
Memcached简介:
Memcached是一款开源、高性能、分布式内存对象缓存系统,可应用各种需要缓存的场景,其主要目的是通过降低对Database的访问来加速web应用程序。它是一个基于内存的“键值对”存储,用于存储数据库调用、API调用或页面引用结果的直接数据,如字符串、对象等。
Memcached是以LiveJournal旗下Danga Interactive 公司的Brad Fitzpatric 为首开发的一款软件。现在已成为mixi、hatena、Facebook、Vox、LiveJournal等众多服务中提高Web应用扩展性的重要因素。
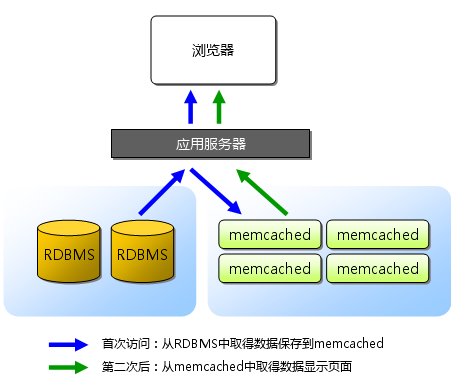
许多Web应用都将数据保存到RDBMS(关系型数据库管理系统)中,应用服务器从中读取数据并在浏览器中显示。 但随着数据量的增大、访问的集中,就会出现RDBMS的负担加重、数据库响应恶化、 网站显示延迟等重大影响。这时就该Memcached大显身手了。Memcached是高性能的分布式内存缓存服务器。 一般的使用目的是,通过缓存数据库查询结果,减少数据库访问次数,以提高动态Web应用的速度、 提高可扩展性。如下图,
Memcached是一款开发工具,它既不是一个代码加速器,也不是数据库中间件。其设计哲学思想主要反映在如下方面:
1. 简单key/value存储:服务器不关心数据本身的意义及结构,只要是可序列化数据即可。存储项由“键、过期时间、可选的标志及数据”四个部分组成。
2. 功能的实现一半依赖于客户端,一半基于服务器端:客户负责发送存储项至服务器端、从服务端获取数据以及无法连接至服务器时采用相应的动作;服务端负责接收、存储数据,并负责数据项的超时过期。
3. 各服务器间彼此无视,不在服务器间进行数据同步。
4. O(1)的执行效率。
5. 清理超期数据,默认情况下,Memcached是一个LRU缓存,同时,它按事先预订的时长清理超期数据。但事实上,Memcached不会删除任何已缓存数据,只是在其过期之后不再为客户所见;而且,Memcached也不会真正按期限清理缓存,而仅是当get命令到达时检查其时长。
Memcached的协议简介:
Memcached的客户端通过TCP连接与服务器通信(UDP协议的接口也可以使用,详细说明请参考”UDP 协议”部分)。一个给定的运行中的Memcached服务器在某个(可配置的)端口上监听连接;客户端连接该端口,发送命令给服务器,读取反馈,最后关闭连接。没有必要发送一个专门的命令去结束会话。客户端可以在不需要该连接的时候就关闭它。
注意:我们鼓励客户端缓存它们与服务器的连接,而不是每次要存储或读取数据的时候再次重新建立与服务器的连接。Memcached同时打开很多连接不会对性能造成到大的影响,这是因为Memcached在设计之处,就被设计成即使打开了很多连接(数百或者需要时上千个连接)也可以高效的运行。缓存连接可以节省与服务器建立TCP连接的时间开销(于此相比,在服务器段为建立一个新的连接所做准备的开销可以忽略不计)。
Memcached通信协议有两种类型的数据:文本行和非结构化数据。文本行用来发送从客户端到服务器的命令以及从服务器回送的反馈信息。非结构化的数据用在客户端希望存储或者读取数据时。服务器会以字符流的形式严格准确的返回相应数据在存储时存储的数据。服务器不关注字节序,它也不知道字节序的存在。Memcahced对非结构化数据中的字符没有任何限制,可以是任意的字符,读取数据时,客户端可以在前次返回的文本行中确切的知道接下来的数据块的长度。
文本行通常以“"r"n”结束。非结构化数据通常也是以“"r"n”结束,尽管"r、"n或者其他任何8位字符可以出现在数据块中。所以当客户端从服务器读取数据时,必须使用前面提供的数据块的长度,来确定数据流的结束,二不是依据跟随在字符流尾部的“"r"n”来确定数据流的结束,尽管实际上数据流格式如此。
关键字 Keys:
Memcached使用关键字来区分存储不同的数据。关键字是一个字符串,可以唯一标识一条数据。当前关键字的长度限制是250个字符(当然目前客户端似乎没有需求用这么长的关键字);关键字一定不能包含控制字符和空格。
Memcached提供了为数不多的几个命令来完成与服务器端的交互,这些命令基于Memcached的协议实现。
存储类命令:set, add, replace, append, prepend
获取数据类命令:get, delete, incr/decr
统计类命令:stats, stats items, stats slabs, stats sizes
清理命令: flush_all
所有的命令行总是以命令的名字开始,紧接着是以空格分割的参数。命令名称都是小写,并且是大小写敏感的。
Memcached依赖于libevent API:
libevent是个程序库,它将Linux的epoll、BSD类操作系统的kqueue等事件处理功能封装成统一的接口。即使对服务器的连接数增加,也能发挥O(1)的性能。Memcached使用这个libevent库,因此能在Linux、BSD、Solaris等操作系统上发挥其高性能。 关于事件处理这里就不再详细介绍,可以参考libevent官方文档与The C10K Problem。
Memcached的内置内存存储方式:
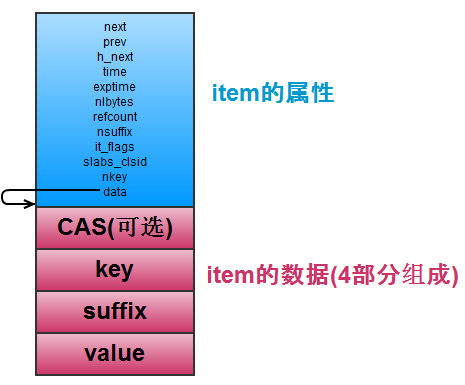
源码中这样定义 struct item:
/**
* Structure for storing items within memcached.
*/
typedef struct _stritem {
struct _stritem *next;
struct _stritem *prev;
struct _stritem *h_next; /* hash chain next */
rel_time_t time; /* least recent access */
rel_time_t exptime; /* expire time */
int nbytes; /* size of data */
unsigned short refcount;
uint8_t nsuffix; /* length of flags-and-length string */
uint8_t it_flags; /* ITEM_* above */
uint8_t slabs_clsid;/* which slab class we're in */
uint8_t nkey; /* key length, w/terminating null and padding */
/* this odd type prevents type-punning issues when we do
* the little shuffle to save space when not using CAS. */
union {
uint64_t cas;
char end;
} data[];
/* if it_flags & ITEM_CAS we have 8 bytes CAS */
/* then null-terminated key */
/* then " flags length\r\n" (no terminating null) */
/* then data with terminating \r\n (no terminating null; it's binary!) */
} item;
从源码可以得出 item 的结构分两部分, 第一部分定义 item 结构的属性, 包括连接其它 item 的指针 (next, prev),还有最近访问时间(time), 过期的时间(exptime), 以及数据部分的大小, 标志位, key的长度, 引用次数, 以及 item 是从哪个 slabclass 分配而来。
研究Memcached这个产品,首先从它的内存模型开始:我们知道c++里分配内存有两种方式,预先分配和动态分配,显然,预先分配内存会使程序比较快,但是它的缺点是不能有效利用内存,而动态分配可以有效利用内存,但是会使程序运行效率下降,Memcached的内存分配就是基于以上原理,显然为了获得更快的速度,有时候我们不得不以空间换时间。
Memcached的高性能源于两阶段哈希(two-stage hash)结构。Memcached就像一个巨大的、存储了很多<key,value>对的哈希表。通过key,可以存储或查询任意的数据。 客户端可以把数据存储在多台Memcached上。当查询数据时,客户端首先参考节点列表计算出key的哈希值(阶段一哈希),进而选中一个节点;客户端将请求发送给选中的节点,然后Memcached节点通过一个内部的哈希算法(阶段二哈希),查找真正的数据(item)并返回给客户端。从实现的角度看,Memcached是一个非阻塞的、基于事件的服务器程序。
