
什么情况下应该使用多线程 :
线程出现的目的是什么?解决进程中多任务的实时性问题?其实简单来说,也就是解决“阻塞”的问题,阻塞的意思就是程序运行到某个函数或过程后等待某些事件发生而暂时停止 CPU 占用的情况,也就是说会使得 CPU 闲置。还有一些场景就是比如对于一个函数中的运算逻辑的性能问题,我们可以通过多线程的技术,使得一个函数中的多个逻辑运算通过多线程技术达到一个并行执行,从而提升性能所以,多线程最终解决的就是“等待”的问题,所以简单总结的使用场景
Ø 通过并行计算提高程序执行性能。
Ø 需要等待网络、I/O 响应导致耗费大量的执行时间,可以采用异步线程的方式来减少阻塞。
如何应用多线程 在 Java 中,有多种方式来实现多线程。继承 Thread 类、实现 Runnable 接口、使用 ExecutorService、Callable、Future 实现带返回结果的多线程。
继承 Thread 类创建线程Thread:
类本质上是实现了 Runnable 接口的一个实例,代表一个线程的实例。启动线程的唯一方法就是通过 Thread 类的 start()实例方法。start()方法是一个native 方法,它会启动一个新线程,并执行 run()方法。这种方式实现多线程很简单,通过自己的类直接 extend Thread,并复写 run()方法,就可以启动新线程并执行自己定义的 run()方法。
public class MyThread extends Thread {
public void run() {
System.out.println("MyThread.run()");
}
}
MyThread myThread1 = new MyThread();
MyThread myThread2 = new MyThread();
myThread1.start();
myThread2.start();
实现 Runnable 接口创建线程 :
如果自己的类已经 extends 另一个类,就无法直接 extends Thread,此时,可以实现一个 Runnable 接口。
public class MyThread extends OtherClass implements Runnable {
public void run() {
System.out.println("MyThread.run()");
}
}
实现 Callable 接口通过 FutureTask 包装器来创建:
Thread 线程有的时候,我们可能需要让一步执行的线程在执行完成以后,提供一个返回值给到当前的主线程,主线程需要依赖这个值进行后续的逻辑处理,那么这个时候,就需要用到带返回值的线程了。Java 中提供了这样的实现方式。
public class CallableDemo implements Callable<String> {
public static void main(String[] args) throws ExecutionException, InterruptedException {
ExecutorService executorService=Executors.newFixedThreadPool(1);
CallableDemo callableDemo=new CallableDemo();
Future<String> future=executorService.submit(callableDemo);
System.out.println(future.get());//阻塞
executorService.shutdown();
}
@Override
public String call() throws Exception {
int a=1;
int b=2;
System.out.println(a+b);
return "执行结果:"+(a+b);
}
}
如何把多线程用得更加优雅 :合理的利用异步操作,可以大大提升程序的处理性能,下面这个案例,如果看过 zookeeper 源码的同学应该都见过通过阻塞队列以及多线程的方式,实现对请求的异步化处理,提升处理性能。接下去就模仿zk源码的实现方式,通过异步化处理实现去打印跟保存请求信息的功能:
request:(请求信息类)
public class Request {
private String name;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
@Override
public String toString() {
return "Request{" +
"name='" + name + '\'' +
'}';
}
}
RequestProcessor :(请求处理接口)
