为了解决流媒体平台应用程序监控的诸多痛点:警报太多、滚动屏幕太多、配置和维护太多......Netflix推出了 Telltale —— 一个建立在“用不着不断调整警报配置”前提上的应用程序监控系统。
作者:Andrei Ushakov, Seth Katz, Janak Ramachandran, Jeff Butsch, Peter Lau, Ram Vaithilingam, and Greg Burrell
原文链接:https://netflixtechblog.com/telltale-netflix-application-monitoring-simplified-5c08bfa780ba
01
Netflix的愿景
半夜,警报忽然被拉响,你从睡梦中惊醒,发现是一个度量标准跨过了限定的阈值。半梦半醒间,你迷迷糊糊地想,“这是真的出现了什么严重的问题吗? 还是只是一个有待调整的 _(小小的)_预警而已? 上一次有人调整我们的警报阈值是什么时候?也许只是因为上下游服务出了什么问题? ”。
但无论如何这是一个非常重要的应用程序,所以你不得不把自己从床上拽起来,打开你的笔记本电脑,然后开始浏览dashboard以获取更多信息。你还不能确信这是一个真正严重的问题,但你也意识到当自己在茫茫数据中寻找线索的时候,时间正在飞速流逝。
有效运作 Netflix 服务对该平台的用户体验至关重要。毕竟当用户坐下来看《Tiger King》 _(Netflix在疫情期间大火的一部自制剧)_时,他只希望这部剧能够流畅地播放 _(不要出其他任何幺蛾子)_。

《Tiger King》海报
多年来,Netflix从24小时随时待命的工程师那里学到了应用程序监控的痛点: _警报太多、滚动屏幕太多、配置和维护太多_。流媒体平台的播放团队需要一个能够使他们快速诊断和补救问题的监控系统,对他们来说,意外发生时的每一秒都是非常宝贵的。
而Netflix发现自己的Node team也需要一个能够助力小规模团队运行一系列大型应用的强大系统。
为此,Netflix创建了 _Telltale_。
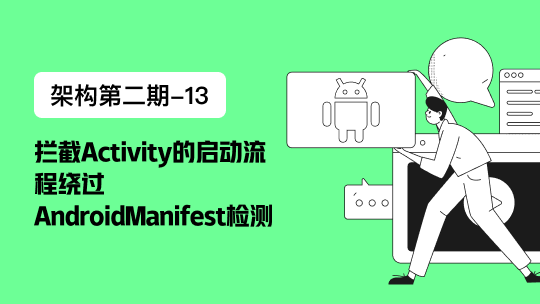
Telltale Timeline
Telltale 综合了多种数据源,以创建应用程序运行状况的整体视图。同时,它可以不断学习应用程序的典型运行状况 _(是否健康、良好)_而不需要警报调优。
Telltale也因此知道到底什么是“运行状况良好”,所以当程序所有者的服务有运行状况不够“良好”或仅仅是有“运行不良好”的趋势时,Netflix都可以及时地通知他们。
度量是了解应用程序运行健康状况的关键部分。但有时候你可能有太多的指标、图表以及太多的dashboard。Telltale只显示应用程序和上下游服务的相关数据,Netflix则会用颜色来标识问题的严重程度 (除了颜色,用户也可以选择用数字来显示) ,这样就可以一眼看出应用程序的运行状况。
