
提到天猫双十一,一分钟破百亿的成交额,你肯定不会陌生,他的背后就是一套强大的流计算引擎在支撑,以便得到实时统计结果。面对日益增长的数据规模,以及越来越低时延的数据处理需求,流处理已成为每家公司数据平台的必备能力。
目前主流的流计算技术有 Apache Storm,Spark Streaming 和 Apache Flink,但真正能同时做到低时延、Exactly-Once 数据一致性保障及高吞吐的,只有 Flink 一个。而且,Flink 同时支持流处理和批处理,解决了用批来模拟流的技术局限性。
所以, 如果你要掌握未来大数据领域前瞻性技术,Flink 就是首选。
但是,Flink 的上手门槛比较高,API 不够直观和好用,不同使用模式的体验也不尽相同。所以,要真正掌握 Flink 并没有那么简单,比如:
长期做 Hive 或 Spark 等大数据项目的开发,但不知道如何用流数据处理;
遇到 Watermark 水印概念,不知道怎样用它来处理延时数据;
离线任务完成后的一段时间,Web 端没有显示或自动消失了;
Flink 集群搭建在 Yarn 上,如何实现高可用才能确保集群运行正常,以及 Kerberos 认证如何配置。
这里分享给你一个 Flink 知识图谱,深入理解每个知识点,才能解决工作中的实际问题。
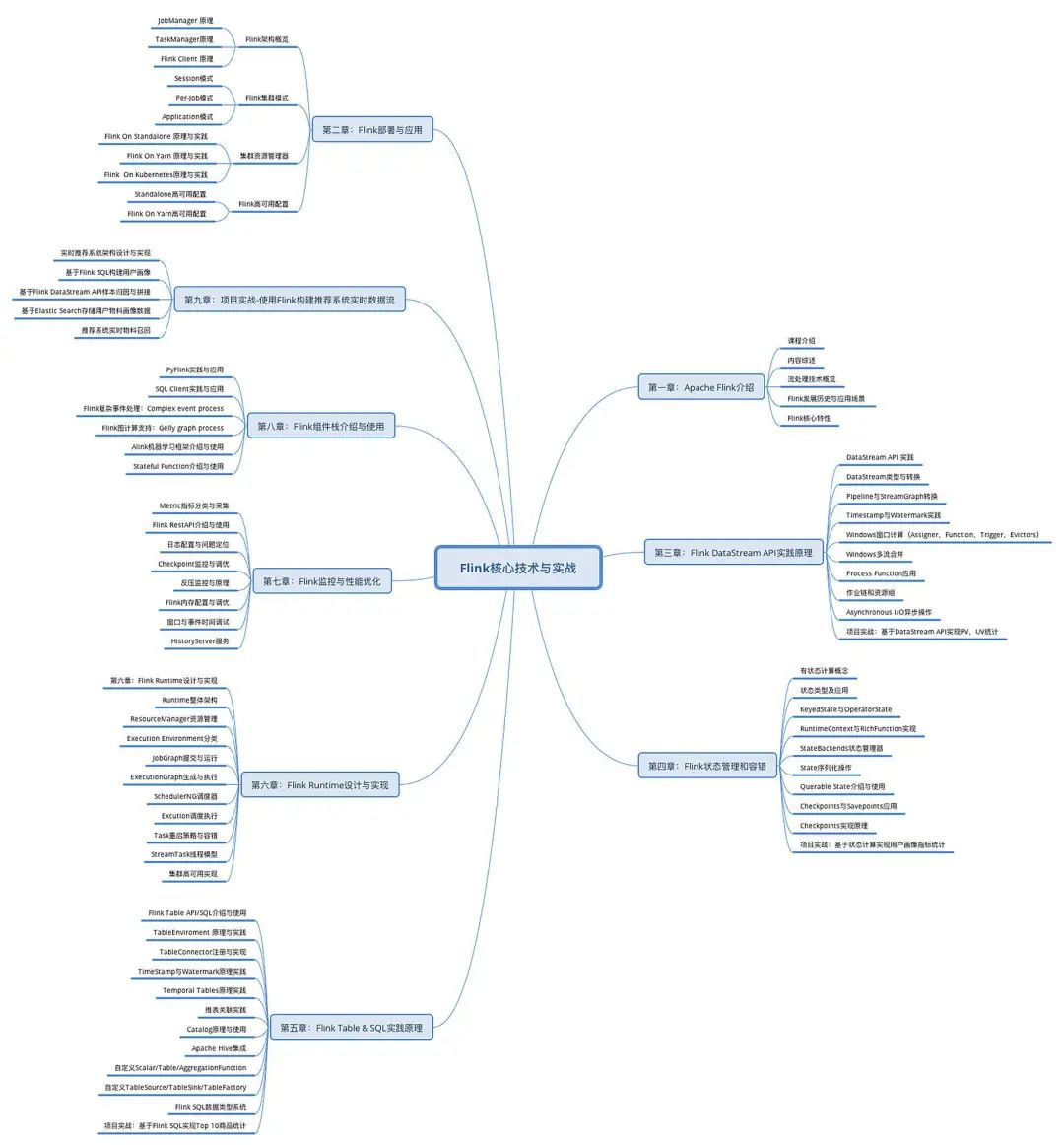
这张图谱出自张利兵,他是第四范式数据中台架构师,Apache Flink 社区贡献者。他在大数据领域深耕 7 年了,主导过大型国有银行云计算平台产品研发和部署,以及大数据平台产品研发和实施,著有《Flink 原理、实战与性能优化》一书。
最近,他推出了一门视频课 《Flink 核心技术与实战》 ,看了课程目录和部分内容,很想推荐给你。
在课程中,他深入剖析了 Flink Runtime 的设计与实现机制,带你掌握 Flink SQL 接口的原理与操作方法,理解 Flink DataStream API 的实践原理,并构建一个完整的实时推荐数据流系统,带你彻底拿下 Flink。