public interface RequestProcessor {
void processRequest(Request request);
}
PrintProcessor :(打印请求实现类),这里采用了链式调用的处理过程,这种方式在很多的中间件中出现过,包括activeMQ在封装请求处理的时候所用到的tcpTransport,以及zookeeper的源码中都有体现,以及在dubbo的源码中的 Cluster 最后也是采用链式封装成了一个 MockCluster进行链式处理。
public class PrintProcessor extends Thread implements RequestProcessor{
LinkedBlockingQueue<Request> requests = new LinkedBlockingQueue<Request>();
private final RequestProcessor nextProcessor;
public PrintProcessor(RequestProcessor nextProcessor) {
this.nextProcessor = nextProcessor;
}
@Override
public void run() {
while (true) {
try {
Request request=requests.take();
System.out.println("print data:"+request.getName());
nextProcessor.processRequest(request);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
//处理请求
public void processRequest(Request request) {
requests.add(request);
}
}
SaveProcessor:(保存请求信息处理类)
public class SaveProcessor extends Thread implements RequestProcessor{
LinkedBlockingQueue<Request> requests = new LinkedBlockingQueue<Request>();
@Override
public void run() {
while (true) {
try {
Request request=requests.take();
System.out.println("begin save request info:"+request);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
//处理请求
public void processRequest(Request request) {
requests.add(request);
}
}
Demo:
public class Demo {
PrintProcessor printProcessor;
protected Demo(){
SaveProcessor saveProcessor=new SaveProcessor();
saveProcessor.start();
printProcessor=new PrintProcessor(saveProcessor);
printProcessor.start();
}
private void doTest(Request request){
printProcessor.processRequest(request);
}
public static void main(String[] args) {
Request request=new Request();
request.setName("Mic");
new Demo().doTest(request);
}
}
这样就实现了一个简单的异步化的,链式调用过程,这样看起来多线程的代码显得比较优雅。
Java 并发编程的基础 :
线程作为操作系统调度的最小单元,并且能够让多线程同时执行,极大的提高了程序的性能,在多核环境下的优势更加明显。但是在使用多线程的过程中,如果对它的特性和原理不够理解的话,很容易造成各种问题。
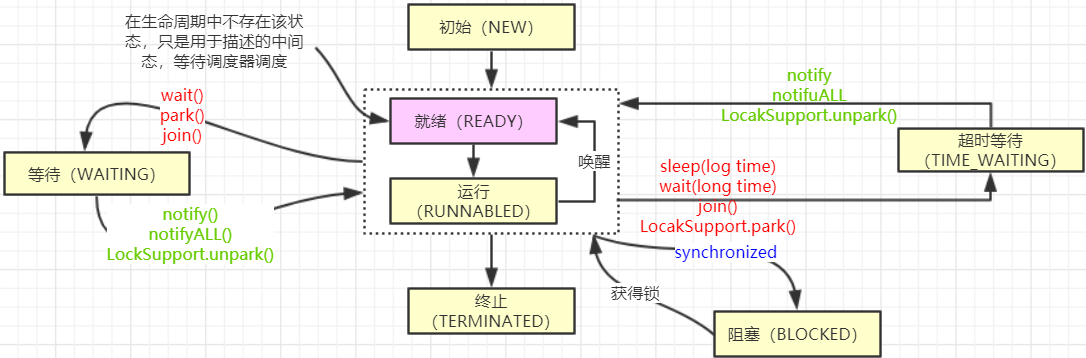
线程的状态:
Java 线程既然能够创建,那么也势必会被销毁,所以线程是存在生命周期的,那么我们接下来从线程的生命周期开始去了解线程。线程一共有 6 种状态(NEW、RUNNABLE、BLOCKED、WAITING、TIME_WAITING、TERMINATED)
NEW:初始状态,线程被构建,但是还没有调用 start 方法。
