
近日,大规模图数据库HugeGraph宣布,正式发布图可视化分析平台 HugeGraph-Hubble v1.5 版本。该版本全面升级平台可视化工具,打造一站式图服务,从数据建模,到数据快速导入,再到数据的在线、离线分析,以及图的统一管理,实现了图应用全流程的向导式操作,旨在提升社区用户的使用顺畅度,降低使用门槛,提供更为高效易用的使用体验。
HugeGraph是一款面向分析型,支持批量操作的图数据库系统,它由百度安全团队自主研发,全面支持Apache TinkerPop 3 框架和Gremlin图查询语言,提供导出、备份、恢复等完善的工具链生态,有效解决海量图数据的存储、查询和关联分析需求。HugeGraph先后应用于百度安全的网址安全检测、威胁情报分析、设备关系图谱和数据安全治理等重要业务中,并以此为基础,逐步扩展完善成为可以支持广泛图数据库需求场景的成熟通用图数据库,并于2018年8月在GitHub上对外开源。
据悉,此次发布版本重点在图分析可视化工具上进行了升级,具体包括:
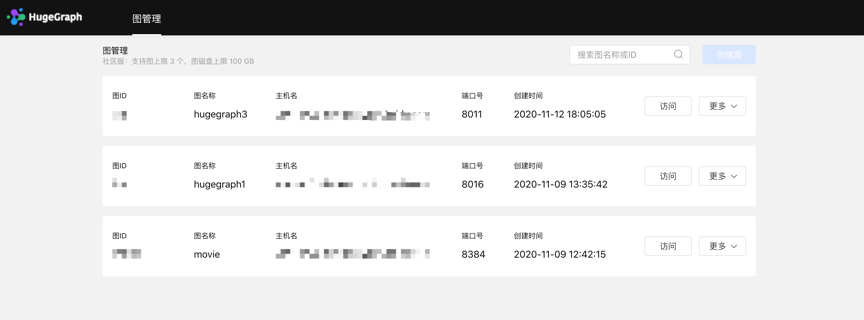
1 统一图管理
统一的图管理模块,通过简单的图连接、图访问、图删除操作,轻松实现图的集成管理及多图间的任意切换。
2 元数据建模
长久以来,市面上大多数图数据库,都是通过编写配置文件、建模文件等编写代码的方式来实现图数据建模,整个过程繁琐杂乱,错误率极高,也成为了图数据库大规模应用的一大难点。尤其是发生了单点的改动时,需要对整个文件进行修改,牵一发而动全身,可扩展性差,对使用人员的代码能力要求高,业务人员往往无法轻易上手。
