
点击上方 蓝色字体 ,选择“ 设为星标 ”
回复”资源“获取更多资源


想必大家已经听说了,1 月 21 日,开源的可视化工具 Apache Superset 宣布毕业并成为 Apache 软件基金会(ASF)的顶级项目(Top-Level Project)。

截至目前,Superset荣登Github热榜Top10,并且Superset也迎来了v1.0.0大版本的更新。Github地址: https://github.com/apache/superset ,有33000+ Star,小编曾经在阿里云社区试用过Superset,本文将对Superset做一个全面的讲解,看看它到底适用于哪些场景。
Superset简介
Apache Superset 是一款现代化的开源数据工具,用于数据探索和数据可视化。它提供了简单易用的无代码可视化构建器和声称是最先进的 SQL 编辑器,用户可以使用这些工具快速地构建数据仪表盘。
Apache Superset 将 SQL IDE、数据浏览工具、拖拽式仪表板编辑器和插件组合使用,以构建自定义的可视化效果,支持从许多关系数据库和非关系数据库中创建仪表板,这些数据库包括 SQLite、MySQL,以及 Amazon Redshift、Google BigQuery、Snowflake、Oracle 数据库、IBM DB2 和其他各种兼容的数据源,并且可以连接到 Apache Drill 和 Apache Druid。此外,Superset 还适用于云原生场景和 Docker。
