
TiDB 是 PingCAP 公司自主研发的开源分布式关系型数据库 TiDB,为企业关键业务打造,具备「分布式强一致性事务、在线弹性水平扩展、故障自恢复的高可用、跨数据中心多活」等核心特性,助力企业最大化发挥数据价值,释放企业增长空间。
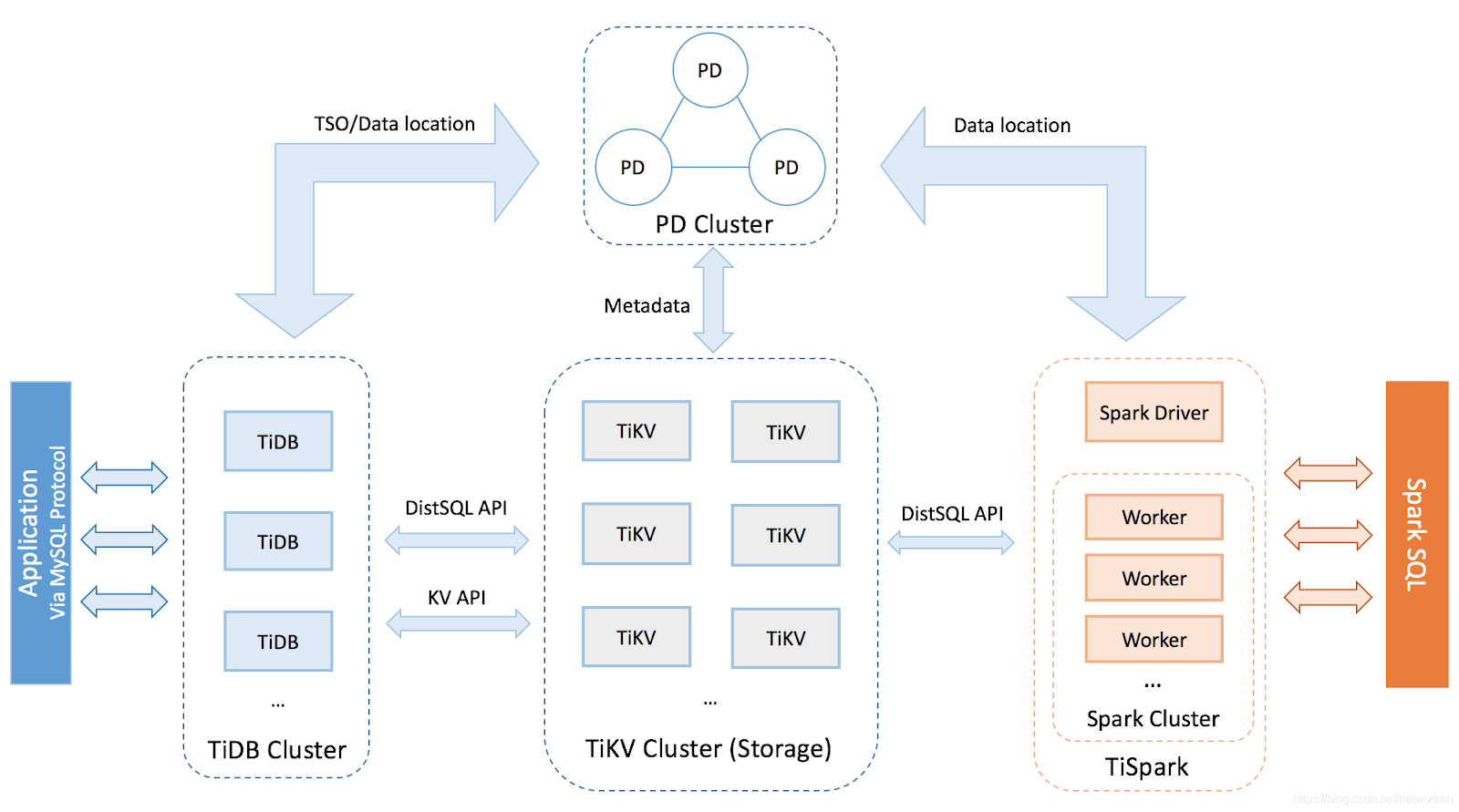
KubeSphere 是在 Kubernetes 之上构建的以应用为中心的多租户容器平台,完全开源,支持多云与多集群管理,提供全栈的 IT 自动化运维的能力,简化企业的 DevOps 工作流。KubeSphere 提供了运维友好的向导式操作界面,帮助企业快速构建一个强大和功能丰富的容器云平台。

本文将介绍如何在 KubeSphere 上部署 TiDB。
部署环境准备
KubeSphere 是由青云 QingCloud 开源的容器平台,支持在任何基础设施上安装部署。在青云公有云上支持一键部署 KubeSphere(QKE)。
下面以在青云云平台快速启用 KubeSphere 容器平台为例部署 TiDB 分布式数据库,至少需要准备 3 个可调度的 node 节点。你也可以在任何 Kubernetes 集群或 Linux 系统上安装 KubeSphere,可以点击【阅读原文】参考KubeSphere 官方文档。