RUNNABLED:运行状态,JAVA 线程把操作系统中的就绪和运行两种状态统一称为“运行中”。
BLOCKED:阻塞状态,表示线程进入等待状态,也就是线程因为某种原因放弃了 CPU 使用权,阻塞也分为几种情况。
Ø 等待阻塞:运行的线程执行 wait 方法,jvm 会把当前线程放入到等待队列。
Ø 同步阻塞:运行的线程在获取对象的同步锁(synchronized)时,若该同步锁被其他线程锁占用了,那么 jvm 会把当前的线程放入到锁池中。
Ø 其他阻塞:运行的线程执行 Thread.sleep 或者 t.join 方法,或者发出了 I/O请求时,JVM 会把当前线程设置为阻塞状态,当 sleep 结束、join 线程终止、io 处理完毕则线程恢复。
WAITING:等待状态。
TIME_WAITING:超时等待状态,超时以后自动返回。
TERMINATED:终止状态,表示当前线程执行完毕。
通过相应命令显示线程状态 :
• 打开终端或者命令提示符,键入“jps”,(JDK1.5 提供的一个显示当前所有 java进程 pid 的命令),可以获得相应进程的 pid
• 根据上一步骤获得的 pid,继续输入 jstack pid(jstack 是 java 虚拟机自带的一种堆栈跟踪工具。jstack 用于打印出给定的 java 进程 ID 或 core file 或远程调试服务的 Java 堆栈信息)
线程的停止 :
线程的终止,并不是简单的调用 stop 命令去。虽然 api 仍然可以调用,但是和其他的线程控制方法如 Thread.currentThread.suspend(类似linux的kill,暴力)、thread.resume() 一样都是过期了的不建议使用,就拿 stop 来说,stop 方法在结束一个线程时并不会保证线程的资源正常释放,因此会导致程序可能出现一些不确定的状态。要优雅的去中断一个线程,在线程中提供了一个 interrupt 方法.或者通过成员变量:volatile boolean isStop,这样的判断。
interrupt 方法 :
当其他线程通过调用当前线程的 interrupt 方法,表示向当前线程打个招呼,告诉他可以中断线程的执行了,至于什么时候中断,取决于当前线程自己。线程通过检查资深是否被中断来进行相应,可以通过 isInterrupted()来判断是否被中断。通过下面这个例子,来实现了线程终止的逻辑。
public class InterruptDemo {
private static int i;
public static void main(String[] args) throws InterruptedException {
Thread thread=new Thread(()->{
while(!Thread.currentThread().isInterrupted()){
i++;
}
System.out.println("Num:"+i);
},"interruptDemo");
thread.start();
TimeUnit.SECONDS.sleep(1);
thread.interrupt();
}
}
这种通过标识位或者中断操作的方式能够使线程在终止时有机会去清理资源,而不是武断地将线程停止,因此这种终止线程的做法显得更加安全和优雅。
上面的案例中,通过 interrupt,设置了一个标识告诉线程可以终止了,线程中还提供了静态方法 Thread.interrupted()对设置中断标识的线程复位。比如在上面的案例中,外面的线程调用 thread.interrupt 来设置中断标识,而在线程里面,又通过 Thread.interrupted 把线程的标识又进行了复位。
public class InterruptDemo {
public static void main(String[] args) throws InterruptedException{
Thread thread=new Thread(()->{
while(true){
boolean ii=Thread.currentThread().isInterrupted();
if(ii){
System.out.println("before:"+ii);
Thread.interrupted();//对线程进行复位,中断标识为 false
System.out.println("after:"+Thread.currentThread().isInterrupted());
}
}
});
thread.start();
TimeUnit.SECONDS.sleep(1);
thread.interrupt();//设置中断标识,中断标识为 true
}
}
其他的线程复位