主要具有以下功能特性:
丰富的数据可视化集
易于使用的界面,用于浏览和可视化数据
创建和共享仪表板
与主要身份验证提供程序(数据库,OpenID,LDAP,OAuth和REMOTE_USER通过Flask AppBuilder集成)集成的企业就绪身份验证
可扩展的高粒度安全性/权限模型,允许有关谁可以访问单个要素和数据集的复杂规则
一个简单的语义层,允许用户通过定义哪些字段应显示在哪些下拉列表中以及哪些聚合和功能度量可供用户使用来控制如何在UI中显示数据源
通过SQLAlchemy与大多数说SQL的RDBMS集成
以上那些都是废话,老实说对开发人员最大的吸引力:支持的数据源足够多,界面足够花里胡哨!
Superset丰富的数据源支持和图表展示
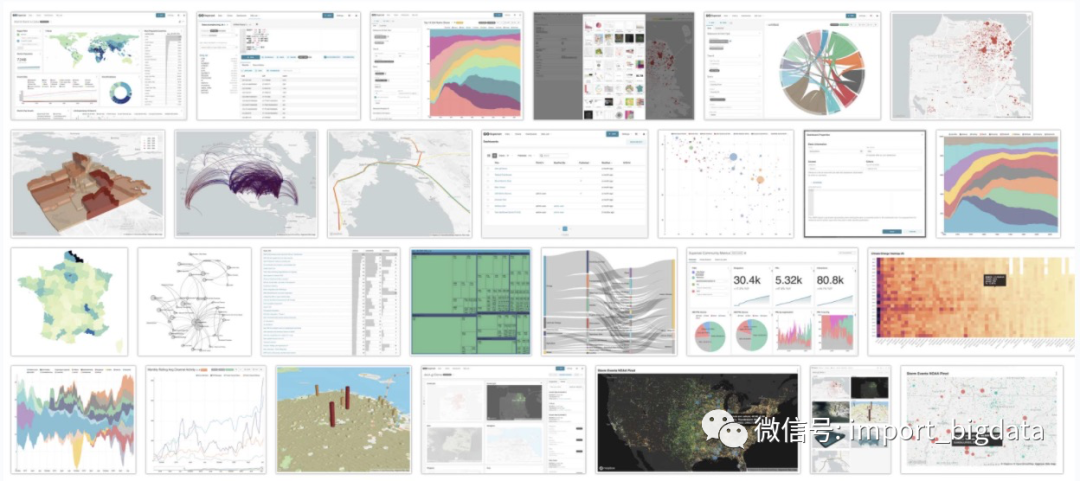
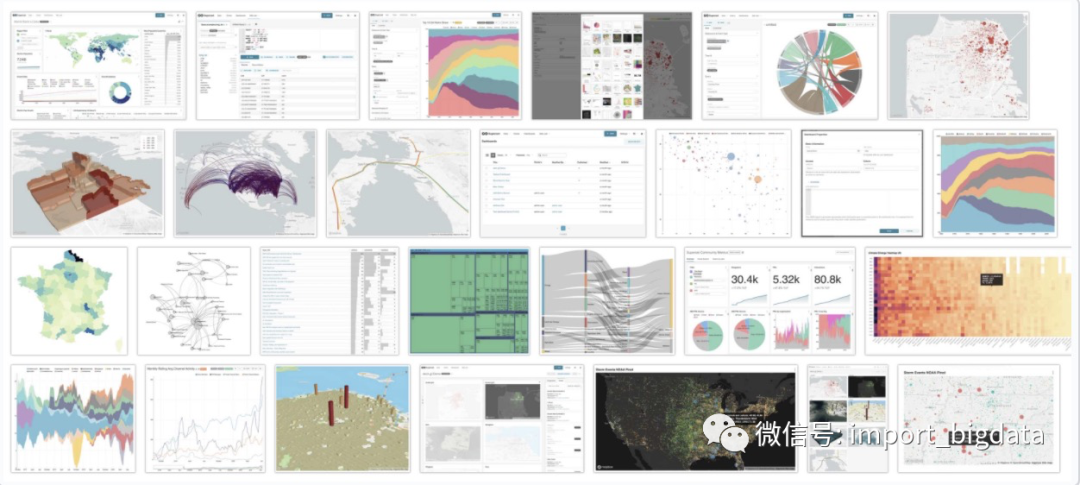
上面展示了Superset支持的图表类型的冰山一角,另外Superset深度集成了非常丰富的数据源:

这其中,包含了大数据领域常见的 Druid、ClickHouse、Presto等OLAP数据库,这些数据库都是大数据领域最经常应用的。
你还可以通过直接写 SQL 来展示数据:
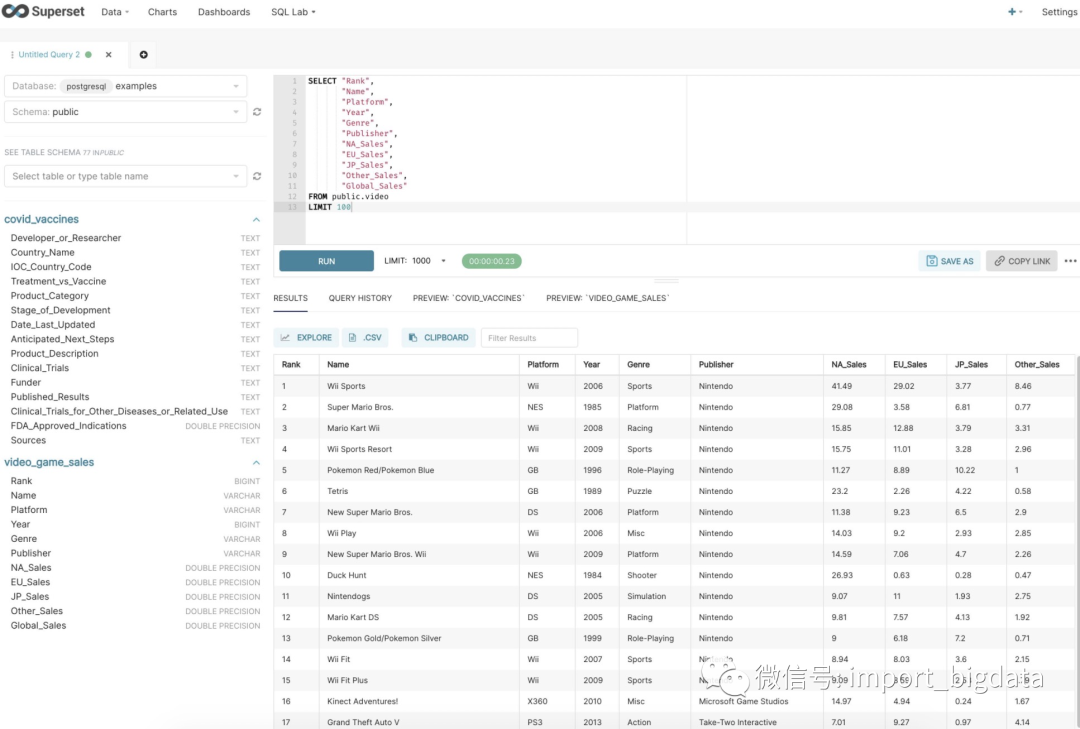
Superset极其简单的安装和配置
大家要特别注意,由于Superset是Python开发的,所以本地需要进行Python的环境安装。另外,需要有pip这个包管理工具。这对Java为主的大数据体系的程序员有一丢丢的挑战,不过相信大家可以克服。
由于小编只是进行测试,我本地直接使用pip安装:
#安装pip install superset #创建管理员用户名和密码 fabmanager create-admin --app superset #初始化superset db upgrade #装载样例数据 superset load_examples #创建默认角色和权限 superset init #启动superset runserver
更推荐大家使用Docker Compose的方式安装:
$ git clone https://github.com/apache/superset.git$ cd superset$ docker-compose up
然后就可以访问本地的: http://localhost:8088 进入到Superset的首页了。
目前Superset几乎支持了市面上主流的常用数据库,我们可以对照官网的文档安装不同数据源所需要的依赖包。
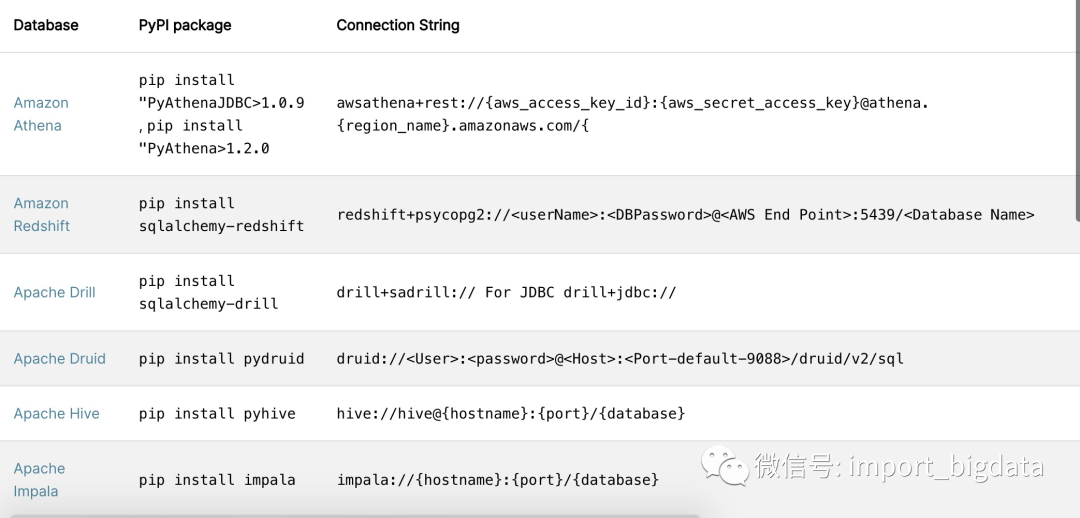
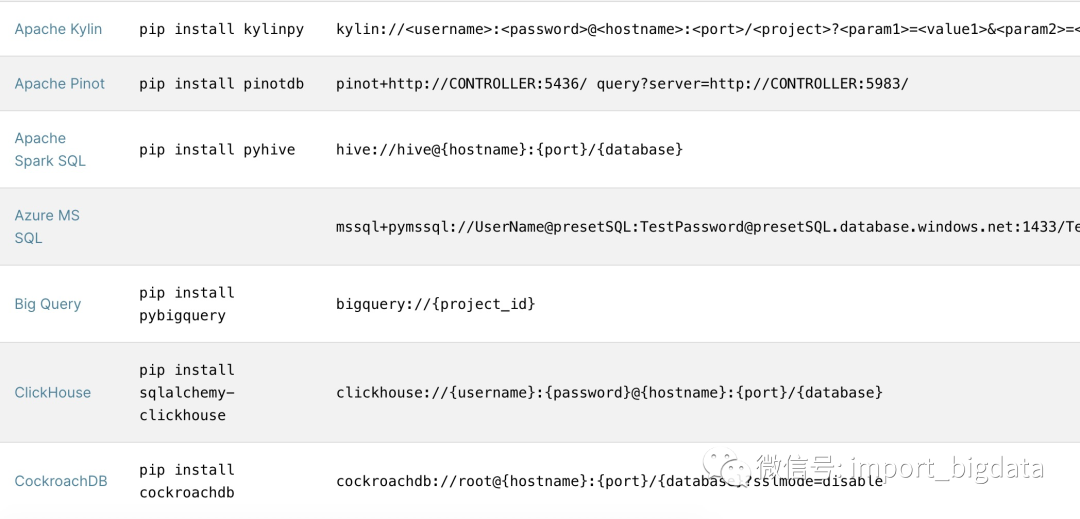
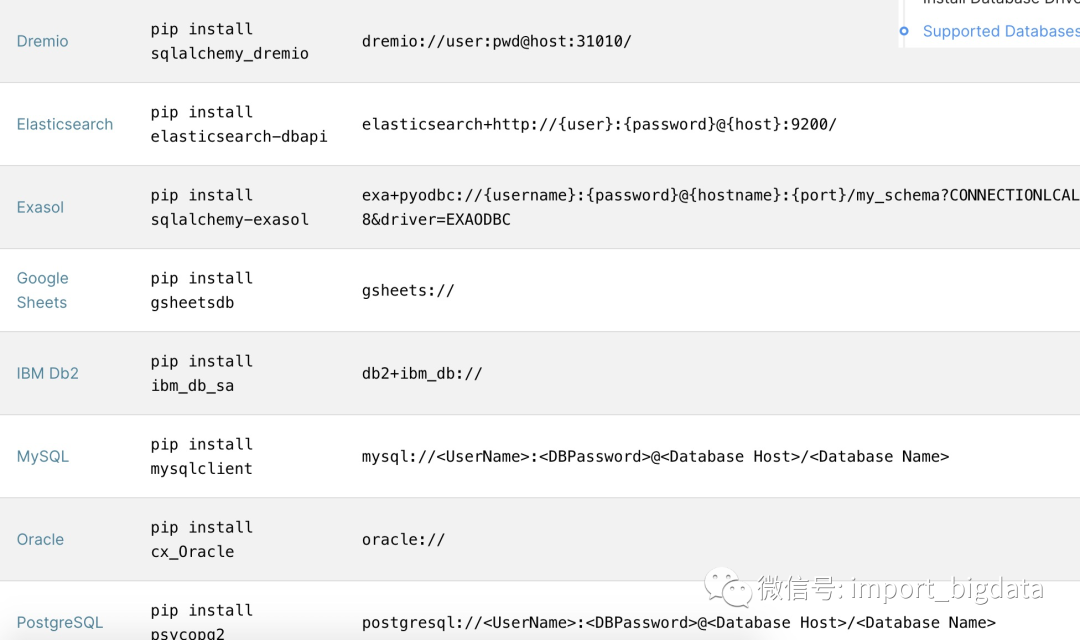
链接PostgreSQL
我们本地使用PostgreSQL进行测试,首先要安装psycopg2:
pip install psycopg2