除此之外,Netflix还会highlight一些更广泛更有趣的应用,比如区域流量疏散和附近程序部署,这些信息对于全面了解系统运行状况至关重要,尤其是在事故发生的时候。
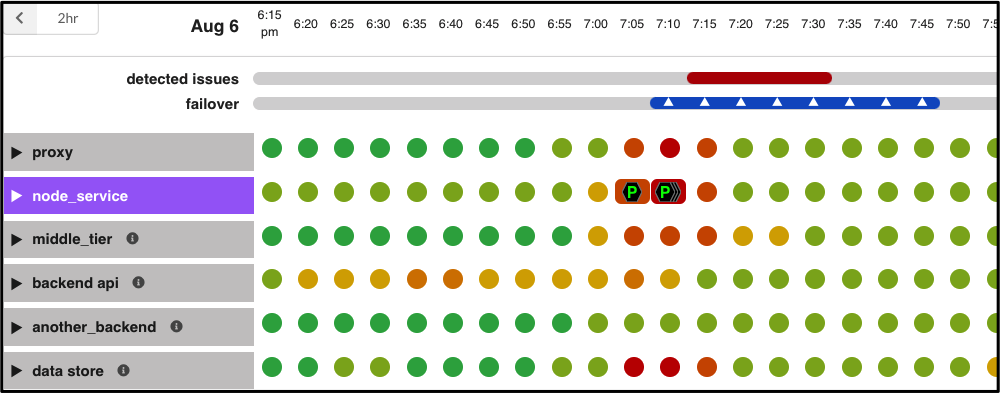
以上就是Netflix对于Telltale的愿景。而今天,这个愿景已经成为现实,Netflix在上周的科技博客中写道,Telltale现在监控着100多个面向 Netflix 生产端的应用程序的运行状况。
在生态系统中的应用程序
02
应用程序健康模型
任何Microservice _(微服务)_都不可能独立存在,它通常具有相应的依附关系,需要与其他相关服务互联互通,同时还存在于不同的 AWS 区域。
上文显示的调用图相对简单,它其实可以有更深的层次并囊括几十种服务。应用程序是系统的一部分,可能会受到属性变化的微妙影响,或者因为某些区域事件而发生根本性改变。一个 Canary _(https://netflixtechblog.com/automated-canary-analysis-at-netflix-with-kayenta-3260bc7acc69)_的启动也会影响应用程序,上下游的部署也是同样的道理。
Canary:原意是金丝雀,这里指一个新版本的软件,该软件通常只在运行稳定的情况下部署到一小部分用户中,以减少将新版本软件部署到生产环境中的风险。这种方法可以在不影响大多数用户的情况下快速发现新发布版本的问题。
Telltale使用多个来源的不同信号组装了一个不断进化、健康运行的应用程序模型:
Atlas时间序列度量
区域流量疏散
Mantis实时播放数据
基础设施改变事件
Canary落地及部署
上下游服务的健康运行
客户端度量和QoE变化
警报由Netflix的警报平台触发
不同的信号对应用程序运行的健康状况有不同程度的影响。例如,延迟增加没有错误率增加的问题那么严重,某些错误代码也不如其他错误那么重要。在下游部署双重Canary可能不像立即在上游部署Canary那么重要。
区域流量转移意味着一个区域的流量归零,而另一个区域的流量翻倍。你可以想象失去度量标准将产生什么样的影响,度量标准的含义决定了平台应该如何理解它。
Netflix称,在构建应用程序健康视图时,Telltale 考虑了以上所有这些因素。
应用程序健康模型则是 Telltale 系统的的核心。
03
智能监控
每个服务运营商都知道警报调校的难度:设置的阈值太低,你会得到一大堆虚假的警报。继而你可能会过度补偿之前的误差——放宽警报设定标准——以至于错过了真正重要的警报。最终结果是团队对于现有的警报系统缺乏信任。 而Telltale 就建立在一个“你用不着不断调整警报配置”的前提上。
Netflix称自己通过提供策划和管理的信号包,方便了应用程序所有者的相关设置和配置工作。这些信号包组合成应用程序配置文件,用来解决最常见的服务类型中的普遍问题。