除了通过 Thread.interrupted 方法对线程中断标识进行复位以外,还有一种被动复位的场景,就是对抛出 InterruptedException 异常的方法,在InterruptedException 抛出之前,JVM 会先把线程的中断标识位清除,然后才会抛出 InterruptedException,这个时候如果调用 isInterrupted 方法,将会返回 false。
线程的安全性问题 :
大家都知道,线程会存在安全性问题,其实线程安全问题可以总结为: 可见性、原子性、有序性这几个问题。
可见性:以下demo就是说明了一个可见性的问题,此情况下主线程修改了线程终止标识变量,可是thread线程无从得知,一直认为该值是false,造成线程进入死循环。需要对变量 stop添加 volatile解决。
public class visibleDemo {
private static boolean stop = false;
public static void main(String[] args) throws InterruptedException {
Thread thread =new Thread(()-> {
int i=0;
while(!stop) {
i++;
}
});
thread.start();
TimeUnit.SECONDS.sleep(1);
stop =true;
}
}
原子性:以下案例循环1000次所得到的结果理论上会等于1000,可是实际会小于。这就是操作的原子性问题,比如两个线程同时拿到这个 i 的值,此刻值为100,线程1 增加1以后把值设置回去为101,而此刻线程2继线程1以后又把自己增加以后的值又放回去了,此刻还是101.
public class AtomicDemo {
private static int count =0;
public static void inc() {
try {
Thread.sleep(1);
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
count ++;
}
public static void main(String[] args) throws InterruptedException {
for(int i=0;i<1000;i++) {
new Thread(AtomicDemo::inc).start();
}
Thread.sleep(4000);
System.out.println("运行结果:"+count);
}
}
顺序性:顺序性问题无法演示,是由于编译期间CPU在不影响程序结果的时候,对于代码指令进行优化重排序,导致代码运行顺序与编写时的不一致。
CPU 高速缓存 :
线程是 CPU 调度的最小单元,线程涉及的目的最终仍然是更充分的利用计算机处理的效能,但是绝大部分的运算任务不能只依靠处理器“计算”就能完成,处理器还需要与内存交互,比如读取运算数据、存储运算结果,这个 I/O 操作是很难消除的。而由于计算机的存储设备与处理器的运算速度差距非常大,所以现代计算机系统都会增加一层读写速度尽可能接近处理器运算速度的高速缓存来作为内存和处理器之间的缓冲:将运算需要使用的数据复制到缓存中,让运算能快速进行,当运算结束后再从缓存同步到内存之中。
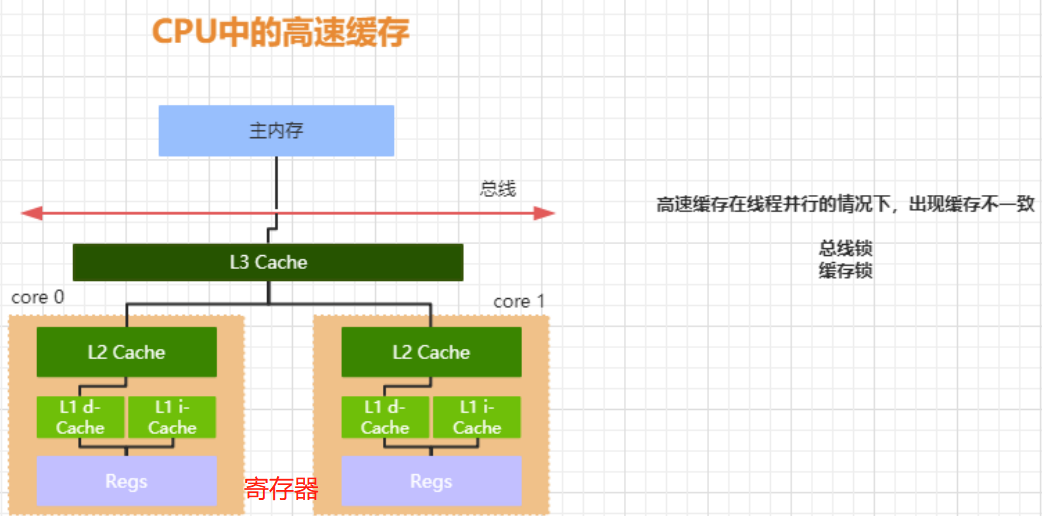
高速缓存从下到上越接近 CPU 速度越快,同时容量也越小。现在大部分的处理器都有二级或者三级缓存,从下到上依次为 L3 cache, L2 cache, L1 cache. 缓存又可以分为指令缓存和数据缓存,指令缓存用来缓存程序的代码,数据缓存用来缓存程序的数据:
L1 Cache,一级缓存,本地 core(CPU) 的缓存,分成 32K 的数据缓存 L1d 和 32k 指令缓存 L1i,访问 L1 需要 3cycles,耗时大约 1ns;
L2 Cache,二级缓存,本地 core 的缓存,被设计为 L1 缓存与共享的 L3 缓存之间的缓冲,大小为 256K,访问 L2 需要 12cycles,耗时大约 3ns;
L3 Cache,三级缓存,在同插槽的所有 core 共享 L3 缓存,分为多个 2M 的段,访问 L3 需要 38cycles,耗时大约 12ns;
缓存一致性问题 :
CPU-0 读取主存的数据,缓存到 CPU-0 的高速缓存中,CPU-1 也做了同样的事情,而 CPU-1 把 count 的值修改成了 2,并且同步到 CPU-1 的高速缓存,但是这个修改以后的值并没有写入到主存中,CPU-0 访问该字节,由于缓存没有更新,所以仍然是之前的值,就会导致数据不一致的问题,从而引发原子性问题。引发这个问题的原因是因为多核心 CPU 情况下存在指令并行执行,而各个CPU 核心之间的数据不共享从而导致缓存一致性问题,这也是从硬件层面所导致的数据的可见性问题,为了解决这个问题,CPU 生产厂商提供了相应的解决方案