拼团+ 口令 「happy2021」
到手仅 ¥89 ,原价 ¥129
他是如何讲解 Flink 的?
通过这些年来的实战经验,学习流式计算和 Flink,有这么几个关键点:
了解数据处理过程中的基本模式,包括数据输入、处理和输出;
理解真实数据,因为流处理只是挖掘客观事实背后价值的手段,而只有真正理解数据,才能知道如何通过流计算产生价值;
深入理解 Flink 架构,例如流计算中的常见概念:有状态计算、数据一致性保障等等,这些是掌握流计算的重要前提。
当然,还有很多知识点,例如版本更新迭代带来的新知识,这些张利兵在课程中都有一一讲解。值得一提的是:课程基于 Flink 最新 1.11.1 版本讲解,通过原理解读和实战练习,带你掌握 Flink 在实时开发过程中所涉及到的全部核心技术,主要分为四部分:
首先,带你了解 Flink 基本概念,以及如何在不同的环境中安装 Flink 集群,让你对 Flink 有一个基本的认识;
接下来,重点讲解 Flink 作业的开发与实践,学习 DataStream API 和 Table ,以及 SQL 接口的使用与相应的原理解析。同时,每个章节末尾提供了对应的练习,加深你对 Flink 的掌握;
随后,深入剖析 Flink 的核心原理,包括 Runtime 的设计与实现,常用的监控指标 Checkpoint 等等,带你了解这些指标底层的含义,以及如何在实际项目中对集群进行调优。
最后,通过一个完整的推荐项目,将所有知识点串联起来,让你真正理解和掌握 Flink。
我有足够的把握,跟他学完这门课,你可以轻松解决工作中遇到的开发难题,提升流式数据处理能力,从而真正掌握 Flink。
说了那么多,先看看目录吧👇

订阅福利
拼团+ 口令 「happy2021」
春节特惠,到手仅 ¥89 ,原价 ¥129

👆扫码免费试看
我再给大家一并推荐个非常值得一读的专栏《 Kafka核心技术与实战》 。 毋庸置疑,Kafka 是整个消息引擎领域的执牛耳者,也是大数据生态圈中颇为重量级的一员。 Apache Kafka 活跃代码贡献者胡夕,根据他的实战经验,带你从 Kafka 入门、Kafka 的基本使用、客户端详解、Kafka 原理介绍、Kafka 运维与监控以及高级 Kafka 应用系统学习 Kafka。 相信学完你一定能透彻理解 Kafka,并更好地应用。

拼团+口令「happy2021」
到手仅 ¥89 ,原价 ¥129
👇点击 「阅读原文」 ,
输入 优惠口令 「happy2021」,
以 最低价 ¥89 入手,仅限前 100 人。
本文分享自微信公众号 - 大数据技术与架构(import_bigdata)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。