Telltale 自动跟踪各项服务之间的依从关系,从而构建应用程序健康模型中使用的网络拓扑结构。信号包和网络布局检测能够以最小的代价保持最新的配置,同时那些偏爱实用方法的人群仍然可以进行手动配置和调优。
没有一个单一的算法可以解释Netflix所使用的(各种各样的)信号。因此,Netflix采用了混合算法,包括统计、规则和机器学习。Telltale 还配有相应的分析器来检测长期趋势或内存泄漏。
也就是说,智能监控意味着用户完全可以信任Telltale,也意味着(在意外发生时)更快速地检测与解决问题。
04
智能警报
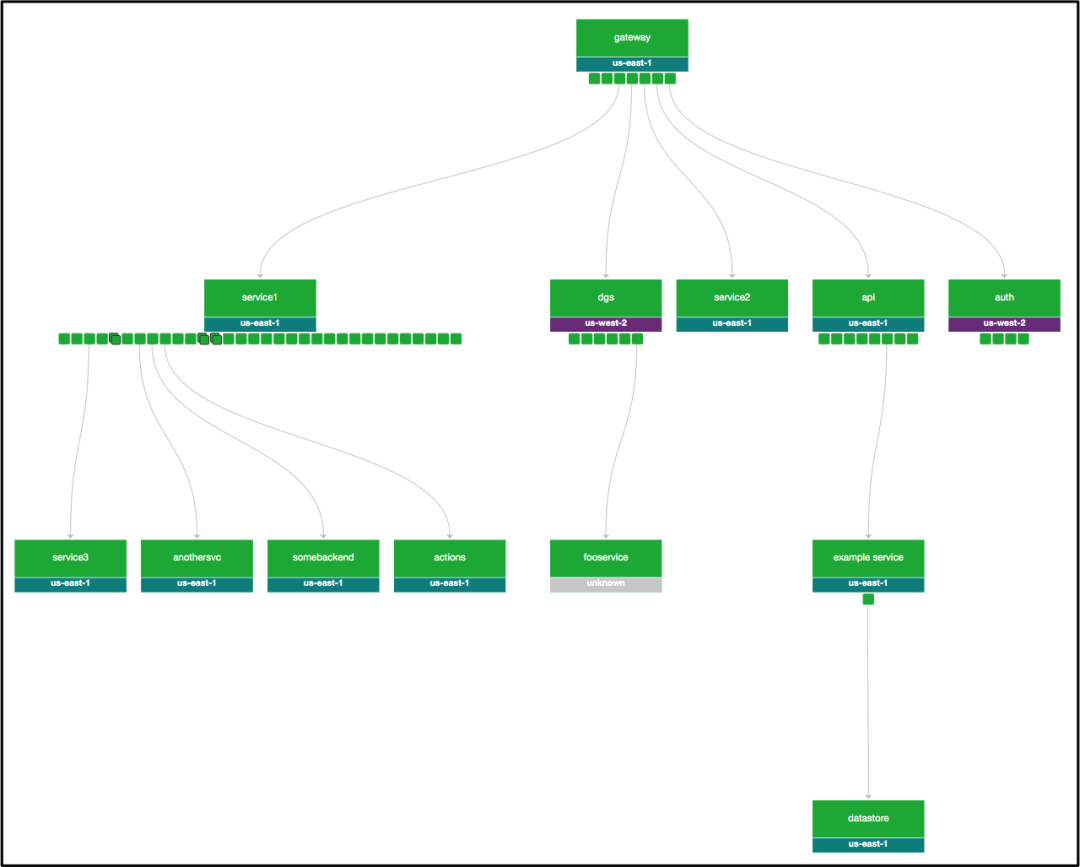
有了智能监控系统,自然也就产生了智能警报。当 Telltale 检测到应用程序系统运行中的问题时,会自动生成一个issue。团队可以选择通过 Slack、电子邮件或 PagerDuty (全部由Netflix内部警报系统提供支持)进行下一步警报生成。
如果问题是由上下游系统引起的,那么 Telltale 的上下文感知路由会向团队发出警告。智能警报也意味着只有一个相关团队会收到该通知,而所有团队都被警报轰炸的时代已经成为了过去。

Slack 中 Telltale 通知的示例
当问题出现时,获得正确的信息是至关重要的。Netflix的 Slack 警报也会启动一个只包含事件最相关上下文背景的线程,包括被Telltale识别为运行不健康的信号及其原因。这也为工程师们提供了对应用程序当前状态更好的理解,随时待命的他们也因此能够更容易地将程序恢复到正常状态。
_意外事件总是在不断进化并拥有自己的生命周期,因此不断更新系统是非常重要的。_情况到底是在变好还是在变坏?是否有新的信号或事件需要考虑?这些都需要平台和工程师们不断思考。
Telltale 随着当前事件的不断展开持续更新着 Slack 线程。相关线程在恢复到健康状态时会被标记为“已解决”,这样用户可以一目了然地知道哪些意外事件正在发生、哪些事件已经被成功补救。
但是这些 Slack 线程并不仅仅是为了Telltale而存在,团队成员还可以使用它们来分享附加的数据、相应的观察、理论和关于事件的讨论等等。事件数据和讨论都集中在一个线程中,有助于团队成员分享、理解以及更快地解决问题,同时也便于进行结果分析。
Netflix称自己也在努力提高Telltale系统中的警报质量。其中一个方法是从用户反馈中学习,他们在 Slack中创建了反馈按钮,并通过用户反馈来抑制未来警报出现的概率。同时,用户还可以给Netflix一些为什么某些警报不可操作的理由。这样一来,智能警报也意味着是用户可以信任的警报。
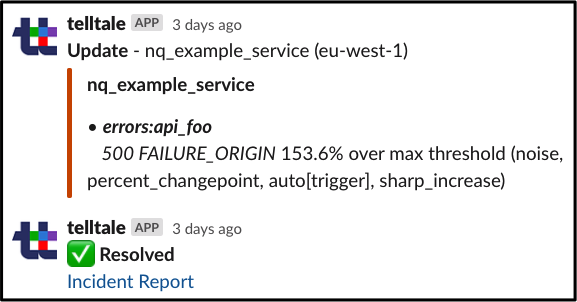
Slack 中的 Telltale 通知中的详细信息示例
05
为什么我的服务运行状况不佳?