总线锁 :
当一个 CPU 对其缓存中的数据进行操作的时候,往总线中发送一个 Lock 信号。其他处理器的请求将会被阻塞,那么该处理器可以独占共享内存。总线锁相当于把 CPU 和内存之间的通信锁住了,所以这种方式会导致 CPU 的性能下降,所以 P6 系列以后的处理器,出现了另外一种方式,就是缓存锁。
缓存锁 :
如果缓存在处理器缓存行中的内存区域在 LOCK 操作期间被锁定,当它执行锁操作回写内存时,处理不在总线上声明 LOCK 信号,而是修改内部的缓存地址,然后通过缓存一致性机制来保证操作的原子性,因为缓存一致性机制会阻止同时修改被两个以上处理器缓存的内存区域的数据,当其他处理器回写已经被锁定的缓存行的数据时会导致该缓存行无效。所以如果声明了 CPU 的锁机制,会生成一个 LOCK 指令,会产生两个作用
1. Lock 前缀指令会引起引起处理器缓存回写到内存,在 P6 以后的处理器中,LOCK 信号一般不锁总线,而是锁缓存
2. 一个处理器的缓存回写到内存会导致其他处理器的缓存无效
缓存一致性协议 :
处理器上有一套完整的协议,来保证 Cache 的一致性,比较经典的应该就是MESI 协议了,它的方法是在 CPU 缓存中保存一个标记位,这个标记为有四种状态
Ø M(Modified) 修改缓存,当前 CPU 缓存已经被修改,表示已经和内存中的数据不一致了
Ø I(Invalid) 失效缓存,说明 CPU 的缓存已经不能使用了
Ø E(Exclusive) 独占缓存,当前 cpu 的缓存和内存中数据保持一直,而且其他处理器没有缓存该数据
Ø S(Shared) 共享缓存,数据和内存中数据一致,并且该数据存在多个 cpu缓存中每个 Core 的 Cache 控制器不仅知道自己的读写操作,也监听其它 Cache 的读写操作,嗅探(snooping)"协议
CPU 的读取会遵循几个原则:
1. 如果缓存的状态是 I,那么就从内存中读取,否则直接从缓存读取
2. 如果缓存处于 M 或者 E 的 CPU 嗅探到其他 CPU 有读的操作,就把自己的缓存写入到内存,并把自己的状态设置为 S
3. 只有缓存状态是 M 或 E 的时候,CPU 才可以修改缓存中的数据,修改后,缓存状态变为 M
CPU 的优化执行 :
除了增加高速缓存以外,为了更充分利用处理器内内部的运算单元,处理器可能会对输入的代码进行乱序执行优化,处理器会在计算之后将乱序执行的结果充足,保证该结果与顺序执行的结果一直,但并不保证程序中各个语句计算的先后顺序与输入代码中的顺序一致,这个是处理器的优化执行;还有一个就是编程语言的编译器也会有类似的优化,比如做指令重排来提升性能。
其实原子性、可见性、有序性问题,是我们抽象出来的概念,他们的核心本质就是上面提到的缓存一致性问题、处理器优化问题导致的指令重排序问题。比如缓存一致性就导致可见性问题、处理器的乱序执行会导致原子性问题、指令重排会导致有序性问题。为了解决这些问题,所以在 JVM 中引入了 JMM 的概念。
Java Memory Model 内存模型 :
内存模型定义了共享内存系统中多线程程序读写操作行为的规范,来屏蔽各种硬件和操作系统的内存访问差异,来实现 Java 程序在各个平台下都能达到一致的内存访问效果。Java 内存模型的主要目标是定义程序中各个变量的访问规则,也就是在虚拟机中将变量存储到内存以及从内存中取出变量(这里的变量,指的是共享变量,也就是实例对象、静态字段、数组对象等存储在堆内存中的变量。而对于局部变量这类的,属于线程私有,不会被共享)。通过这些规则来规范对内存的读写操作,从而保证指令执行的正确性。它与处理器有关、与缓存有关、与并发有关、与编译器也有关。他解决了 CPU多级缓存、处理器优化、指令重排等导致的内存访问问题,保证了并发场景下的可见性、原子性和有序性,。内存模型解决并发问题主要采用两种方式:限制处理器优化和使用内存屏障。
Java 内存模型定义了线程和内存的交互方式,在 JMM 抽象模型中,分为主内存、工作内存。主内存是所有线程共享的,工作内存是每个线程独有的。线程对变量的所有操作(读取、赋值)都必须在工作内存中进行,不能直接读写主内存中的变量。并且不同的线程之间无法访问对方工作内存中的变量,线程间的变量值的传递都需要通过主内存来完成,他们三者的交互关系如下:
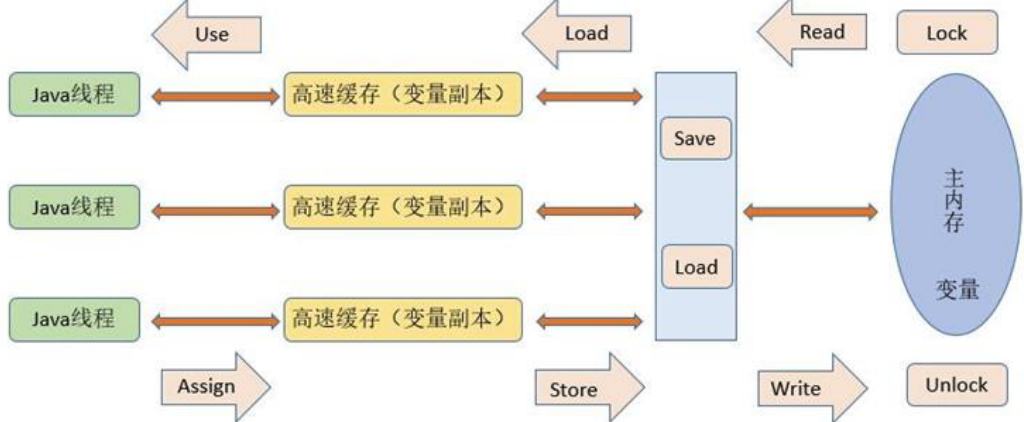
所以,总的来说,JMM 是一种规范,目的是解决由于多线程通过共享内存进行通信时,存在的本地内存数据不一致、编译器会对代码指令重排序、处理器会对代码乱序执行等带来的问题。目的是保证并发编程场景中的原子性、可见性和有序性。
JMM怎么解决原子性、可见性、有序性的问题?
