
点击上方蓝色字体,选择“设为星标”
回复”资源“获取更多资源


点击右侧关注,大数据开发领域最强公众号!


点击右侧关注,暴走大数据!

一、UDF的使用
1、Spark SQL自定义函数就是可以通过scala写一个类,然后在SparkSession上注册一个函数并对应这个类,然后在SQL语句中就可以使用该函数了,首先定义UDF函数,那么创建一个SqlUdf类,并且继承UDF1或UDF2等等,UDF后边的数字表示了当调用函数时会传入进来有几个参数,最后一个R则表示返回的数据类型,如下图所示:
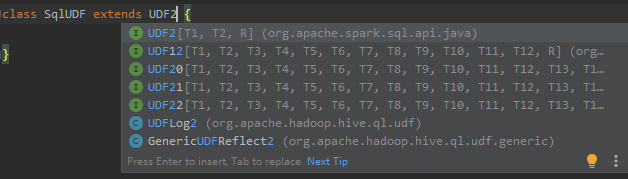
2、这里选择继承UDF2,如下代码所示:
package com.udf
3、然后在SparkSession生成的对象上通过sparkSession.udf.register进行注册,如下代码所示:
val conf=new SparkConf().setAppName("AppUdf").setMaster("local")
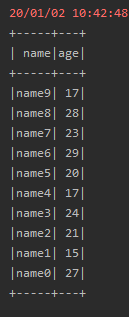
4、生成模拟数据,并注册一个临时表,如下代码所示:
var rows=Seq[Row]()
输出 结果如下图所示:
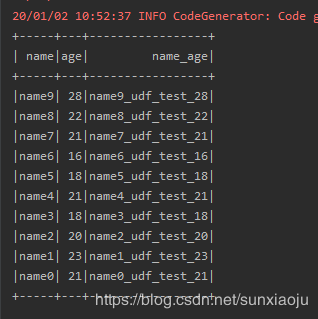
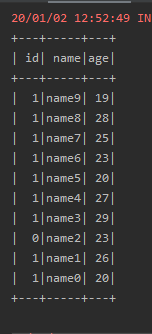
5、在sql语句中使用自定义函数splicing_t1_t2,然后将函数的返回结果定义一个别名name_age,如下代码所示:
val sql="SELECT name,age,splicing_t1_t2(name,age) name_age FROM person"
输出结果如下:
6、由此可以看到在自定义的UDF类中,想如何操作都可以了,完整代码如下;
package com.udf
二、无类型的用户自定于聚合函数:UserDefinedAggregateFunction
1、它是一个接口,需要实现的方法有:
class AvgAge extends UserDefinedAggregateFunction {
这是一个计算平均年龄的自定义聚合函数,实现代码如下所示:
package com.udf
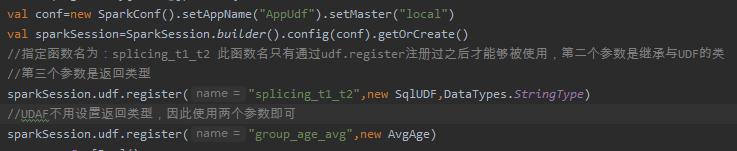
2、注册该类,并指定到一个自定义函数中,如下图所示:
3、在表中加一列字段id,通过GROUP BY进行分组计算,如
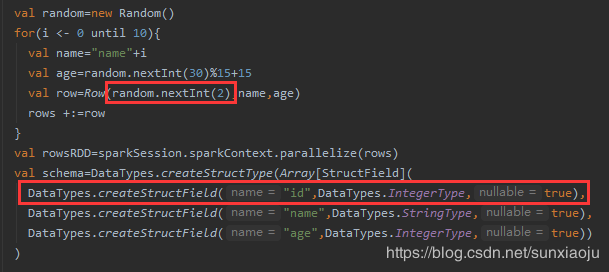
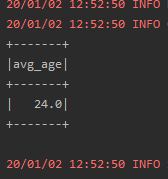
4、在sql语句中使用group_age_avg,如下图所示:

输出结果如下图所示:
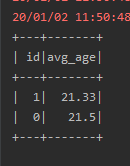
5、完整代码如下:
package com.udf
三、类型安全的用户自定于聚合函数:Aggregator
1、它是一个接口,需要继承与Aggregator,而Aggregator有3个参数,分别是IN,BUF,OUT,IN表示输入的值是什么,可以是一个自定类对象包含多个值,也可以是单个值,BUF就是需要用来缓存值使用的,如果需要缓存多个值也需要定义一个对象,而返回值也可以是一个对象返回多个值,需要实现的方法有:
package com.udf
2、具体实现如下代码所示:
package com.udf
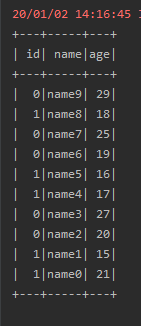
3、而使用此聚合函数就不能通过注册函数来使用了,需要通过Dataset对象的select来使用,如下图所示:
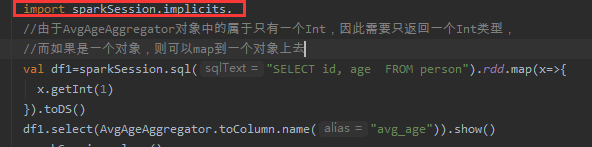
执行结果如下图所示:
因此无类型的用户自定于聚合函数:UserDefinedAggregateFunction和类型安全的用户自定于聚合函数:Aggregator之间的区别是
(1)UserDefinedAggregateFunction不能够带类型而Aggregator是可以带类型的。
(2)使用方法不同UserDefinedAggregateFunction通过注册可以在DataFram的sql语句中使用,而Aggregator必须是在Dataset上使用。
四、开窗函数的使用
1、在Spark 1.5.x版本以后,在Spark SQL和DataFrame中引入了开窗函数,其中比较常用的开窗函数就是row_number该函数的作用是根据表中字段进行分组,然后根据表中的字段排序;其实就是根据其排序顺序,给组中的每条记录添加一个序号;且每组的序号都是从1开始,可利用它的这个特性进行分组取top-n。它是放在select子句中的,其格式为:
ROW_NUMBER() OVER (PARTITION BY area ORDER BY click_count DESC) rank
首先可以,在SELECT查询时,使用row_number()函数,其次row_number()函数后面先跟上OVER关键字,然后括号中,是PARTITION BY,也就是说根据哪个字段进行分组,其次是可以用ORDER BY进行组内排序, 然后row_number()就可以给每个组内的行,一个组内行号,然后rank就是每一组的行号
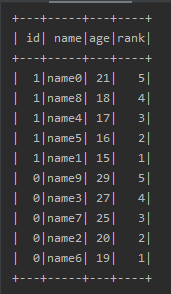
2、使用方法的sql语句为:
SELECT id,name,age,row_number() OVER (PARTITION BY id ORDER BY age) rank FROM person ORDER BY id desc,rank desc
意思是在sql语句中加一个rank字段,该字段记录了以id为分组,在组内按照age升序排序,并记录行号,最后先按照id降序排序,如果id相同则按照rank降序排序
3、代码如下:
package com.udf
输出结果如下:
欢迎点赞+收藏+转发朋友圈素质三连

文章不错?点个【在看】吧!** 👇**
本文分享自微信公众号 - 大数据技术与架构(import_bigdata)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。