各种各样的信号、应用程序系统的相关知识以及跨服务端的信号相关性有助于 Telltale 检测应用程序健康状况恶化的可能原因。这些可能的原因包括(但不限于)异常实例、Canary或非独立服务的部署、不健康的数据库或仅仅是流量激增等原因。将可能的原因进行highlight(在意外事件发生时)可以节省宝贵的时间。
06
事故管理
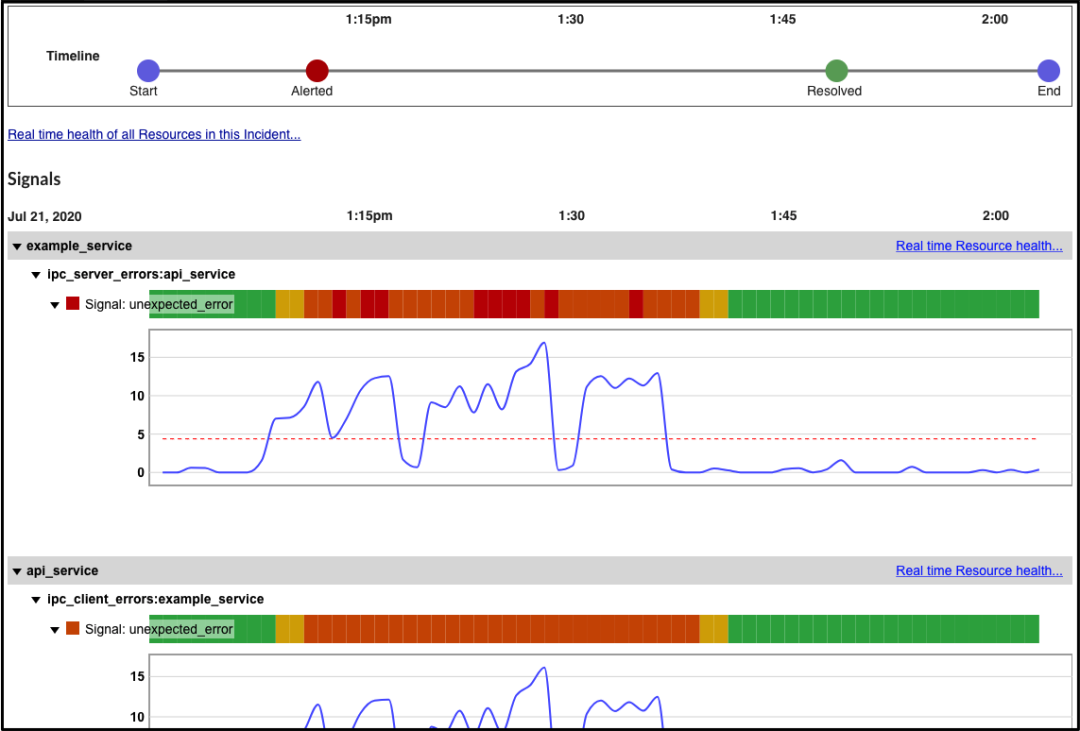
Telltale事件总结实例
当 Telltale 发送警报时,它还会参考相关的不健康信号创建一张快照,而随之到来的新信息也会被添加到该快照中。这简化了许多团队的事后评审过程。当需要回顾过去的问题时,应用程序事件摘要(Application Incident Summary)特性会在单一地点展示近期遇到的问题的方方面面,包括总停机时间和MTTR(Mean Time To Resolution 平均解决时间)等关键指标。 Netflix希望团队看到这些意外事件背后的模式和规律,以便他们能够提高总体服务可用性。

集群视图将类似事件分组
07
部署监控
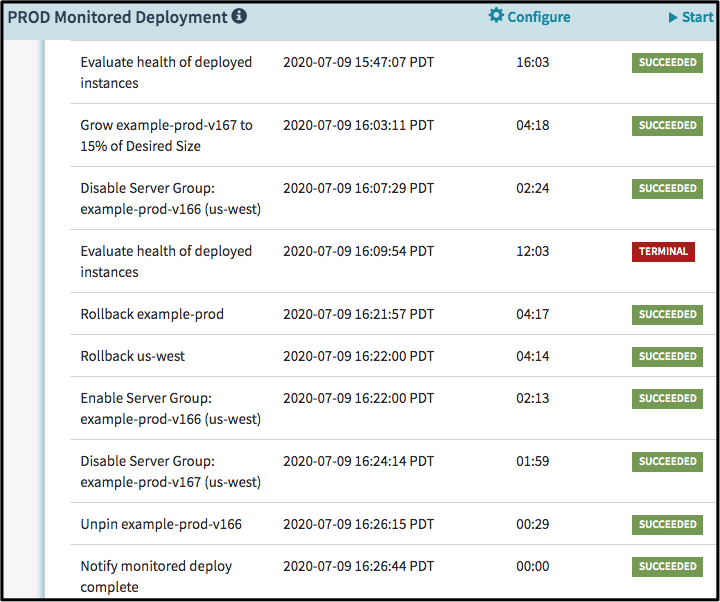
Telltale 的应用程序健康模型和智能监控强大的可靠性已经被有力地证明,以至于Netflix也在使用它来进行更安全的平台部署。
Netflix选择从 Spinnaker (Netflix的开源交付平台)开始。在 Spinnaker 推出新构建的漫长过程中,Netflix使用 Telltale 来持续监视新构建运行的健康状况。持续监控意味着该部署在出现第一个问题迹象时便会停止部署并重新运行。这也意味着该问题衍生的破坏力更小、持续时间也更短。