在Java中提供了一系列和并发处理相关的关键字,比如volatile、Synchronized、final、juc(java.util.concurrent)等,这些就是Java内存模型封装了底层的实现后提供给开发人员使用的关键字,在开发多线程代码的时候,我们可以直接使用synchronized等关键词来控制并发,使得我们不需要关心底层的编译器优化、缓存一致性的问题了,所以在Java内存模型中,除了定义了一套规范,还提供了开放的指令在底层进行封装后,提供给开发人员使用。
原子性保障:在java中提供了两个高级的字节码指令monitorenter和monitorexit,在Java中对应的Synchronized来保证代码块内的操作是原子的
可见性:Java中的volatile关键字提供了一个功能,那就是被其修饰的变量在被修改后可以立即同步到主内存,被其修饰的变量在每次是用之前都从主内存刷新。因此,可以使用volatile来保证多线程操作时变量的可见性。除了volatile,Java中的synchronized和final两个关键字也可以实现可见性
有序性:在Java中,可以使用synchronized和volatile来保证多线程之间操作的有序性。实现方式有所区别:volatile关键字会禁止指令重排。synchronized关键字保证同一时刻只允许一条线程操作。
volatile如何保证可见性
下载hsdis工具 ,https://sourceforge.net/projects/fcml/files/fcml-1.1.1/hsdis-1.1.1-win32-amd64.zip/download 解压后存放到jre目录的server路径下:

由于我这边使用的是 STS 工具,需要如下配置:run-> run configurations-> argments 加入-XX:+UnlockDiagnosticVMOptions -XX:+PrintAssembly
然后用一个简单的例子来看一下这段程序所形成的汇编语言中的差别:
public class ThreadDemo {
private static volatile ThreadDemo instance=null;
public static synchronized ThreadDemo getInstance() {
if(instance ==null ) {
instance =new ThreadDemo();
}
return instance;
}
public static void main(String[] args) {
ThreadDemo.getInstance();
}
}
可以看到本段示例中成员变量添加了 volatile 关键字,来看看他的汇编语言中最重要的一段:

当不添加 volatile 关键字的时候,会发现搜索 lock 指令已经搜索不出来了。
volatile变量修饰的共享变量,在进行写操作的时候会多出一个 lock前缀的汇编指令,这个指令在前面CPU高速缓存的时候提到过,会触发总线锁或者缓存锁,通过缓存一致性协议来解决可见性问题,对于声明了volatile的变量进行写操作,JVM就会向处理器发送一条Lock前缀的指令,把这个变量所在的缓存行的数据写回到系统内存,再根据我们前面提到过的MESI的缓存一致性协议,来保证多CPU下的各个高速缓存中的数据的一致性。
volatile防止指令重排序:
指令重排的目的是为了最大化的提高CPU利用率以及性能,CPU的乱序执行优化在单核时代并不影响正确性,但是在多核时代的多线程能够在不同的核心上实现真正的并行,一旦线程之间共享数据,就可能会出现一些不可预料的问题,指令重排序必须要遵循的原则是,不影响代码执行的最终结果,编译器和处理器不会改变存在数据依赖关系的两个操作的执行顺序,(这里所说的数据依赖性仅仅是针对单个处理器中执行的指令和单个线程中执行的操作.)这个语义,实际上就是as-if-serial语义,不管怎么重排序,单线程程序的执行结果不会改变,编译器、处理器都必须遵守as-if-serial语义。
多核心多线程下的指令重排影响:
private static int x = 0, y = 0;
private static int a = 0, b = 0;
public static void main(String[] args) throws InterruptedException {
Thread t1 = new Thread(() -> {
a = 1;
x = b;
});
Thread t2 = new Thread(() -> {
b = 1;
y = a;
});
t1.start();
t2.start();
t1.join();
t2.join();
System.out.println("x=" + x + "->y=" + y);
}
如果不考虑编译器重排序和缓存可见性问题,上面这段代码可能会出现的结果是 x=0,y=1; x=1,y=0; x=1,y=1这三种结果,因为可能是先后执行t1/t2,也可能是反过来,还可能是t1/t2交替执行,但是这段代码的执行结果也有可能是x=0,y=0。这就是在乱序执行的情况下会导致的一种结果,因为线程t1内部的两行代码之间不存在数据依赖,因此可以把x=b乱序到a=1之前;同时线程t2中的y=a也可以早于t1中的a=1执行,那么他们的执行顺序可能是
l t1: x=b
l t2:b=1
l t2:y=a
l t1:a=1
所以从上面的例子来看,重排序会导致可见性问题。但是重排序带来的问题的严重性远远大于可见性,因为并不是所有指令都是简单的读或写,比如DCL的部分初始化问题。所以单纯的解决可见性问题还不够,还需要解决处理器重排序问题。
内存屏障:
内存屏障需要解决我们前面提到的两个问题,一个是编译器的优化乱序和CPU的执行乱序,我们可以分别使用优化屏障和内存屏障这两个机制来解决。
**从CPU层面来了解一下什么是内存屏障:
**
CPU的乱序执行,本质还是,由于在多CPU的机器上,每个CPU都存在cache,当一个特定数据第一次被特定一个CPU获取时,由于在该CPU缓存中不存在,就会从内存中去获取,被加载到CPU高速缓存中后就能从缓存中快速访问。当某个CPU进行写操作时,它必须确保其他的CPU已经将这个数据从他们的缓存中移除,这样才能让其他CPU安全的修改数据。显然,存在多个cache时,我们必须通过一个cache一致性协议来避免数据不一致的问题,而这个通讯的过程就可能导致乱序访问的问题,也就是运行时的内存乱序访问。现在的CPU架构都提供了内存屏障功能,在x86的cpu中,实现了相应的内存屏障写屏障(store barrier)、读屏障(load barrier)和全屏障(Full Barrier),主要的作用是