1. 登录青云控制台:https://console.qingcloud.com/,点击左侧容器平台,选择 KubeSphere,点击创建并选择合适的集群规格:
2. 创建完成后登录到 KubeSphere 平台界面:
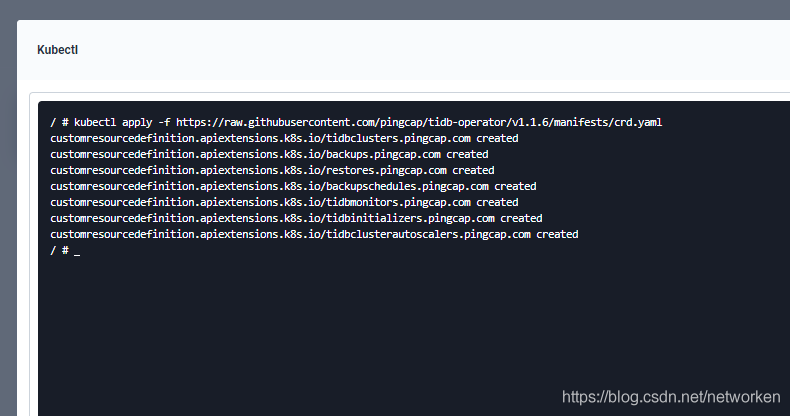
3. 点击下方的 Web Kubectl 集群客户端命令行工具,连接到 Kubectl 命令行界面。执行以下命令安装 TiDB Operator CRD:
kubectl apply -f https://raw.githubusercontent.com/pingcap/tidb-operator/v1.1.6/manifests/crd.yaml
4. 执行后的返回结果如下:
5. 点击左上角平台管理,选择访问控制,新建企业空间,这里命名为 dev-workspace
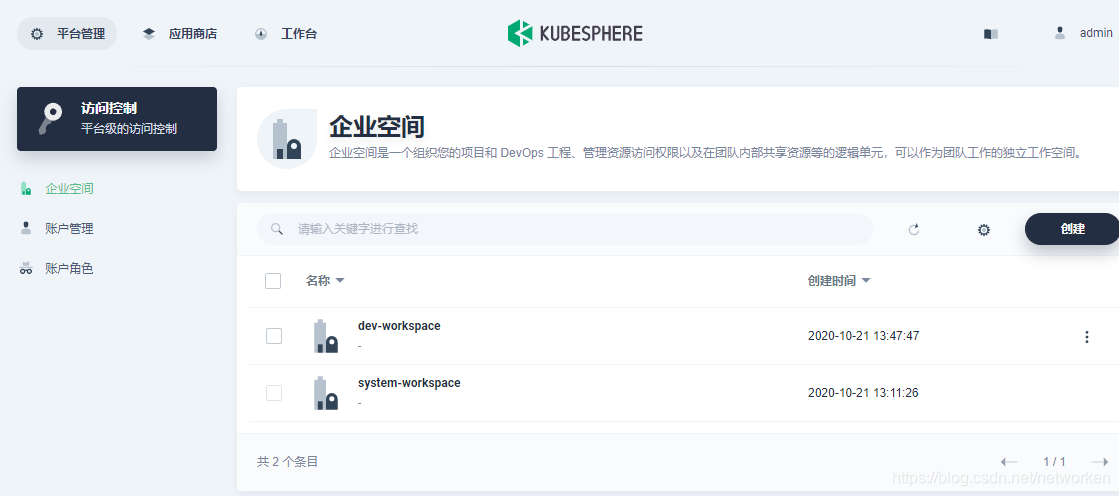
6. 进入企业空间,选择应用仓库,添加一个 TiDB 的应用仓库:
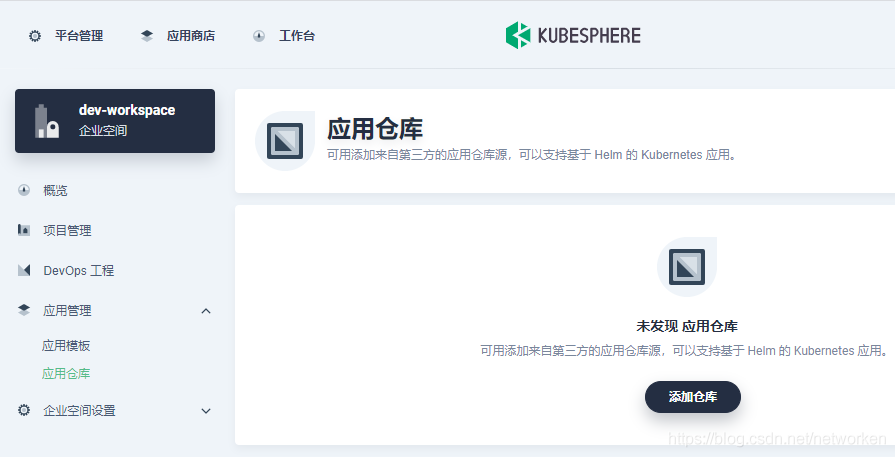
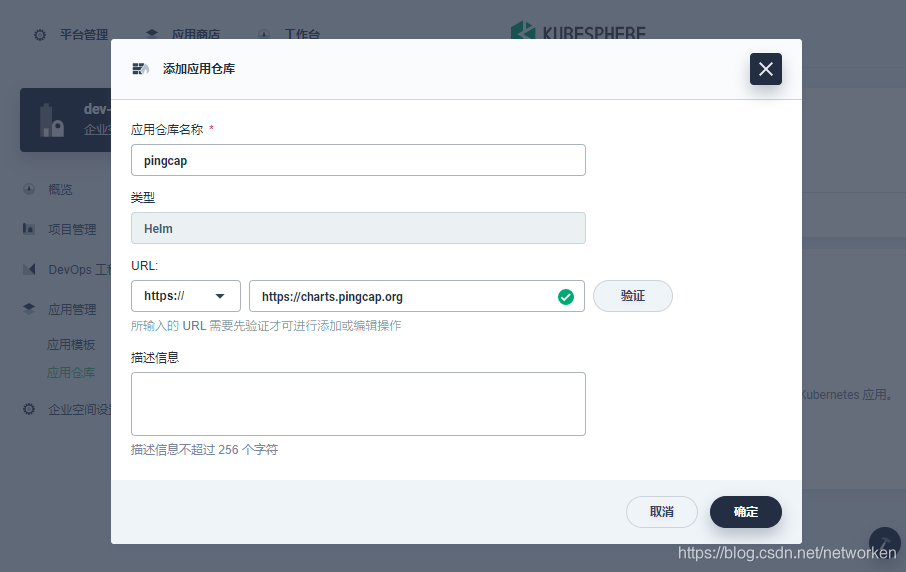
7. 将 PingCAP 官方 Helm 仓库添加到 KubeSphere 容器平台,Helm 仓库地址如下:
8. 添加方式如下:
部署 TiDB-Operator
1. 首选创建一个项目(namespace)用于运行 TiDB 集群:
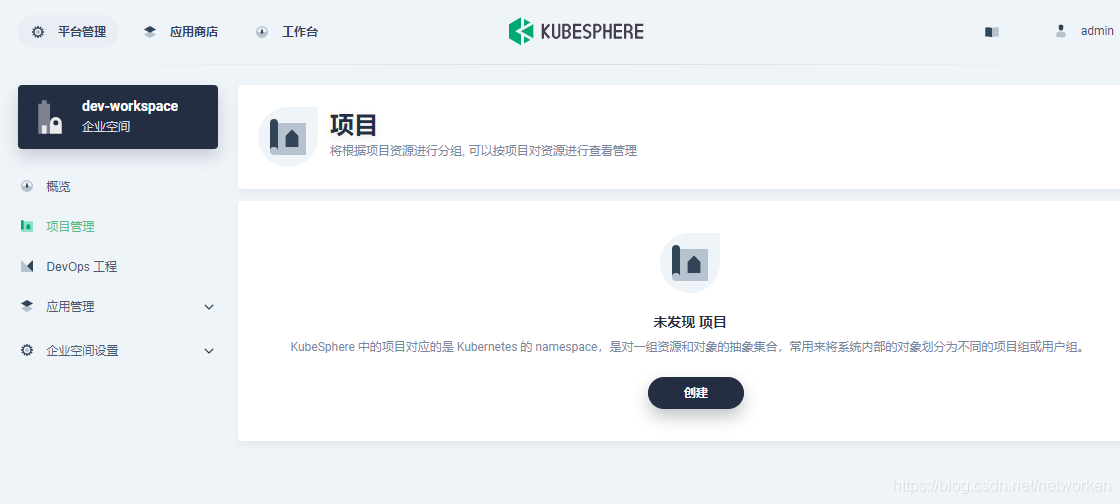
2. 创建完成后点击进入项目,选择应用,部署新应用:

3. 选择来自应用模板:
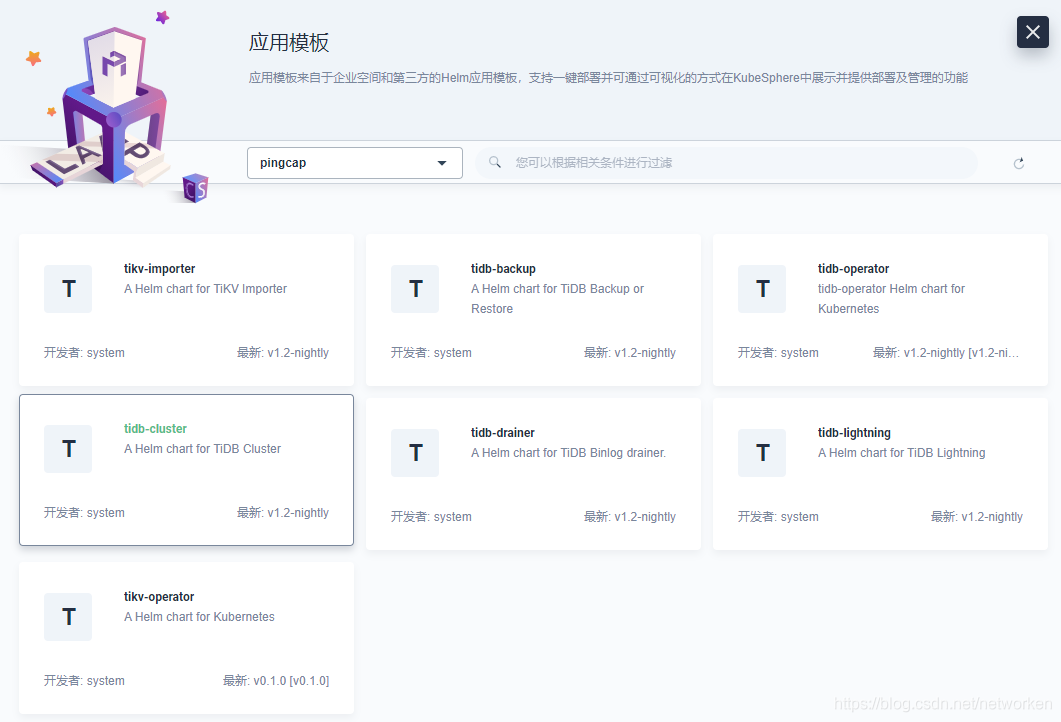
4. 选择 PingCAP,该仓库包含了多个 Helm Chart,当前主要部署 TiDB Operator 和TiDB Cluster。

5. 点击TiDB Operator 进入 Chart 详情页,点击配置文件可查看或下载默认的 values.yaml,选择版本,点击部署:
6. 配置应用名称并选择应用版本,确认应用部署位置:
7. 继续下一步,该步骤可以在界面直接编辑 values.yaml 文件,自定义配置,当前保留默认即可:
8. 点击部署,等待应用状态变为活跃:
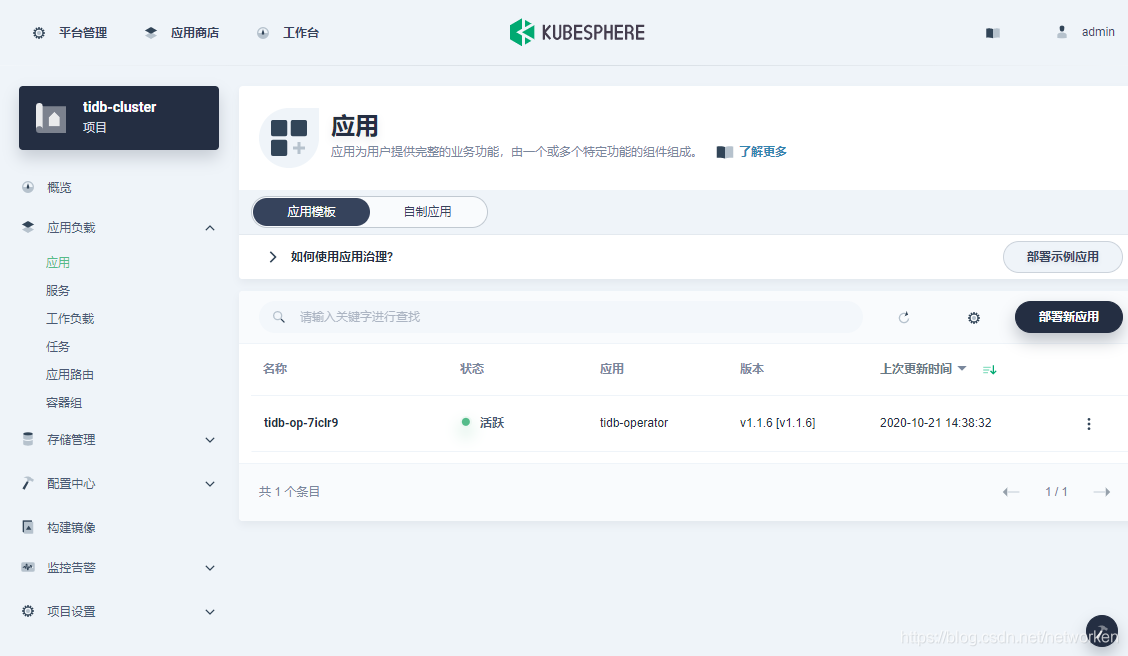
9. 点击工作负载(Deployment),查看TiDB Operator 部署了 2 个 Deployment 类型资源:
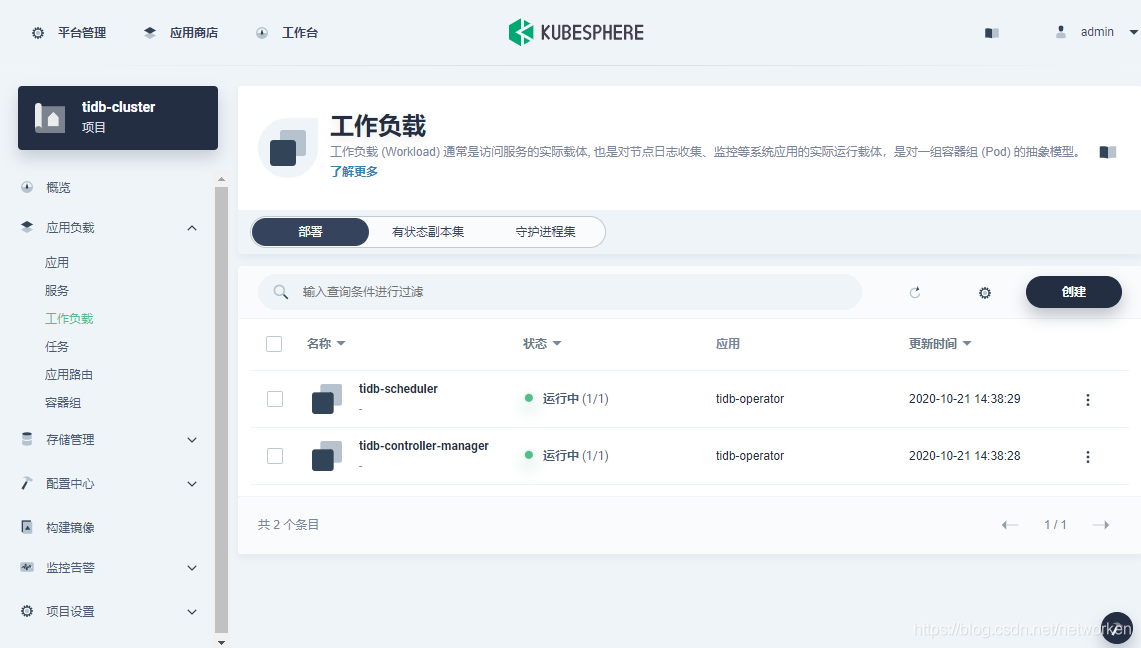
