对Hyperledger Fabric 区块链账本的内在原理进行深入的剖析,其中会涉及到源码部分的解析,如果读者只是想对账本机制做一些简单了解,可以跳过源码分析的部分。
Q3: 智能合约读写数据到stateLeveldb的流程?
A3:作者以GetState()接口为例进行说明:
首先,读者们需要明确Hyperledger Fabric的智能合约是在docker容器中运行的,而stateLeveldb是位于节点服务器本地的。同时,Fabric没有将stateLevelDB映射到docker容器中,所以智能合约不能直接访问stateLevelDB。
Fabric中是通过rpc服务调用的方式,来解决这个问题的。开发过Fabric智能合约的读者应该清楚,Fabric提供了一个中间层Shim包,同时在Peer节点中默认会开启一个grpc服务 ChainCodeService。智能合约文件在编译的时候会自动引入shim包,而shim包中在GetState的过程中会向节点的ChainCodeService发送请求到节点,然后节点再从本地的stateLevelDB中读取请求的数据,返回给智能合约。
流程图:
以上只是读数据的过程,写数据远比读数据更为复杂。
//TODO 写数据过程
Q4:fabric支持交易的查询接口,那么交易查询是如何实现的?
A4: 交易查询与Block查询的实现原理一致,节点在写入账本到本地的时候,会将交易在FileSystem中的索引也写入indexDB中。
Q5: indexDB是levelDB,它是如何实现复杂查询的,比如交易的范围查询?
未完待续... ...