Ø 防止指令之间的重排序
Ø 保证数据的可见性
store barrier:
store barrier称为写屏障,相当于storestore barrier, 强制所有在storestore内存屏障之前的所有执行,都要在该内存屏障之前执行,并发送缓存失效的信号。所有在storestore barrier指令之后的store指令,都必须在storestore barrier屏障之前的指令执行完后再被执行。也就是进制了写屏障前后的指令进行重排序,是的所有store barrier之前发生的内存更新都是可见的(这里的可见指的是修改值可见以及操作结果可见)。
load barrier:
load barrier称为读屏障,相当于loadload barrier,强制所有在load barrier读屏障之后的load指令,都在loadbarrier屏障之后执行。也就是进制对load barrier读屏障前后的load指令进行重排序, 配合store barrier,使得所有store barrier之前发生的内存更新,对load barrier之后的load操作是可见的
Full barrier:
full barrier成为全屏障,相当于storeload,是一个全能型的屏障,因为它同时具备前面两种屏障的效果。强制了所有在storeload barrier之前的store/load指令,都在该屏障之前被执行,所有在该屏障之后的的store/load指令,都在该屏障之后被执行。禁止对storeload屏障前后的指令进行重排序。
总结:内存屏障只是解决顺序一致性问题,不解决缓存一致性问题,缓存一致性是由cpu的缓存锁以及MESI协议来完成的。而缓存一致性协议只关心缓存一致性,不关心顺序一致性。所以这是两个问题。
编译器层面如何解决指令重排序问题:
在编译器层面,通过volatile关键字,取消编译器层面的缓存和重排序。保证编译程序时在优化屏障之前的指令不会在优化屏障之后执行。这就保证了编译时期的优化不会影响到实际代码逻辑顺序。如果硬件架构本身已经保证了内存可见性,那么volatile就是一个空标记,不会插入相关语义的内存屏障。如果硬件架构本身不进行处理器重排序,有更强的重排序语义,那么volatile就是一个空标记,不会插入相关语义的内存屏障。在JMM中把内存屏障指令分为4类,通过在不同的语义下使用不同的内存屏障来进制特定类型的处理器重排序,从而来保证内存的可见性:
LoadLoad Barriers, load1 ; LoadLoad; load2 , 确保load1数据的装载优先于load2及所有后续装载指令的装载
StoreStore Barriers,store1; storestore;store2 , 确保store1数据对其他处理器可见优先于store2及所有后续存储指令的存储
LoadStore Barries, load1;loadstore;store2, 确保load1数据装载优先于store2以及后续的存储指令刷新到内存
StoreLoad Barries, store1; storeload;load2, 确保store1数据对其他处理器变得可见, 优先于load2及所有后续装载指令的装载;这条内存屏障指令是一个全能型的屏障,在前面讲cpu层面的内存屏障的时候有提到。它同时具有其他3条屏障的效果。
我们可以通过 JVM源码来看一下这个所谓的 Barriers 。首先搞一个非常简单的demo:
public class Demo {
static volatile int i;
public static void main(String[] args) {
i=10;
}
}
然后通过javap -c Demo.class,去查看字节码(如果没.class,先编译):

会发现这里有一个 ACC_VOLATILE,当把代码中的 volatile 关键字拿掉以后就没有这东西了。所以我们通过这个差异去源码中寻找。导入JVM源码全局搜索这个东西,最后会在 accessFlags.hpp 这个文件中找到如下代码:这里定义了java中所有的关键字信息,我们从其中看到了刚刚在字节码中出现的ACC_VOLATILE,这里定义了一个方法 is_volatile();
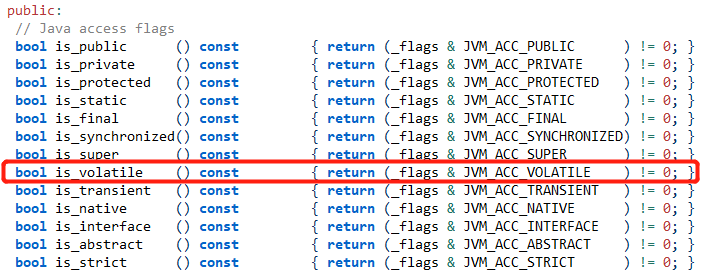
全局搜索 is_volatile 方法,会在 bytecodeInterpreter.cpp 文件中找到该方法:
// 存储值
// Now store the result
//
int field_offset = cache->f2_as_index();
if (cache->is_volatile()) { // 判断是否存在 volatile关键字
if (tos_type == itos) {
obj->release_int_field_put(field_offset, STACK_INT(-1));
} else if (tos_type == atos) {
VERIFY_OOP(STACK_OBJECT(-1));
obj->release_obj_field_put(field_offset, STACK_OBJECT(-1));
OrderAccess::release_store(&BYTE_MAP_BASE[(uintptr_t)obj >> CardTableModRefBS::card_shift], 0);
} else if (tos_type == btos) {
obj->release_byte_field_put(field_offset, STACK_INT(-1));
} else if (tos_type == ltos) {
obj->release_long_field_put(field_offset, STACK_LONG(-1));
} else if (tos_type == ctos) {
obj->release_char_field_put(field_offset, STACK_INT(-1));
} else if (tos_type == stos) {
obj->release_short_field_put(field_offset, STACK_INT(-1));
} else if (tos_type == ftos) {
obj->release_float_field_put(field_offset, STACK_FLOAT(-1));
} else {
obj->release_double_field_put(field_offset, STACK_DOUBLE(-1));
}
OrderAccess::storeload();//加入屏障
} else { ......