部署 TiDB-Cluster
1.TiDB Operator 部署完成后,可以继续部署TiDB Cluster。与部署TiDB Operator 操作相同,选择左侧应用,点击TiDB Cluster:
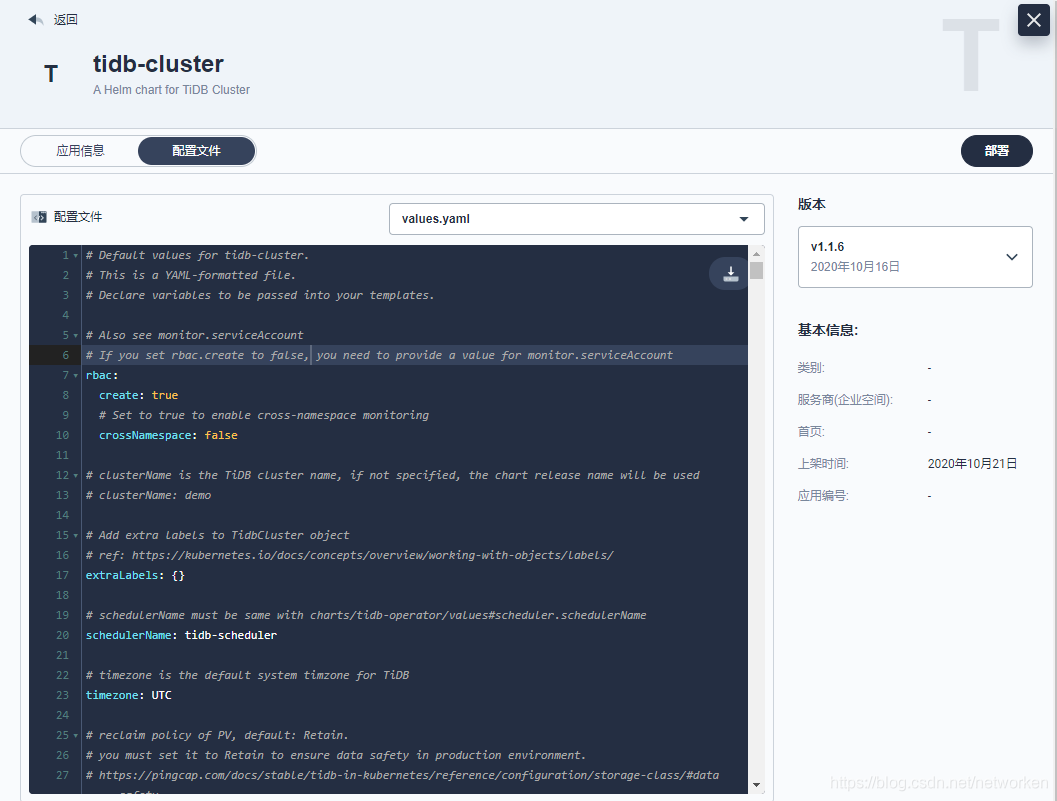
2. 切换到配置文件,选择版本,下载 values.yaml 到本地:
3. TiDB Cluster 中部分组件需要持久存储卷,青云公有云平台提供了以下几种类型的 StorageClass:
/ # kubectl get sc
NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE
csi-high-capacity-legacy csi-qingcloud Delete Immediate true 101m
csi-high-perf csi-qingcloud Delete Immediate true 101m
csi-ssd-enterprise csi-qingcloud Delete Immediate true 101m
csi-standard (default) csi-qingcloud Delete Immediate true 101m
csi-super-high-perf csi-qingcloud Delete
4. 这里选择 csi-standard 类型,values.yaml 中的 StorageClassName 字段默认配置为 local-storage。因此,在下载的 yaml 文件中直接替换所有的 local-storage 字段为 csi-standard。在最后一步使用修改后的 values.yaml 覆盖应用配置文本框中的内容,当然也可以手动编辑配置文件逐个替换:
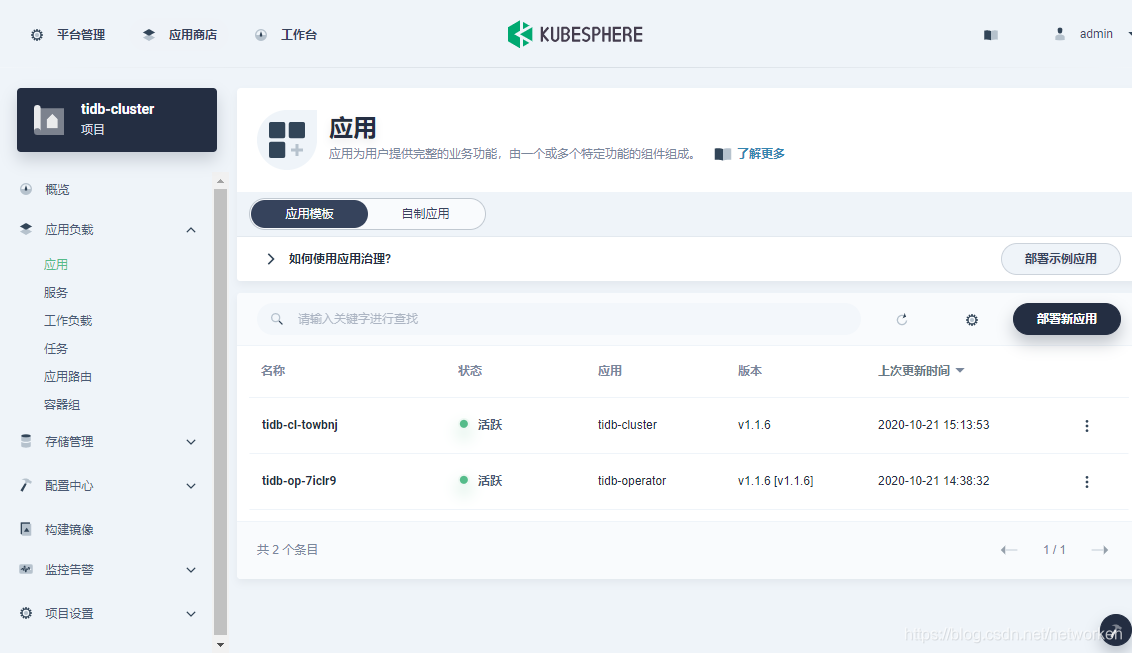
5. 这里仅修改 storageClassName 字段用于引用外部持久存储,如果需要将TiDB、TiKV 或 PD 组件调度到独立节点,可参考 NodeAffinity 相关参数进行修改。点击部署,将TiDB Cluster 部署到容器平台,最终在应用列表中可以看到如下 2 个应用:
查看 TiDB 集群监控
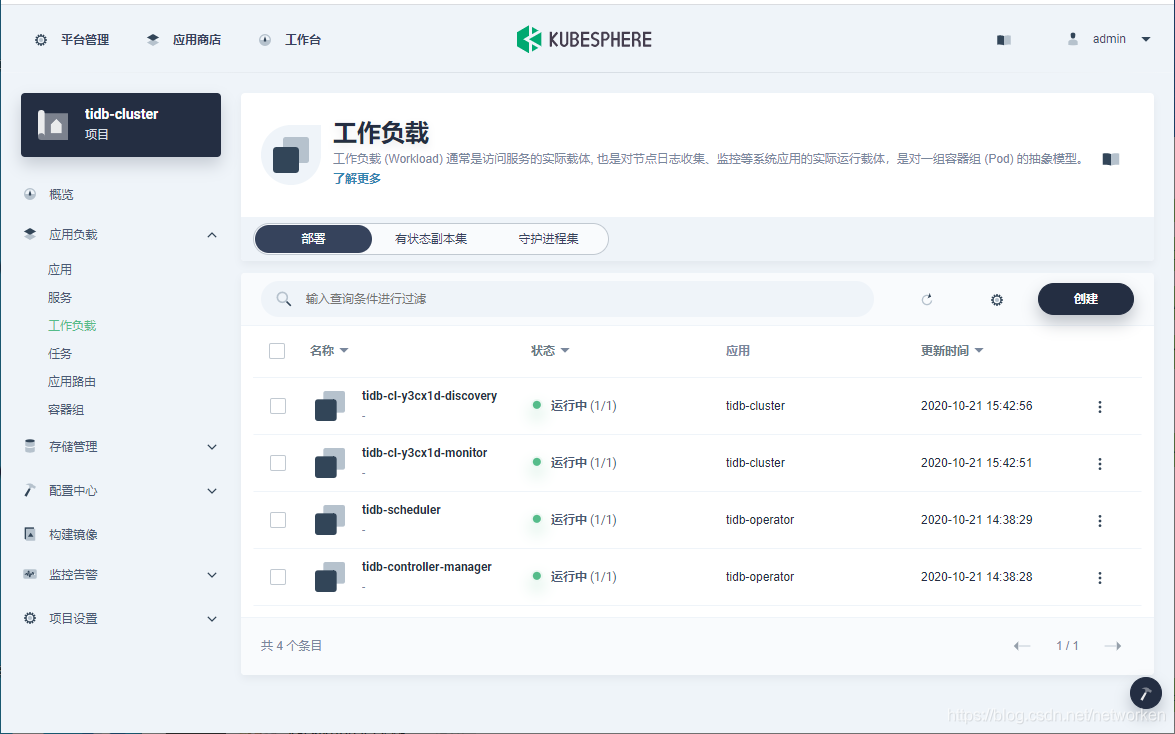
1. TiDB 集群部署后需要一定时间完成初始化,选择工作负载,查看 Deployment 无状态应用:
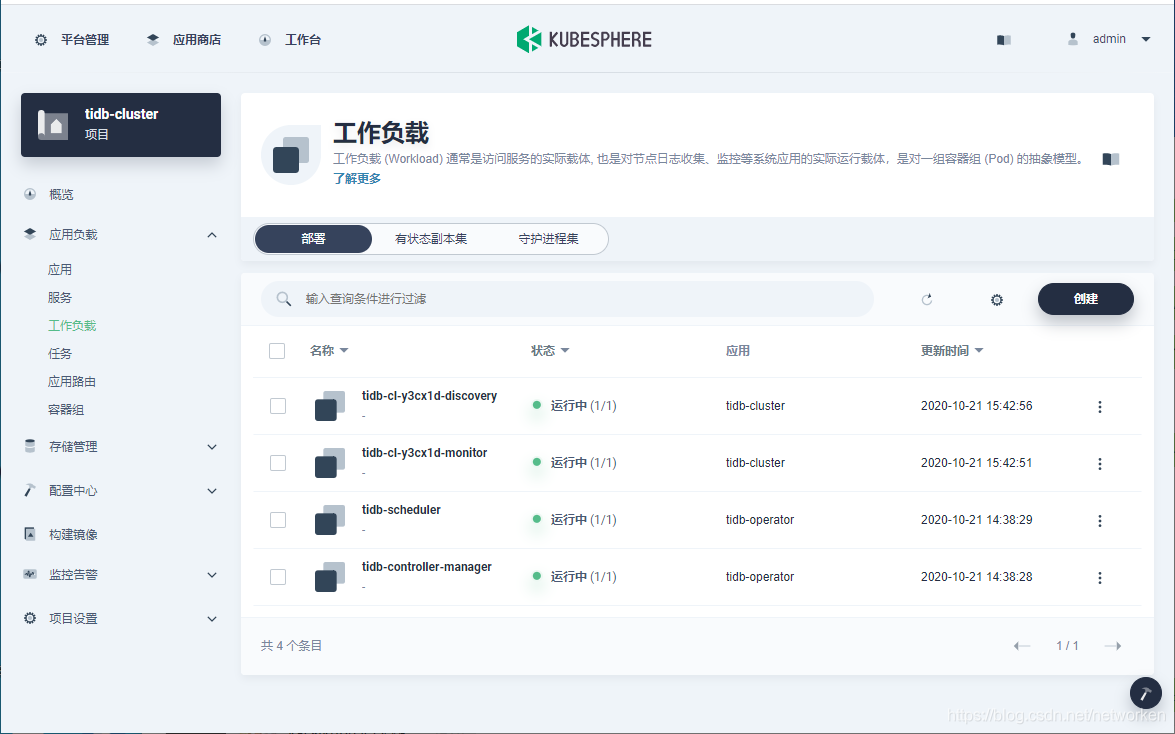
2. 查看有状态副本集(StatefulSets),其中TiDB、TiKV 和 PD 等组件都为有状态应用:
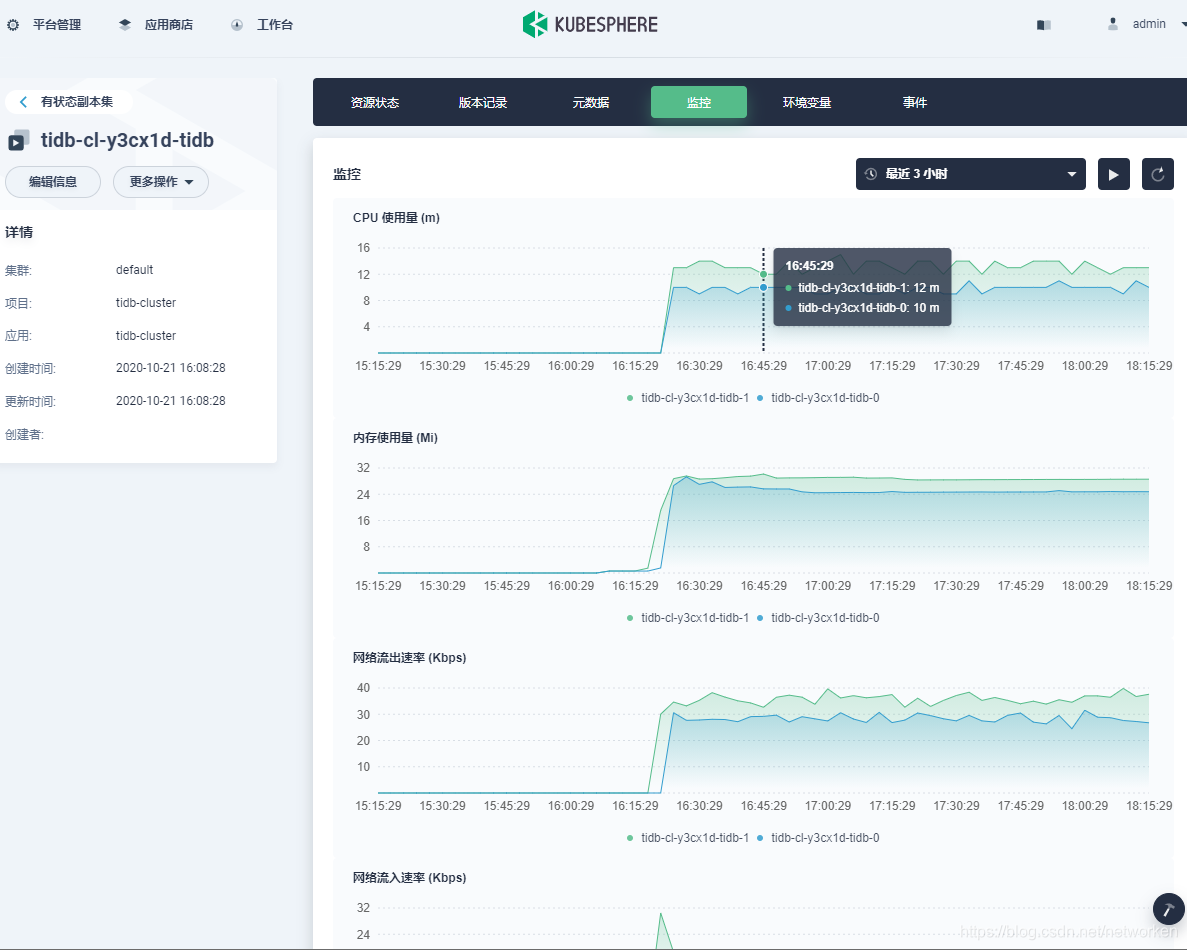
3. 在 KubeSphere 监控面板查看TiDB负载情况,可以看到 CPU、内存、网络流出速率有明显的变化:
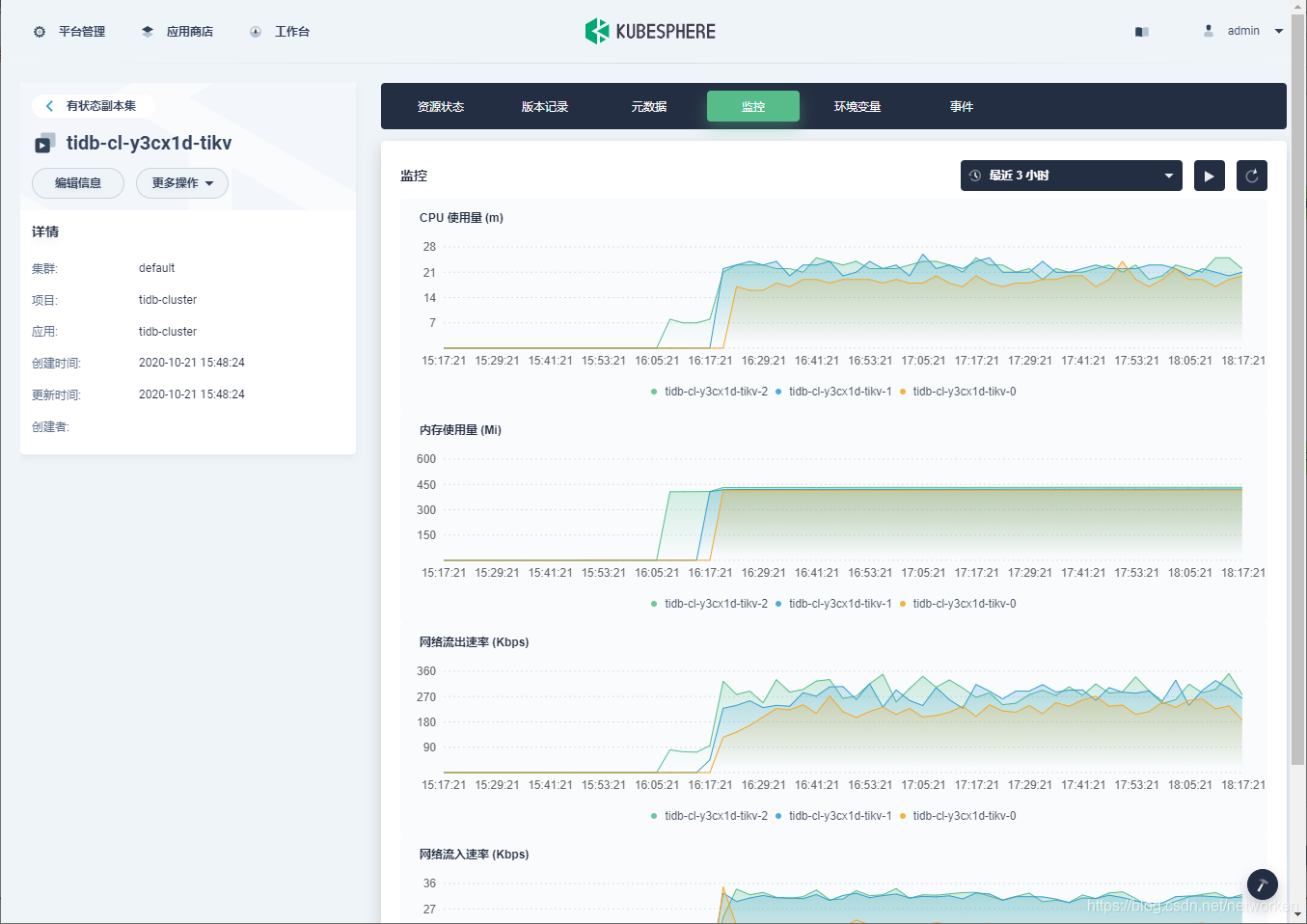
4. 在 KubeSphere 监控面板查看 TiKV 负载情况:
5. 查看容器组(Pod)列表,TiDB集群包含了 3 个 PD、2 个TiDB以及 3 个 TiKV 组件:
6. 点击存储管理,查看存储卷,其中 TiKV 和 PD 这 2 个组件使用了持久化存储:
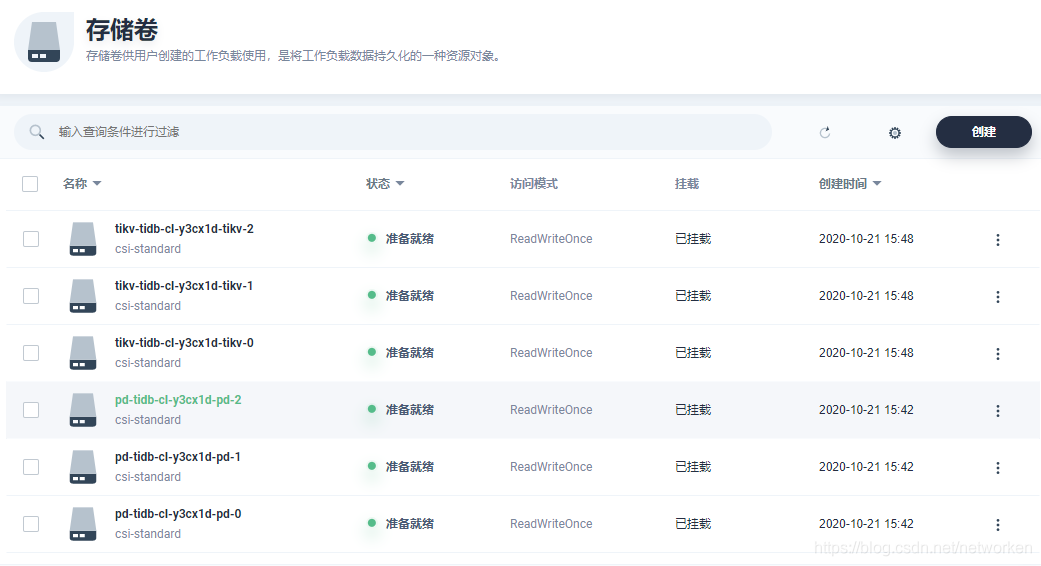
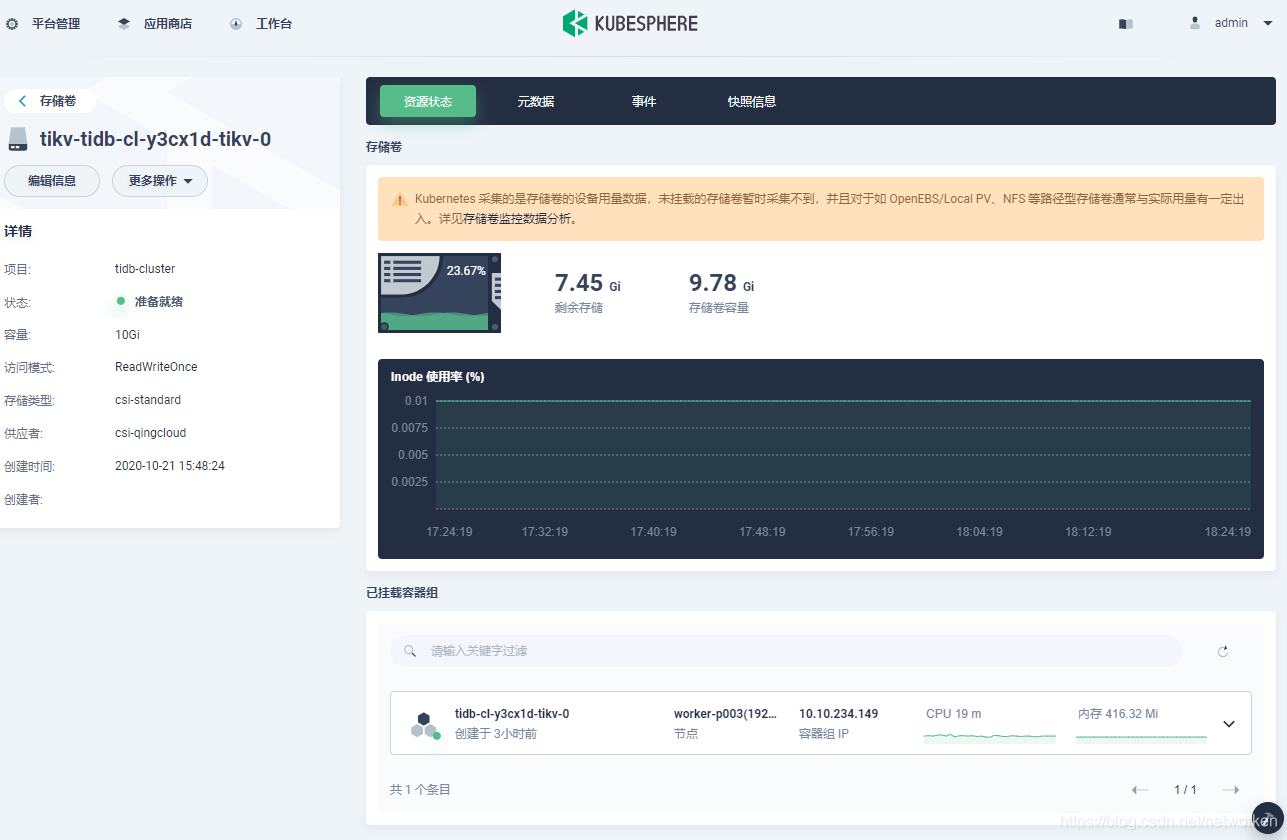
7. 查看某个存储卷用量信息,以 TiKV 为例,可以看到当前存储的存储容量和剩余容量等监控数据。
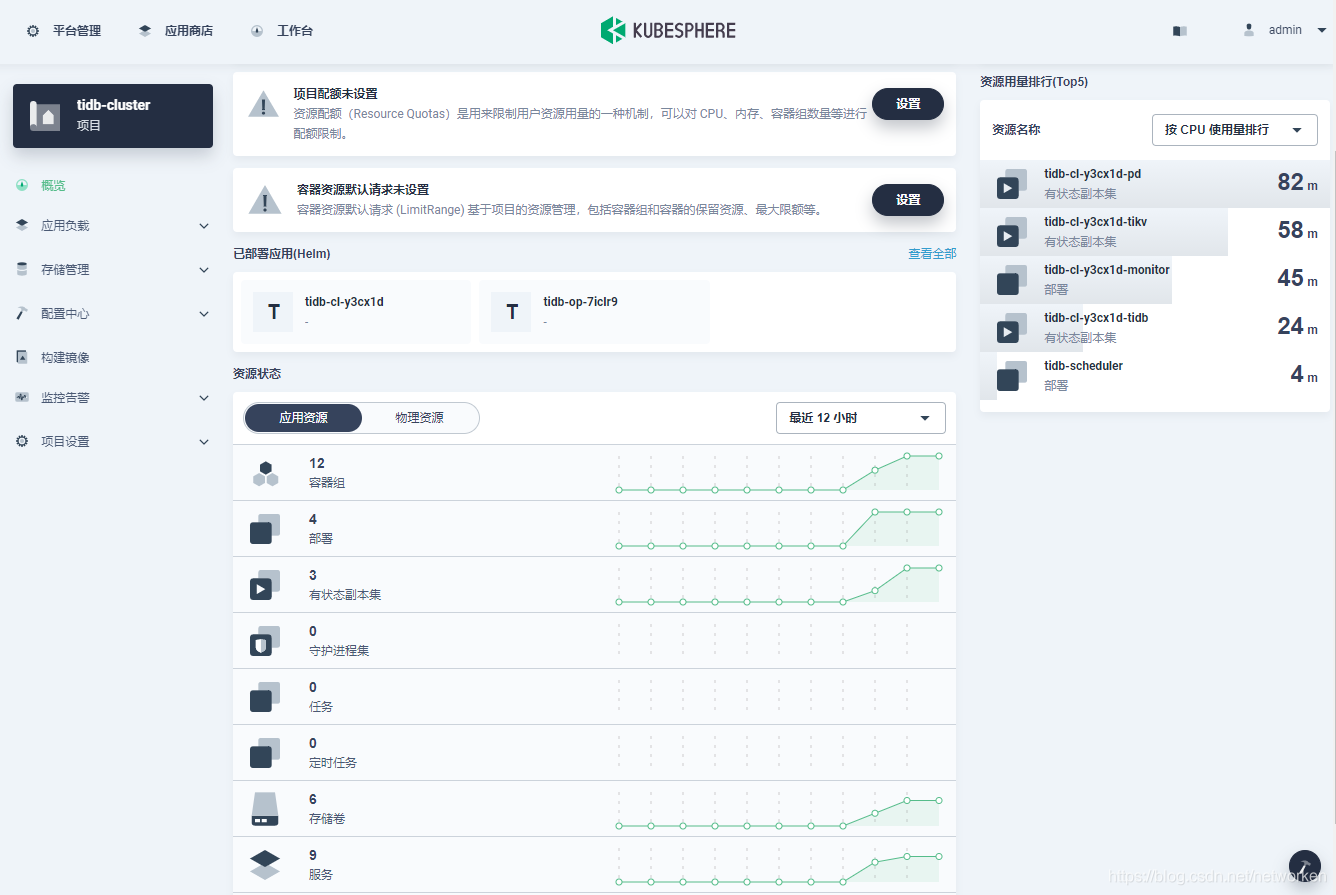
8. 在 KubeSphere 项目首页查看TiDB Cluster 项目中资源用量排行:
访问 TiDB 集群
1. 点击左侧服务,查看 TiDB 集群创建和暴露的服务信息。
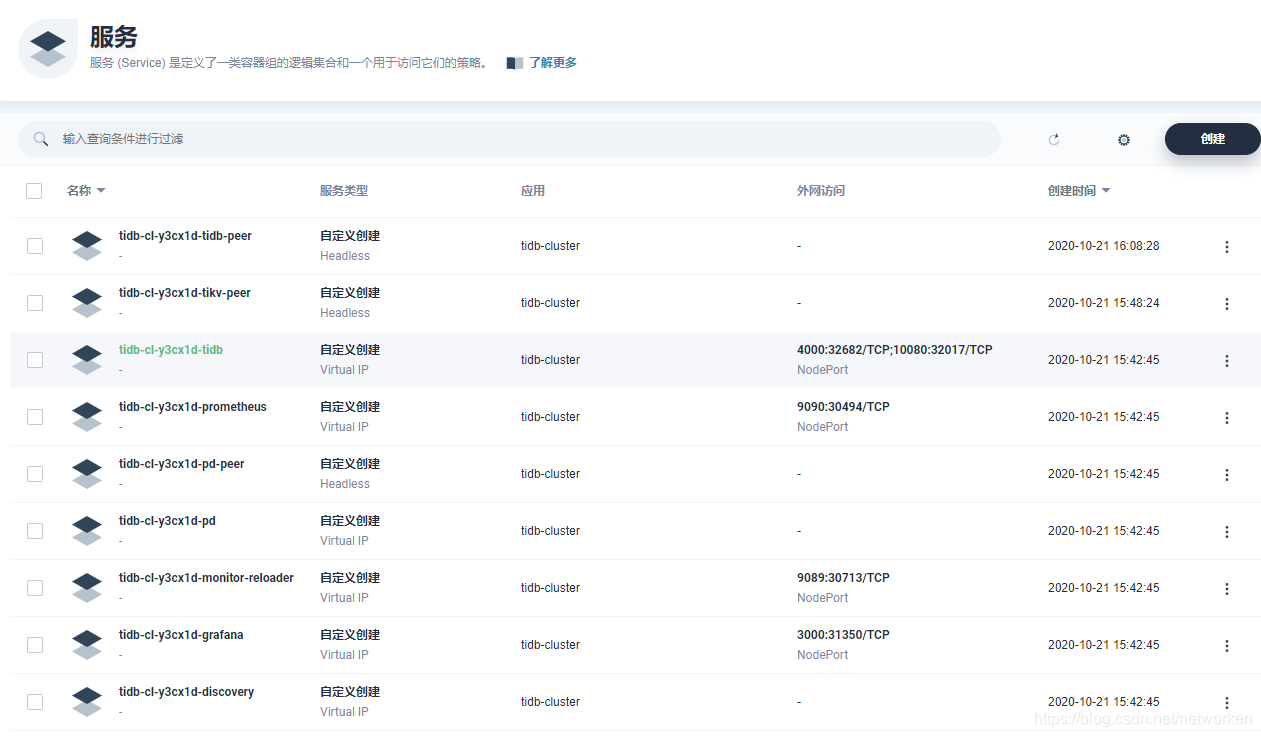
2. 其中 TiDB 服务 4000 端口绑定的服务类型为 NodePort,直接可以在集群外通过 nodeIP 访问。测试使用 MySQL 客户端连接数据库。
[root@k8s-master1 ~]# docker run -it --rm mysql bash
[root@0d7cf9d2173e:/# mysql -h 192.168.1.102 -P 32682 -u root
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 201
Server version: 5.7.25-TiDB-v4.0.6 TiDB Server (Apache License 2.0) Community Edition, MySQL 5.7 compatible
Copyright (c) 2000, 2020, Oracle and/or its affiliates. All rights reserved.
Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| INFORMATION_SCHEMA |
| METRICS_SCHEMA |
| PERFORMANCE_SCHEMA |