然后就可以通过
postgresql://<UserName>:<DBPassword>@<Database Host>/<Database Name>
来链接到Superset了。
- 新增数据源
选择Source -> Databases,点击加号新增数据源:
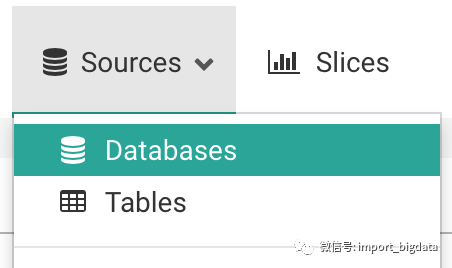
- 链接到数据库


在进行这步操作之前,小编把测试数据导入到了Postgresql中,导入方法在这里: https://github.com/dylburger/noaa-ghcn-weather-data。
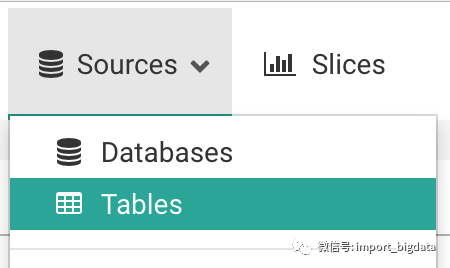
- 新建表


加好后回弹出提示:
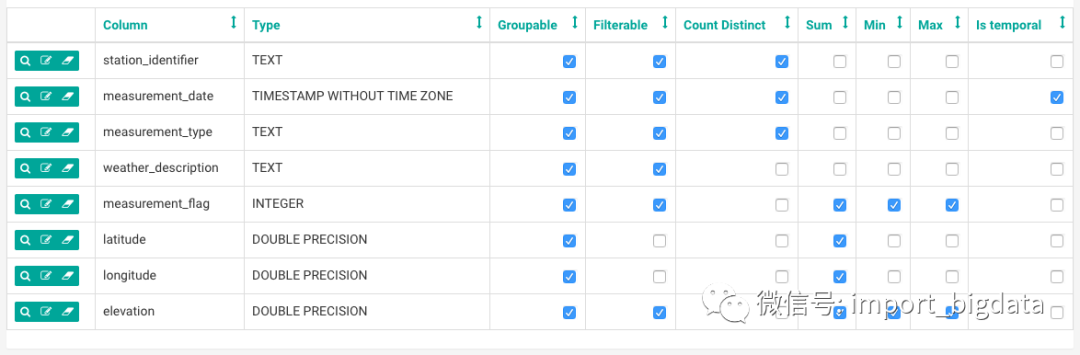
在分析页面中,可以针对某一个表事先定义的时间字段、维度及指标字段进行数据探索分析,并可以选择相应的图表进行可视化展示。
这个做法Superset应该是参考了众多中间件对数据列定义的方式,在此进行约束,哪些列可以进行聚合运算等等。
然后就是一系列的定制化操作:
- 图表类型选择
- 时间范围选择
- 计算维度选择
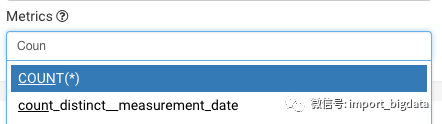
- 聚合维度选择

然后,运行我们的自定义选项:
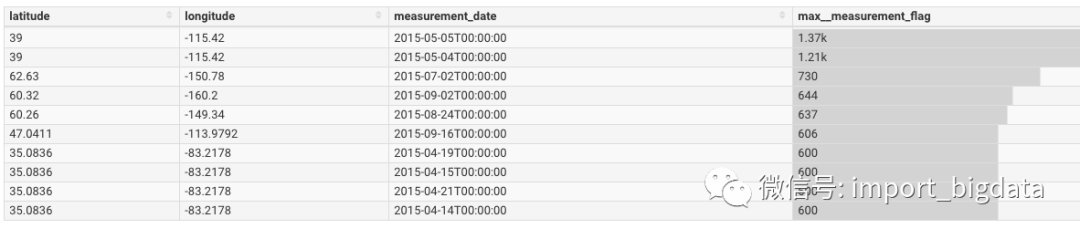
然后就可以看到展示的效果:
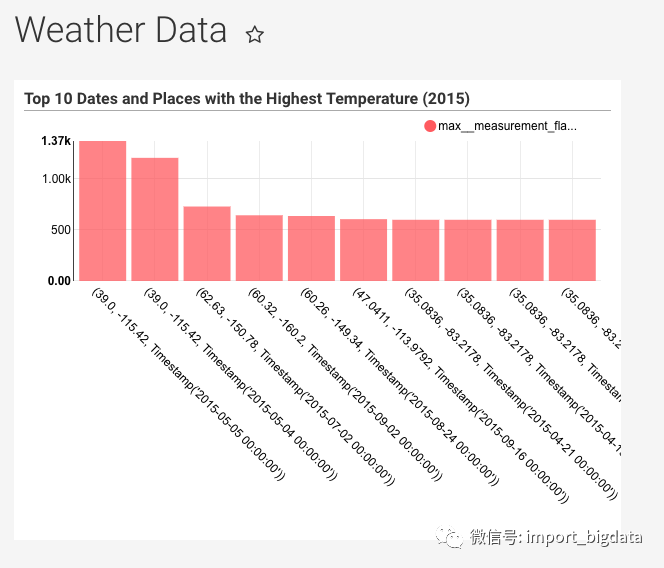
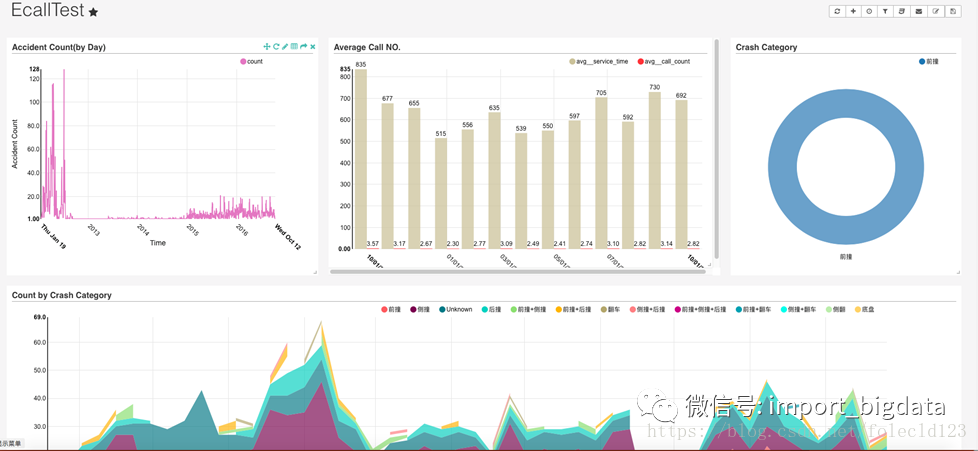
是不是非常骚气。最后我们可以把多个图表整合到Dashboards中。
Superset权限体系
Superset的权限体系是通过Flask AppBuilder (FAB)完成,Flask-AppBuilder是基于Flask实现的一个用于快速构建Web后台管理系统的简单的框架。
Superset附带一组由Superset自己处理的角色。随着Superset的发展,您可以假设这些角色将保持最新状态。不建议您通过删除或添加权限来以任何方式更改这些角色,因为在您运行下一个超级集群初始化命令时,这些角色将重新同步到其原始值。
Superset支持用户自定义创建一个角色,例如:您可以创建一个角色Financial Analyst,该角色将由一组数据源(表)和/或数据库组成。然后用户将被授予Gamma,Financial Analyst,或者sql_lab角色都可以。
Superset的默认角色有:Admin、Alpha、Gamma、sql_lab、Public,:
Admin
管理员有所有的权利,其中包括授予或撤销其他用户和改变其他人的切片和仪表板的权利。
Alpha
alpha可以访问所有数据源,但不能授予或撤消其他用户的访问权限,并且他们也只能修改自己的数据。alpha用户可以添加和修改数据源。
Gamma
Gamma访问有限。他们只能使用他们通过另一个补充角色访问的数据源中的数据。他们只能访问查看从他们有权访问的数据源制作的切片和仪表板。目前,Gamma用户无法更改或添加数据源。我们假设他们大多是内容消费者,虽然他们可以创建切片和仪表板。
还要注意,当Gamma用户查看仪表板和切片列表视图时,他们只会看到他们有权访问的对象。
sql_lab
sql_lab角色用于授予需要访问sql lab的用户,而管理员用户可以访问所有的数据库,默认情况下,Alpha和Gamma用户需要一个数据库的访问权限。
Public
允许登录用户访问一些Superset的一些功能。
使用感受
在数据可视化方向有很多与 Superset 类似的竞品,比如国外知名的开源的有 Redash 、 Metabase,商业版的有Tableau。
整体从了解Superset的背景到使用过程,小编最大的感受是:
1. 效率高、Developer Friendly(对开发者友好),适合那些需要快速支持业务的场景,尤其是BI人员看板需求。
后续再有新的发现再来告知大家,散会。

大数据可视化从未如此简单 - Apache Zepplien全面介绍
基于Prometheus+Grafana打造企业级Flink监控系统
欢迎点赞+收藏+转发朋友圈素质三连

文章不错?点个【在看】吧!****
本文分享自微信公众号 - 大数据技术与架构(import_bigdata)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。





