
1. 词
中文中,常规的词一般直接由分词工具切割开,如工具包结巴分词,组成短语,一些情况下也可以用单个字表示。英文中的词比较常见的是单个词,也有些情况会使用英文词组
1.1 词的预处理
一般情况下,对于英文文本,首先需要转换时态,三单这种词语的变换,首部大写字母转换小写,有时还需要对单词进行拼写检查。
1.2 停用词
对于中英文文本都存在停用词现象。停用词指非常常见的词但却没有实在意义的那一堆词,通常通过构建停用词表进行滤除。英文中比较典型的就是“is”,中文中为“的”这样的词。是否滤除停用词视情况而定,对于文本分类,相似度检验问题建议滤除,否则会发现所有文本相似度好像都很高的样子。
1.3 词向量
词向量是一种比较常用的对词进行编码的一种手段。比较常见的就one-hot 编码,word2vec,glove的方法,最近还出了一种fasttext的方法,也可以尝试用一用。One-hot的方法很容易把维度增大,因为字典有多少个他就有多少维,而后面的方法实际上是可以控制词向量维度的,一般控制在300维以内。词向量的基本可理解为这个词包含了多少语义信息,需要自己训练的话语料库尽量越大越好,如果自己的语料库本身就很小还是直接拿预训练的词向量进行训练吧,一般是有Wiki的预训练数据的。
1.4 主题特征
文本中的一些词可能表示为一个一样事物,这个时候使用主题特征把这些词归纳一下,构成新的特征,可能听的比较多的就是TF-IDF方法,直接根据词频,另外常见的还有LDA方法,需要自己定义有几个主题,而HDP方法则可以自己确定有多少主题。
1.5 词性特征
词性特征也称作POS。词性就是指的我们常说的名词动词形容词。通过常见的py包是可以直接提取出来的。
1.6 命名实体
命名实体也叫NER。一般如Stanfordnlp是直接包含了命名实体识别的检测,但仅限于如货币(美元,英镑),时间(分,秒)这样的常见类型。而很多情况下则需要根据自己的场景来提取命名实体,比如对文本中的生物标注是动物还是植物。需要特殊领域的只有自己训练了。
2.句法分析与语义分析
句法分析主要方法还是依靠调包。实现方法主要是规则+概率。一般句法分析出来以后一个单词会有两个属性,一个是指向他的单词的与他自己的位移,一个是他与这个单词的关系。每个词都有唯一的指向他的词
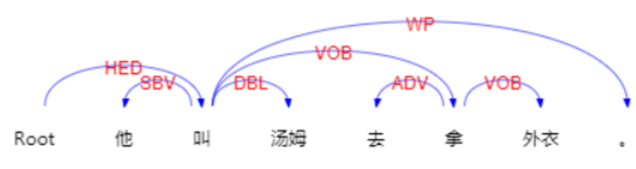
如图,来自https://www.ltp-cloud.com/demo/ 示例。这两种都可以算作特征。 同理,根据语义的依存关系,语义的关系会更多一些,还是根据场景选择。如图为语义分析示例

这两张图都出现了一个root,这个root是额外补充的。可以声明句子中心(一般为动词)
- nlp 中可以使用的一些常用套路
3.1 夹角
夹角一般使用余弦值计算,距离计算的方法还有很多,就不一一列举了。一般用来测量文本之间的相似度,短文本,长文本均适用,但具体需要怎样处理特征,就需要自己考虑了
3.2 n-gram方法
N-gram 方法就是指当前词的上下位的词,可以看作一个大小为n的窗口在文本上滑动,比如当n等于2,上图中的句子依次读出来就是 他叫 叫汤姆 汤姆去 去拿 拿外衣。以此类推,n为3时就是窗口为3,一般n取到4就不取了。同样,根据上文所说的,词性,句法,也可以根据ngram的方法对特征进行扩充
3.3 cnn方法
Cnn方法就是常说的卷积神经网络。对于文本来说,只有1维,在keras里适用Conv1。这里的输入一般为一段文本,文本中每一个词对应一组一维向量。对于特征明显的文本有奇效
3.4LSTM方法
LSTM方法是一种记忆性神经网络,为rnn进化型,衍生还有gru也比较常看到lstm训练较慢,gru会快一点。输入方法与cnn一样。一般使用前后向的LSTM叠加会舒服一些。
以上为个人总结,若有不当欢迎指出。Emm。。。如果想到别的了再补充。。。