| mysql |
| test |
+--------------------+
5 rows in set (0.01 sec)
mysql>
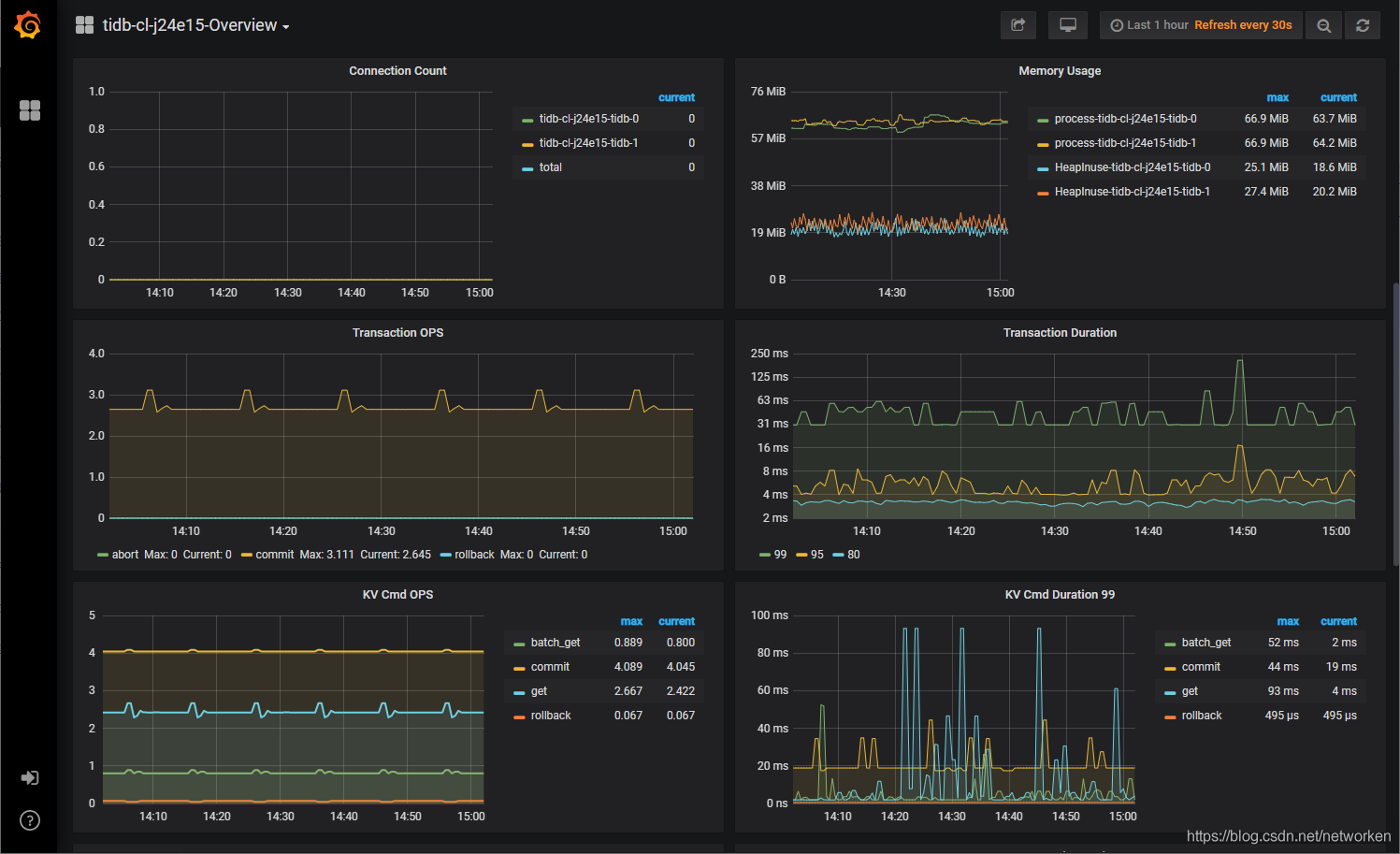
查看 Grafana 监控面板
另外,TiDB 自带了 Prometheus 和 Grafana,用于数据库集群的性能监控,可以看到 Grafana 界面的 Serivce 3000 端口同样绑定了 NodePort 端口。访问 Grafana UI,查看某个指标:
总结
KubeSphere 容器平台对于云原生应用部署非常友好,对于还不熟悉 Kubernetes 的应用开发者而又希望通过在界面简单配置完成 TiDB 集群的部署,可以参考以上步骤快速上手。我们将在下一期的文章中,为大家分享另一种部署玩法:将 TiDB 应用上架到 KubeSphere 应用商店实现真正的一键部署。
另外,TiDB 还可以结合 KubeSphere 的多集群联邦功能,部署 TiDB 应用时可一键分发 TiDB 不同的组件副本到不同基础设施环境的多个 Kubernetes 集群,实现跨集群、跨区域的高可用。如果大家感兴趣,我们将在后续的文章中为大家分享 TiDB 在 KubeSphere 实现多集群联邦的混合云部署架构。