为了提高性能,Memcached 中保存的数据都存储在Memcached 内置的内存存储空间中。由于数据仅存在于内存中,因此重启Memcached、重启操作系统会导致全部数据消失。另外,内容容量达到指定值之后,就基于LRU(Least Recently Used)算法自动删除不使用的缓存。Memcached 本身是为缓存而设计的服务器,因此并没有过多考虑数据的永久性问题。
Memcache使用了Slab Allocator的内存分配机制: 按照预先规定的大小,将分配的内存分割成特定长度的块,以完全解决内存碎片问题。
Slab Allocator 的机制分配、管理内存。在该机制出现以前,内存的分配是通过对所有记录简单地进行malloc和free 来进行的。但是,这种方式会导致内存碎片,加重操作系统内存管理器的负担,最坏的情况下,会导致操作系统比memcached 进程本身还慢。Slab Allocator 就是为解决该问题而诞生的,Slab Allocation 的原理是按照预先规定的大小,将分配的内存分割成特定长度的块(chunk),并把尺寸相同的块分成组,以完全解决内存碎片问题。但由于分配的是特定长度的内存,因此无法有效利用分配的内存。比如将100字节的数据缓存到128字节的chunk中,剩余的28字节就浪费了。还有slab allocator 还有重复使用已分配的内存的目的。也就是说,分配到的内存不会释放,而是重复利用。
存储结构图如下:

Page:分配给Slab的内存空间,默认是1MB。分配给Slab之后根据slab的大小切分成chunk。
Chunk:用于缓存记录的内存空间。
Slab Class:特定大小的chunk的组。
Memcached根据收到的数据的大小,选择最适合数据大小的slab。
Memcached中保存着slab内空闲chunk的列表,根据该列表选择chunk,然后将数据缓存于其中。
Slab中缓存记录的原理:
Memcached 根据收到的数据的大小,选择最适合数据大小的slab,Memcached 中保存着slab 内空闲chunk 的列表,根据该列表选择合适的chunk,然后将数据缓存于其中

Slab Allocator 的缺点:
由于分配的是特定长度的内存,因此无法有效利用分配的内存。例如,将100 字节的数据缓存到128 字节的chunk 中,剩余的28字节就浪费了
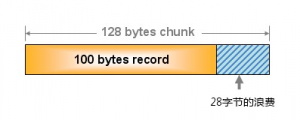
对于该问题目前还没有完美的解决方案,但在文档中记载了比较有效的解决方案。就是说,如果预先知道客户端发送的数据的公用大小,或者仅缓存大小相同的数据的情况下,只要使用适合数据大小的组的列表,就可以减少浪费。但是很遗憾,现在还不能进行任何调优,只能期待以后的版本了。但是,我们可以调节slab class 的大小的差别。接下来说明growth factor 选项。
使用growth factor(增长因子) 进行调优:
Memcached 在启动时指定growth factor 因子(通过f 选项),就可以在某种程度上控制slab 之间的差异。默认值为1.25。但是,在该选项出现之前,这个因子曾经固定为2,称为“powers of 2”策略。
下面是启动后的verbose 输出:
slab class 1: chunk size 128 perslab 8192
slab class 2: chunk size 256 perslab 4096
slab class 3: chunk size 512 perslab 2048
slab class 4: chunk size 1024 perslab 1024
slab class 5: chunk size 2048 perslab 512
slab class 6: chunk size 4096 perslab 256
slab class 7: chunk size 8192 perslab 128
slab class 8: chunk size 16384 perslab 64
slab class 9: chunk size 32768 perslab 32
slab class 10: chunk size 65536 perslab 16
slab class 11: chunk size 131072 perslab 8
slab class 12: chunk size 262144 perslab 4
slab class 13: chunk size 524288 perslab 2
可见,从128 字节的组开始,组的大小依次增大为原来的2 倍。这样设置的问题是,slab 之间的差别比较大,有些情况下就相当浪费内存。因此,为尽量减少内存浪费,修改了growth factor 这个选项来看看现在的默认设置(f=1.25)时的输出(篇幅所限,这里只写到第10 组):
slab class 1: chunk size 88 perslab 11915
slab class 2: chunk size 112 perslab 9362
slab class 3: chunk size 144 perslab 7281
slab class 4: chunk size 184 perslab 5698
slab class 5: chunk size 232 perslab 4519
slab class 6: chunk size 296 perslab 3542
slab class 7: chunk size 376 perslab 2788
slab class 8: chunk size 472 perslab 2221
slab class 9: chunk size 592 perslab 1771
slab class 10: chunk size 744 perslab 1409
可见,组间差距比因子为2 时小得多,更适合缓存几百字节的记录。从上面的输出结果来看,可能会觉得有些计算误差,这些误差是为了保持字节数的对齐而故意设置的。将Memcached 引入产品,或是直接使用默认值进行部署时,最好是重新计算一下数据的预期平均长度,调整growth factor,以获得最恰当的设置。内存是珍贵的资源,浪费就太可惜了。
Memcached的过期时间实现方式:
采用Lazy Expiration + LRU的方式
Lazy Expiration:
Memcached 内部不会监视记录是否过期,而是在get 时查看记录的时间戳,检查记录是否过期。这种技术被称为lazy(惰性)expiration。因此,Memcached不会在过期监视上耗费CPU 时间。
LRU :
Memcached 会优先使用已超时的记录的空间,但即使如此,也会发生追加新记录时空间不足的情况,此时就要使用名为Least Recently Used(LRU)机制来分配空间。顾名思义,这是删除“最近最少使用”的记录的机制。因此,当Memcached 的内存空间不足时(无法从slab class 获取到新的空间时),就从最近未被使用的记录中搜索,并将其空间分配给新的记录。从缓存的实用角度来看,该模型十分理想。不过,有些情况下LRU 机制反倒会造成麻烦。Memcached 启动时通过“M”参数可以禁止LRU。
Memcached的分布式算法(不互相通信的分布式):
Memcached 虽然称为“分布式”缓存服务器,但服务器端并没有“分布式”功能。Memcached 的分布式,则是完全由客户端应用程序实现的。这种分布式是Memcached 的最大特点。
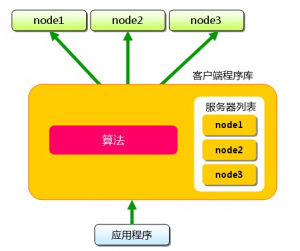
Memcached的分布式是怎么实现的?
下面假设memcached 服务器有node1~node3 三台,应用程序要保存键名为"luochen","zhangsan"的数据。首先向Memcached服务器 中添加"luochen",将"luochen"传给客户端应用程序后,客户端实现的算法就会根据“键”来决定保存数据的Memcached 服务器。服务器选定后,即命令它保存"luochen"及其值同样,"zhangsan"都是先选择服务器再接下来保存数据。获取时也要先获取"luochen"的“键”传递给应用程序。应用程序通过与数据保存时相同的算法,根据“键”选择服务器。使用的算法相同,就能选中与保存时相同的服务器,然后发送get 命令。只要数据没有因为某些原因被删除,就能获得保存的值。这样,将不同的键保存到不同的服务器上,就实现了Memcached 的分布式。Memcached 服务器增多后,键就会分散,即使一台Memcached 服务器发生故障无法连接,也不会影响其他的缓存,系统依然能继续运行。
第一种分布式算法(用键除以Memcached服务器的总数取余):
就是“根据服务器台数的余数进行分散”。求得键的整数哈希值,再除以服务器台数,根据其余数来选择服务器。
第一种算法的缺点:余数计算的方法简单,数据的分散性也相当优秀,但也有其缺点。那就是当添加或移除服务器时,缓存重组的代价相当巨大。添加服务器后,余数就会产生巨变,这样就无法获取与保存时相同的服务器,从而影响缓存的命中,大量缓存会失效。
第二中分布式(一致性哈希)算法:
知识补充:哈希算法,即散列函数。将任意长度的二进制值映射为较短的固定长度的二进制值,这个小的二进制值称为哈希值。哈希值是一段数据唯一且极其紧凑的数值表示形式。如果散列一段明文而且哪怕只更改该段落的一个字母,随后的哈希都将产生不同的值。要找到散列为同一个值的两个不同的输入,在计算上是不可能的,所以数据的哈希值可以检验数据的完整性。一般用于快速查找和加密算法。(常见的有MD5,SHA-1)。
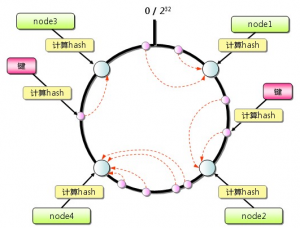
Consistent Hashing 的简单说明:
Consistent Hashing 如下所示:首先求出Memcached 服务器(节点)的哈希值,并将其配置到0~232 的圆(continuum)上。然后用同样的方法求出存储数据的键的哈希值,并映射到圆上。然后从数据映射到的位置开始顺时针查找,将数据保存到找到的第一个服务器上。如果超过232 仍然找不到服务器,就会保存到第一台Memcached 服务器上。
从上图的状态中添加一台Memcached 服务器。余数分布式算法由于保存键的服务器会发生巨大变化,而影响缓存的命中率,但Consistent Hashing中,只有在continuum 上增加服务器的地点逆时针方向的第一台服务器上的键会受到影响
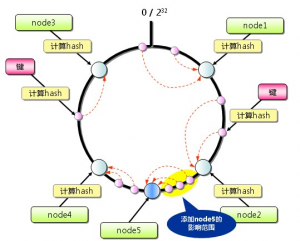
Consistent Hashing(添加服务器):
因此,Consistent Hashing 最大限度地抑制了键的重新分布。而且,有的Consistent Hashing 的实现方法还采用了虚拟节点的思想。使用一般的hash函数的话,服务器的映射地点的分布非常不均匀。因此,使用虚拟节点的思想,为每个物理节点(服务器)在continuum上分配100~200 个点。这样就能抑制分布不均匀,最大限度地减小服务器增减时的缓存重新分布。
通过上文中介绍的使用Consistent Hashing 算法的Memcached 客户端函数库进行测试的结果是,由服务器台数(n)和增加的服务器台数(m)计算增加服务器后的命中率计算公式如下:
(1 - n/(n+m)) * 100
PS : 注意事项
1. Memcached已经分配的内存不会再主动清理。
2. Memcached分配给某个slab的内存页不能再分配给其他slab。
3. flush_all不能重置Memcached分配内存页的格局,只是给所有的item置为过期。
4. Memcached最大存储的item(key+value)大小限制为1M,这由page大小1M限制
5.由于Memcached的分布式是客户端程序通过hash算法得到的key取模来实现,不同的语言可能会采用不同的hash算法,同样的客户端程序也有可能使用相异的方法,因此在多语言、多模块共用同一组Memcached服务时,一定要注意在客户端选择相同的hash算法
6.启动Memcached时可以通过-M参数禁止LRU替换,在内存用尽时add和set会返回失败
7.Memcached启动时指定的是数据存储量,没有包括本身占用的内存、以及为了保存数据而设置的管理空间。因此它占用的内存量会多于启动时指定的内存分配量,这点需要注意。
8.Memcached存储的时候对key的长度有限制,php和C的最大长度都是250
Memcached一些疑难问题
1. 为什么不能用缓存保存session?
当MC内存空间不足,并且没有过期数据,MC用新数据覆盖LRU的数据,导致部分session信息被清除,用户重新登录才能获取到session,用户体验差。实际上,可以把session持久化到DB,MC缓存一份session,待MC查询不到session信息,再到DB查询,并更新MC,既能保证数据不丢失,也保证session查询速度快。
2. 为什么同一个MC的数据,有的缓存(值较大的旧数据)要2天才被置换出,有的缓存(值较小的新数据)几分钟就被置换出?
值较大的数据占用Slab Class的大Chunk size,值较小的数据占用Slab Class的小Chunk size,根据Slab钙化问题,当值较小的数据占用Slab Class空间不够用时,并且没有多余的内存和过期的数据,不会挪用值较大的数据占用Slab Class空间,只会复用原有值较小的数据占用Slab Class空间,根据LRU算法置换出同一种Slab的Chunk数据。
Slab钙化问题请查看拙作[Memcached] Slab钙化问题
3. Cache失效后的拥堵问题
通常我们会为两种数据做Cache,一种是热数据,也就是说短时间内有很多人访问的数据;另一种是高成本的数据,也就说查询很耗时的数据。当这些数据过期的瞬间,如果大量请求同时到达,那么它们会一起请求后端重建Cache,造成拥堵问题。
一般有如下几种解决思路可供选择:
首先,通过定时任务主动更新Cache;
其次,我们可以加分布式锁,保证只有一个请求访问数据库更新缓存。
4. Multiget的无底洞问题
出于效率的考虑,很多Memcached应用都以Multiget操作为主,随着访问量的增加,系统负载捉襟见肘,遇到此类问题,直觉通常都是增加服务器来提升系统性能,但是在实际操作中却发现问题并不简单,新加的服务器好像被扔到了无底洞里一样毫无效果。Multiget根据key请求多台服务器,但这并不是问题的症结,真正的原因在于客户端在请求多台服务器时是并行的还是串行的!问题是很多客户端,在处理Multiget多服务器请求时,使用的是串行的方式!也就是说,先请求一台服务器,然后等待响应结果,接着请求另一台,结果导致客户端操作时间累加,请求堆积,性能下降。
5. 缓存命中率下降,但是内存的利用率很高时,我们需要如何进行处理?
内存空间不足,导致缓存失效移除,命中率下降,既然内存利用率高,扩容MC服务器即可。
6. 缓存命中率下降,内存的利用率也在下降时,我们需要如何进行处理?
跟问题2类似,也是Slab钙化问题。空间利用率高的Slab Class不会使用空间利用率低的其他的Slab Class,导致空间利用率高的Slab Class不断因为LRU踢出数据,总体而言,缓存命中率下降,内存的利用率也会下降。
Slab钙化降低内存使用率,如果发生Slab钙化,有三种解决方案:
- 重启Memcached实例,简单粗暴,启动后重新分配Slab class,但是如果是单点可能造成大量请求访问数据库,出现雪崩现象,冲跨数据库。
- 随机过期:过期淘汰策略也支持淘汰其他slab class的数据,twitter工程师采用随机选择一个Slab,释放该Slab的所有缓存数据,然后重新建立一个合适的Slab。
- 通过slab_reassign、slab_authmove。
7. 通常情况下,缓存的粒度越小,命中率会越高。
举个实际的例子说明:当缓存单个对象的时候(例如:单个用户信息),只有当该对象对应的数据发生变化时,我们才需要更新缓存或者移除缓存。而当缓存一个集合的时候(例如:所有用户数据),其中任何一个对象对应的数据发生变化时,都需要更新或移除缓存。
由于序列化和反序列化需要一定的资源开销,当处于高并发高负载的情况下,对大对象数据的频繁读取有可能会使得服务器的CPU崩溃。
8. 缓存被“击穿”问题
对于一些设置了过期时间的key,如果这些key可能会在某些时间点被超高并发地访问,是一种非常“热点”的数据。这个时候,需要考虑另外一个问题:缓存被“击穿”的问题。
概念:缓存在某个时间点过期的时候,恰好在这个时间点对这个Key有大量的并发请求过来,这些请求发现缓存过期一般都会从后端DB加载数据并回设到缓存,这个时候大并发的请求可能会瞬间把后端DB压垮。
如何解决:业界比较常用的做法,是使用mutex。简单地来说,就是在缓存失效的时候(判断拿出来的值为空),不是立即去load db,而是先使用缓存工具的某些带成功操作返回值的操作(比如Redis的SETNX或者Memcache的ADD)去set一个mutex key,当操作返回成功时,再进行load db的操作并回设缓存;否则,就重试整个get缓存的方法。类似下面的代码:
public String get(key) { String value = redis.get(key); if (value == null) { //代表缓存值过期 //设置3min的超时,防止del操作失败的时候,下次缓存过期一直不能load db if (redis.setnx(key_mutex, 1, 3 * 60) == 1) { //代表设置成功 value = db.get(key); redis.set(key, value, expire_secs); redis.del(key_mutex); } else { //这个时候代表同时候的其他线程已经load db并回设到缓存了,这时候重试获取缓存值即可 sleep(50); get(key); //重试 } } else { return value;
} }