08
持续改善
在一个复杂的系统中运行微服务是具有挑战性的。Telltale 的智能监控和报警系统帮助Netflix的服务运营商提高可用性、减少人力,也让工程师们在晚上睡得更好。但这还不算完,Netflix还在不断探索新的算法来提高警报的准确性。
Netflix仍然在思考和评估对应用程序健康模型的改进。Netflix相信在服务日志和跟踪数据中存在着大量有用信息,以及使用更高分辨率的度量标准的好处。
在 Telltale 上扩展新的应用程序已经十分成熟了,但对于Netflix来说,肯定还有更好的启发模式来帮助运营商发现影响服务运行健康与否的诸多因素,而Netflix也需要继续改进其服务界面。
09
Telltale是简化了的应用程序监控系统
一个健康的、运行状况良好的 Netflix 服务系统是该平台用户得以休闲娱乐的保障,但将不同信号与健康模型实时地联系起来仍然是一个挑战。再加上数以千计的流媒体设备类型、不断发展的架构以及不断增长的内容生产生态系统,这个问题变得非常有趣。
翻译:Coco Liang

一切为了QoE

音视频服务追求的不仅是单纯QoS,而是用户最终的极致体验,本次LiveVideoStackCon 2020 北京站我们也将邀请讲师讨论体验质量方面的分析与探索,点击【阅读原文】可了解更多讲师及话题信息。

LiveVideoStackCon 2020 北京
2020年10月31日-11月1日
点击_【阅读原文】_了解更多详细信息
本文分享自微信公众号 - LiveVideoStack(livevideostack)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。