
接触redis并不久,做项目的时候,也大概的操作罢了,比如set,get..~等等的基础操作,大概小喽啰是够用了
最近大佬问我,你的redis数据有做持久化吗?
我的想法..~ 设置了有效时间的key是未持久化的,永久的key就是持久化的
大佬一个劲的在嘲笑,尴尬... 偷偷笑,有我这么想.肯定还有人起步也这么认为的,哈哈哈
于是学习一下redis 持久化相关知识
Redis之所以速度这么快,是因为Redis是基于内存的数据库,进行读写操作时,redis都会在内存中完成,然后定时的刷新到磁盘中去,RDB和AOF就是两种持久化内存中数据的方式
在硬盘中数据是持久化的,重启机子也会存在
在内存中数据不是持久化的,重启机子就没了
根据一段自己写的redis操作的代码来学习,这边使用的是Jedis(Java连接开发工具),来一段最简单的set
/**
* set 字节数组
*
* @param key 字节key
* @param value 字节value
* @return OK
*/
public String set(byte[] key, byte[] value) {
Jedis jedis = null;
String result = null;
try {
jedis = getJedis();
result = jedis.set(key, value);
} catch (Exception e) {
log.error("set byte[] key:{} value:{} error", key, value, e);
} finally {
returnSource(jedis);
}
return result;
}
快照存储 RDB(redis db)
redis 会把自身的数据以文件形式保存到硬盘中一份,在服务器重启之后会自动把硬盘数据恢复到内存中
操作是一次性把redis中全部的数据保存一份到硬盘中,所以如果数据大的话,不太适合频繁进行该操作
默认文件名dump.rdb 可以在redis.conf中设置
有三种方式触发快照
第1种. redis客户端发送的save命令进行快照,会阻塞(代码中需要调用jedis.save()的方法实现)
阻塞redis服务器的进程,直到RDB文件创建完,在该段时间内,redis不能处理其他的命令
第2种. redis客户端发送的bgsave命令,不阻塞(代码中需要调用jedis.bgsave()的方法实现)
实际执行过程:
- 客户端bgsave命令
- 服务端返回ok
- 服务端fork创建一个子进程来执行备份
- 子进程执行完之后通知redis
主进程和子进程是同时存在的, 不会阻塞redis服务器进程, 创建子进程会消耗额外的内存,所以bgsave比save要慢
第3种. redis根据redis.conf中的配置自动执行bgsave
save 900 1 #900秒之内修改了1次,则执行
save 300 10 #300秒之内修改了10次,则执行
save 60 10000 #60秒之内修改了10000次,则执行
服务器每次执行之后,为实现自动持久化而设置的时间计数器和次数计数器就会清零,重新计算
在redis命令执行config get save查看redis的save配置
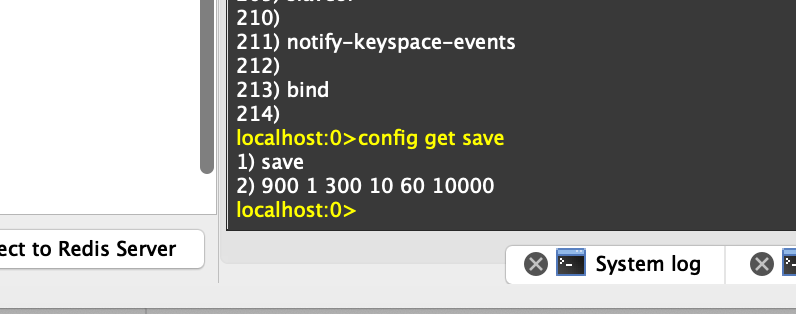
可用jedis.lastsave()命令查看生成RDB文件是否成功, 返回上次成功保存到磁盘的unix时间戳(save和bgsave都会修改时间) ,RDB文件每次都是覆盖,需要控制备份的话,要定时定点另存备份
从上面学习过程中,得出主动方式应该选择使用bgsave的方式来持久化
public void bgsave() {
Jedis jedis = null;
try {
jedis = getJedis();
jedis.bgsave();
} catch (Exception e) {
log.error("bgsave error", e);
} finally {
returnSource(jedis);
}
}
给自己的工具类加个bgsave持久化方法,另外尝试过程过遇到如果在一个Java方法中调两次save或者bgsave是会报错的,所以持久化单提出来,可能一个方法有好几个redis操作
总结:
1.bgsave子线程创建RDB文件,不会对redis服务器性能造成大的影响
2.快照生成的RDB文件是一种压缩的二进制文件,可以方便的在网络中传输和保存
3.在一次备份完RDB之后产生了新数据,但还未到达另一次生成RDB文件的条件,这时redis服务器宕机,那么新的数据会丢失掉
4.数据量大的时,触发RDB持久化,包括创建子线程和生成RDB文件会占不少系统资源和时间,会对redis产生影响
持久化AOF(append only file)
把操作执行的每个指令都备份到aof文件中,还原数据的时候执行指令 , 每次在后面追加
aop重写(不阻塞), redis.conf对应 appendonly yes 开启aof
appendfilename "appendonly.aof" //备份文件名
appendfsync always //每次收到写命令就立即写入磁盘,最慢的方式,但是保证完全的持久化
appendfsync everysec //每秒钟强烈写入磁盘一次,在性能和持久化方面很好的折中,默认
appendfsync no //不同步到硬盘,由操作系统来决定
aof生成过程三个步骤:redis在执行完一个写命令后,把执行的命令追加到redis内部的aof_buf缓冲区末尾
调用调用fsync函数, 缓冲区的写命令会被写入到 AOF 文件, 完成同步
在目前操作系统里,执行系统调用write函数,将一些内容写入到某个文件时, 先将内容放入一个内存缓冲区(buffer)里面,等到缓冲区被填满,或者用户执行fsync调用和fdatasync调用时才将存储在缓冲区里面的内容真正的写入到硬盘里,那么在这个过程中出问题了,数据是否就丢了?!
总结:
使用 AOF 持久化会让 Redis 变得非常耐久:你可以设置不同的 fsync策略,比如无 fsync,每秒钟一次 fsync ,或者每次执行写入命令时 fsync 。 AOF 的默认策略为每秒钟 fsync一次,在这种配置下,Redis 仍然可以保持良好的性能,并且就算发生故障停机,也最多只会丢失一秒钟的数据
aof文件因为某些原因而包含了未写入完整的命令redis-check-aof 工具也可以轻易地修复这种问题
Redis 可以在 AOF 文件体积变得过大时,自动地在后台对 AOF 进行重写: 重写后的新 AOF 文件包含了恢复当前数据集所需的最小命令集合。 整个重写操作是绝对安全的,因为 Redis 在创建新 AOF 文件的过程中,会继续将命令追加到现有的 AOF 文件里面,即使重写过程中发生停机,现有的 AOF 文件也不会丢失。 而一旦新 AOF 文件创建完毕,Redis 就会从旧 AOF 文件切换到新 AOF 文件,并开始对新 AOF 文件进行追加操作
AOF文件可读性交强,也可手动操作写命令
AOF文件比RDB文件较大
官方文档也指出,在某些情况下,AOF的确也存在一些bug,比如使用阻塞命令时,这些bug的场景RDB是不存在的
------------------------------------