为此,在新版中上线了可视化元数据建模功能,大大改善了这一问题,让数据建模变得轻而易举。通过可视化地图建模过程和简单易懂的点选操作,轻松实现顶点类型、边类型、属性类型等图模型的构建,极大地提升了成功率,降低了使用门槛。平台提供两种模式,列表模式和图模式,方便用户直观建模。同时还提供跨图的元数据复用,省去相同元数据繁琐的重复创建过程,极大地提升建模效率,增强易用性。
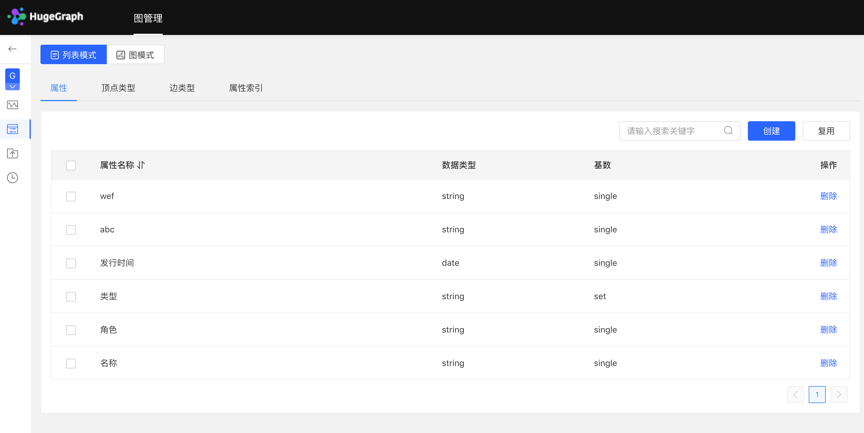
元数据列表模式如下图所示:
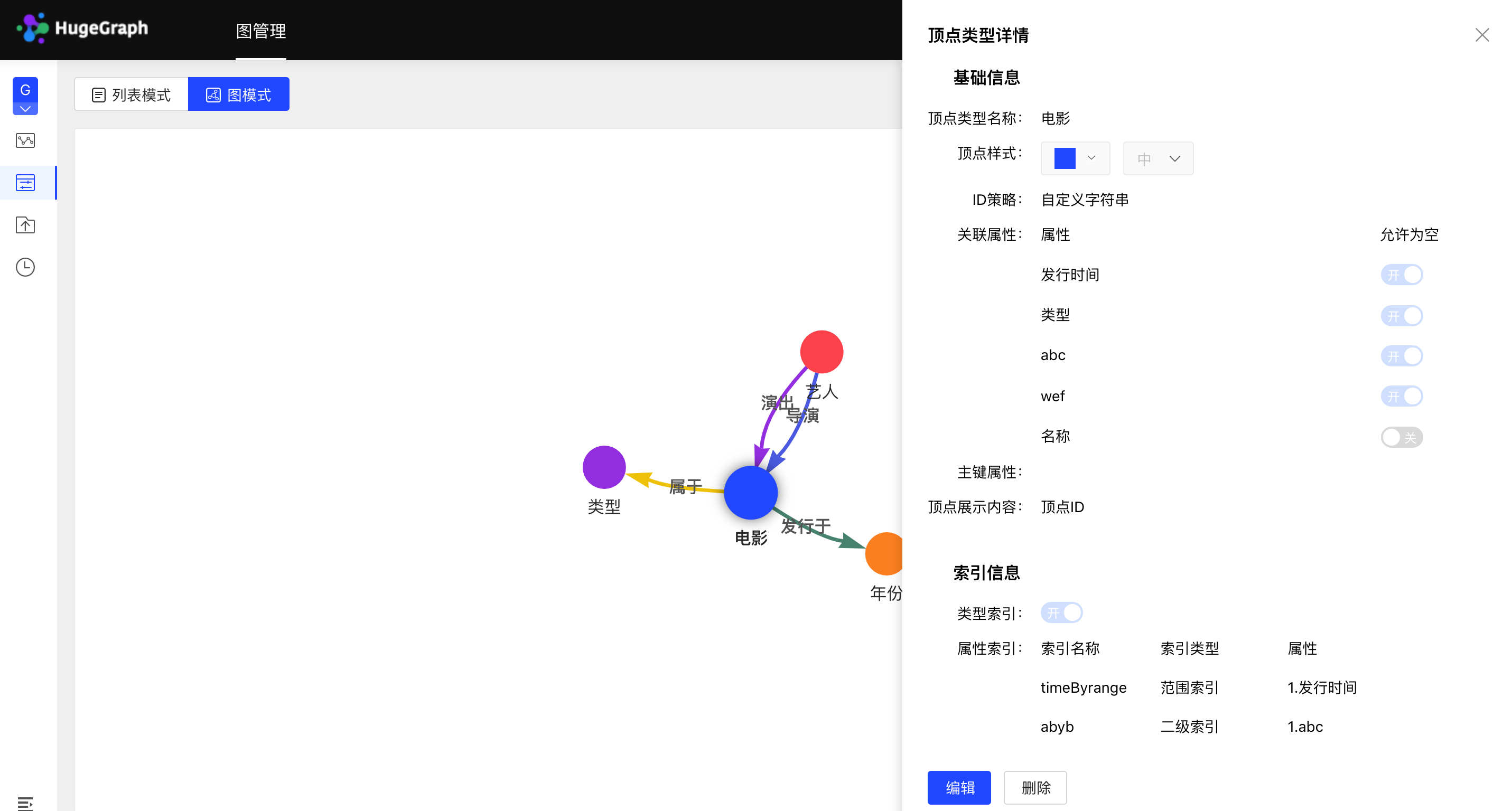
元数据图模式如下图所示:
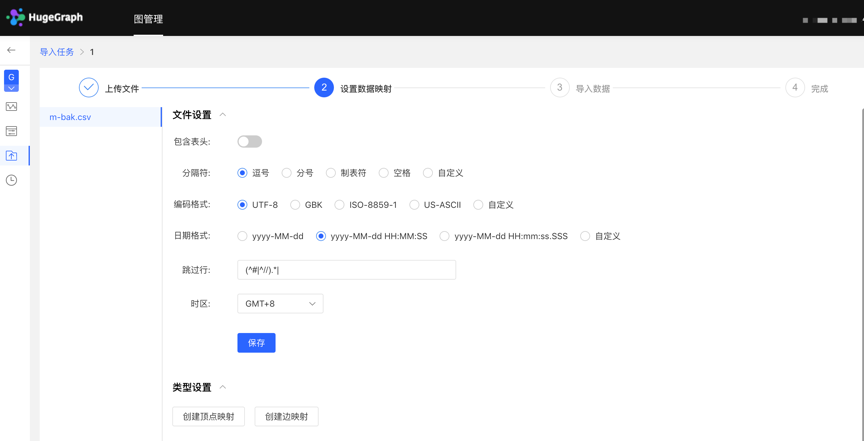
3 数据导入
数据的导入是使用图过程中极其关键的一步,它将用户的业务数据转化为图的顶点和边并插入图数据库中。目前导入过程采用编写映射文件的方式,使用门槛高,形式不直观,发生变更时操作繁复,存在着与上述建模过程类似的问题。此次的新版本中,上线了向导式的可视化导入模块,降低了图使用的门槛。通过创建导入任务,实现导入任务的管理及多个导入任务的并行运行,提高导入效能。进入导入任务后,只需跟随平台步骤提示,按需上传文件,填写内容,即可轻松实现图数据的导入过程,同时支持断点续传,发生错误重试机制等,降低了导入成本,提升了效率。
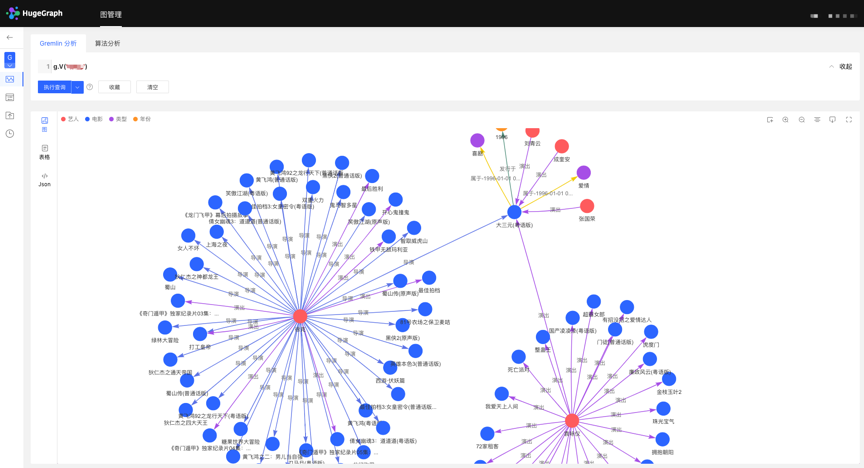
4 数据分析