这里判断了是否 volatile 进行了修饰,再判断该变量的类型,我们的 demo里面是个int,所以他会调用 release_int_field_put() 这个方法,最后为该操作添加了一个storeload 屏障。这个屏障的作用上面有说到了。搜索到在 oop.inline.hpp 文件中。
inline jint oopDesc::int_field_acquire(int offset) const{
return OrderAccess::load_acquire(int_field_addr(offset));
}
inline void oopDesc::release_int_field_put(int offset, jint contents){
OrderAccess::release_store(int_field_addr(offset), contents);
}
继而调用 OrderAccess::release_store 来执行,在orderAccess.hpp 文件中:
static void release_store(volatile jubyte* p, jubyte v);
在这里的 volatile 已经不在是 java 语言中的含义了,这里的volatile在 c++中的意思理解为语言级别的内存屏障。volatile 指出 i 是随时可能发生变化的,每次使用它的时候必须从 i的地址中读取。不会去做代码优化,比如说指令重排序。强制对缓存的修改,立即写入到主内存,如果是写操作会导致其他缓存失效。其中有几个规则来防止指令重排序:
1.对每个 volatile 写操作的前面会插入 storestore barrier
2.对每个 volatile 写操作的后面会插入 storeload barrier
3.对每个 volatile 读操作的前面会插入 loadloadbarrier
4.对每个 volatile 读操作的后面会插入 loadstore barrier
可以发现该方法在本类中并没有实现,这里的实现是根据运行环境的操作系统来决定的,这也正是JVM为什么能一次编写到处运行的原因之一哦。可以在源码包中的 hotspot/src/os_cpu中找到:
在源码的最开始的 bytecodeInterpreter.cpp 文件所操作的方法最后是执行了一个 OrderAccess::storeload() 来添加屏障。对应是实现以 linux_x86 为例 是在 orderAccess_linux_x86.inline.hpp文件中:我们发现了 4种屏障指令 都在这里了。而storeload 继续调用了 fence() 方法
// Implementation of class OrderAccess.
inline void OrderAccess::loadload() { acquire(); }
inline void OrderAccess::storestore() { release(); }
inline void OrderAccess::loadstore() { acquire(); }
inline void OrderAccess::storeload() { fence(); }
fence() 方法:该方法加入了个汇编指令 “lock” ,这个指令似曾相识啊?也就是上面 volatile怎么解决可见性的问题终提到的查看汇编指令中lock 的来源,从而解决缓存一致性协议来解决可见性问题。
inline void OrderAccess::fence() {
if (os::is_MP()) {
// always use locked addl since mfence is sometimes expensive
#ifdef AMD64// 这里的volatile是禁止编译器对代码的优化重排序
__asm__ volatile ("lock; addl $0,0(%%rsp)" : : : "cc", "memory");
#else
__asm__ volatile ("lock; addl $0,0(%%esp)" : : : "cc", "memory");
#endif
}
}
volatile 可以保证可见性以及避免指令重排序带来的问题,但是它无法保证在多线程环境下程序的并行执行,内存屏障无法保证屏障前后的程序执行过程中没有其他线程对某个变量的修改操作。比如一个 i++ 操作,对一个原子递增的操作,是一个符合操作,会分为三个步骤:1.读取volatile变量的值到local;2.增加变量的值;3.把local的值写回让其他线程可见,但是在store之前,其他线程拿到的是旧的值去加1,这就是它不能保证原子性的原因。这里需要利用另外一个关键字来解决该问题:synchronized。












