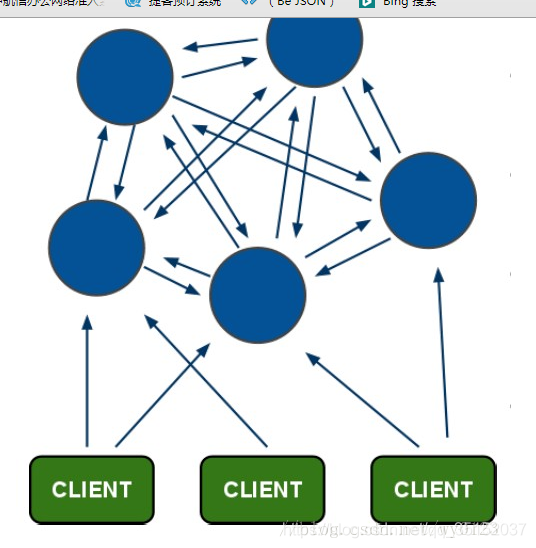
创建一个RedisCluster之前,我们需要有一些以cluster模式运行的Redis实例,这是因为cluster模式下Redis实例将会开启cluster的特征和命令。
现在我有2台Vbox搭建的CentOS6虚拟机【CentOS1(192.168.56.101)和CentOS2(192.168.56.102)】,准备在此上搭建Redis集群。
由于最小的Redis集群需要3个Master节点,本次测试使用另外3个节点作为备份的节点(Replicas),于是此次搭建需要6个Redis实例。由于可在同一台机器上运行多个Redis实例,因此我将在CentOS1上运行以下实例:
192.168.56.101:7000
192.168.56.101:7001
192.168.56.101:7002
并在CentOS2上运行以下实例:
192.168.56.102:7003
192.168.56.102:7004
192.168.56.102:7005
1. 下载Redis,目前的stable版本为3.0.6:
2. 安装Redis
tar zxvf redis-3.0.6.tar.gz
cd redis-3.0.6
make
安装完成后,redis-3.0.6/src文件夹下会出现redis-server、redis-cli等可执行文件,稍后将使用。
3. 修改配置文件
由于需要在CentOS1上运行多个实例,为了便于管理,在CentOS1上建立/home/user/Software/redis-cluster文件夹,并分别创建7000、7001和7002这三个子文件夹:

然后分别拷贝redis-3.0.6/redis.conf到这三个子文件夹中。redis.conf是redis服务器启动的必要配置文件,分别在这几个文件夹中打开该文件,修改以下选项(这几个选项是搭建Redis集群的必须选项),其它的保持默认即可:
#注意每个子文件夹下的配置中,端口号不同
port 7000
cluster-enabled yes
cluster-config-file nodes.conf
cluster-node-timeout 5000
appendonly yes
在redis.conf中,有对这些选项的详细说明,这里不赘述。
最后拷贝redis-3.0.6/src/redis-server文件到这几个子文件夹中。
4. 启动Redis
在这3个文件夹中分别启动Redis:
./redis-server redis.conf
可以通过进程命令来查看启动结果
从每个实例的启动日志(redis.conf文件中的logfile选项可以配置日志文件)中,可以看到每一个节点都给自己分配了一个新的ID:
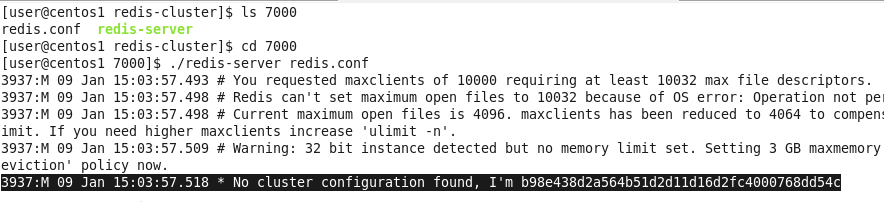
这个ID将被该Redis实例作为集群中的唯一名字永久使用,节点之间会互相记住这个名字。
5. 创建集群
在创建Redis集群前,在CentOS2机器中也需要按照步骤1~4完成相应的配置并运行Redis实例。
现在CentOS1上的3个Redis实例和CentOS2上的3个Redis实例都已经启动。目前这些实例虽然都开启了cluster模式,但是彼此还不认识对方,接下来可以通过Redis集群的命令行工具redis-trib.rb来完成集群创建。redis-trib.rb是一个Ruby写的可执行程序,它可以完成创建集群、为已存在的集群重新分片等功能。
而要想运行ruby程序,则需要系统先安装ruby运行环境:
sudo yum install ruby
接下来运行以下命令(在CentOS1和CentOS2上运行均可):
./redis-trib.rb create --replicas 1 \
192.168.56.101:7000 192.168.56.101:7001 192.168.56.101:7002 \
192.168.56.102:7003 192.168.56.102:7004 192.168.56.102:7005
此时会遇到以下问题:

提示缺少rubygems组件,可以使用yum来安装该组件:
sudo yum -y install rubygems
再次运行创建Redis集群的命令,还会报以下错误:
/usr/lib/ruby/site_ruby/1.8/rubygems/custom_require.rb:31:in `gem_original_require': no such file to load -- redis (LoadError)
from /usr/lib/ruby/site_ruby/1.8/rubygems/custom_require.rb:31:in `require'
from ./redis-trib.rb:25
搜索了一下,是因为缺少redis的ruby接口,可以通过以下命令安装:
sudo gem install redis
如果安装时出现错误,也可以下载文件后进行离线安装,下载地址:http://rubygems.org/gems/redis/versions,选择合适的版本,然后安装:
sudo gem install -l /mnt/Share/redis-3.0.6.gem
接下来再次运行创建Redis集群的命令:
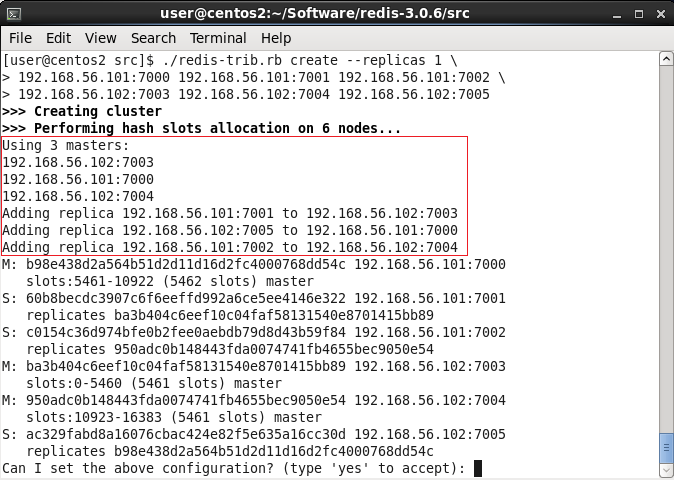
上图中:
create为redis-trib.rb脚本的子命令,表示创建redis集群
--replicas 1表示创建的集群有1套数据备份
后面的参数为多个redis实例地址,表示使用那些实例来创建节点
左边的“M:”表示该节点是master节点,相应的“S:”表示该节点为slave节点
在本次测试中,有7000~7005共6个节点,有一组节点是备份,那么很显然会有3个master和3个replica,这正好符合一开始的要求。从上图中可以看到,端口号为7000、7003和7004的三个节点被选为master,另外三个节点则成为replica。而下图则展示了redis的16384个数据槽(data slot)在三个master节点上的分布情况:
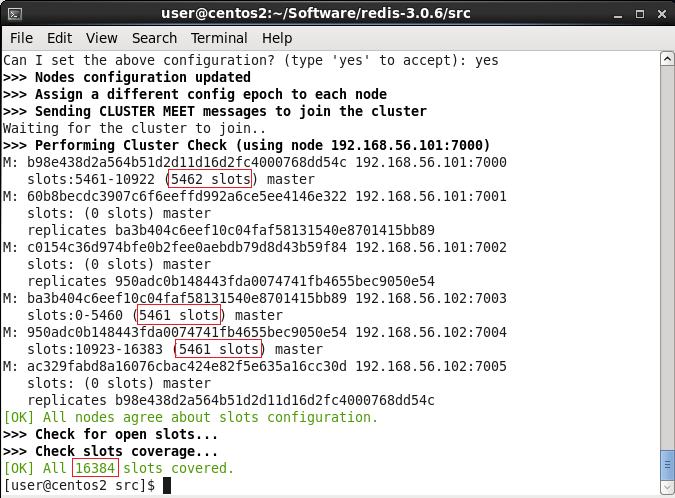
6. 测试集群
redis目前的客户端实现并不多,接下来我们用自带的redis-cli工具来测试搭建好的集群。
最简单的测试集群是使用redis-cli连接上redis后使用cluster命令(更多命令请参见:http://redis.io/commands):
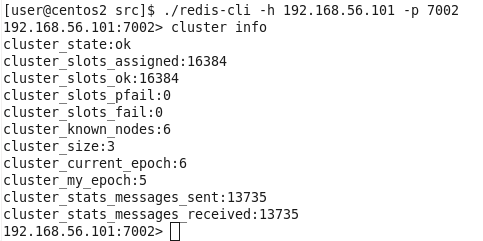
cluster info,查看集群信息:
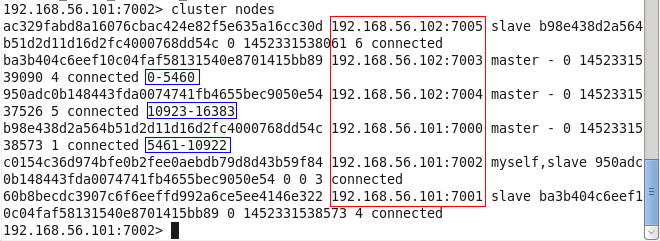
cluster nodes:查看集群中的节点信息:
下面使用redis-cli工具进行数据的读写操作:
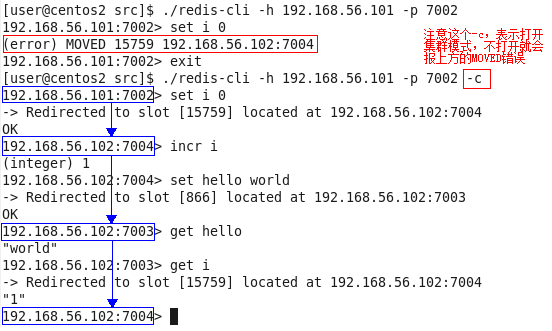
开始连接redis的时候没有加入-c选项,则只能在该节点上存取,举个例子:上图中一开始我登录的是7002端口的redis实例,然后
set i 0
这一句给i设置值为0,经集群计算后,这个i应该落在15759这个slot中,这个slot又在7004这个redis实例上,于是准备跳转到7004的redis实例上,由于没有开启集群模式,这次跳转失败了,值也就没有写进redis。
第二次连接的还是7002,但这一次使用-c选项打开了集群模式,后续的存取不管落在哪一个节点上,都能跳转过去并正确的读写。蓝色方框的变化展示了连接跳转的过程,redis集群中的读写都会发生在指定的slot上,因此都会发生相应的跳转。
另外,由于每个节点都会记住集群中其他节点的名字以及数据槽的分布情况,我们可以打开每个redis实例的文件夹查看其nodes.conf(redis.conf文件中的cluster-config-file选项来配置)文件,文件内容大致相同,仅仅是节点列表的顺序不同而已。
参考页面:
http://redis.io/topics/cluster-tutorial