在图分析模块,新版本实现了跨图的切换访问分析、通用的Gremlin查询、顶点的定制化多维路径查询等功能。能够为社区用户提供更直观炫酷的图渲染,并支持多种图展示方式,和完善的图导出工具。同时,新增了执行操作记录、查询语句收藏等功能,可以实现图分析的追溯与图查询的复用,真正提高查询效率,降低开发者使用成本。
5 任务管理
对于需要遍历全图的Gremlin任务、索引的创建与重建等耗时较长的异步任务,平台提供相应的任务管理功能,实现异步任务的统一的管理与结果查看。
- 关于HugeGraph -
HugeGraph自开源以来,已经过11个版本的迭代,项目陆续集成了数据导入、命令行操作、RESTFul API、Client、可视化等一系列工具集。在社区合作方面,截至目前,项目Star数达1400+,Issue数近900,社区活跃,欢迎大家积极参与到Github Issue讨论中,帮助社区开发者,共同推动项目更加完善。同时,HugeGraph也在2019年正式对外提供商业服务,逐步将图技术向金融风控领域、保险理赔领域、推荐搜索领域、公 安领域、知识图谱领域、网络安全领域、IT运维领域等更广泛的行业扩展,真正将图数据的价值落地到企业。
伴随全球范围内的人工智能革命,数据呈现爆炸式增长,企业能否利用好海量数据,关系着企业的发展。未来,秉承“有AI,更安全”的使命,以技术开源、专利共享、标准驱动、产业共赢为理念,百度安全还将继续在图数据领域上不断创新,不断丰富HugeGraph开源生态基础库和主要功能组件,活跃社区生态,切实推动图的落地应用,让更多行业和组织享受到数据的综合价值。
欢迎广大社区开发者体验新版本,下载链接:











