
Flink+Kafka整合实例
1.使用工具Intellig IDEA新建一个maven项目,为项目命名为kafka01。
2.我的pom.xml文件配置如下。
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.hrb.lhr</groupId>
<artifactId>kafka01</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<flink.version>1.1.4</flink.version>
<slf4j.version>1.7.7</slf4j.version>
<log4j.version>1.2.17</log4j.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- explicitly add a standard loggin framework, as Flink does not (in the future) have
a hard dependency on one specific framework by default -->
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>${slf4j.version}</version>
</dependency>
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>${log4j.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka-0.9_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
</dependencies>
</project>
3.在项目的目录/src/main/java在创建两个Java类,分别命名为KafkaDemo和CustomWatermarkEmitter,代码如下所示。
import java.util.Properties;
import org.apache.flink.streaming.api.TimeCharacteristic;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer09;
import org.apache.flink.streaming.util.serialization.SimpleStringSchema;
public class KafkaDeme {
public static void main(String[] args) throws Exception {
// set up the streaming execution environment
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//默认情况下,检查点被禁用。要启用检查点,请在StreamExecutionEnvironment上调用enableCheckpointing(n)方法,
// 其中n是以毫秒为单位的检查点间隔。每隔5000 ms进行启动一个检查点,则下一个检查点将在上一个检查点完成后5秒钟内启动
env.enableCheckpointing(5000);
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
Properties properties = new Properties();
properties.setProperty("bootstrap.servers", "10.192.12.106:9092");//kafka的节点的IP或者hostName,多个使用逗号分隔
properties.setProperty("zookeeper.connect", "10.192.12.106:2181");//zookeeper的节点的IP或者hostName,多个使用逗号进行分隔
properties.setProperty("group.id", "test-consumer-group");//flink consumer flink的消费者的group.id
FlinkKafkaConsumer09<String> myConsumer = new FlinkKafkaConsumer09<String>("test0", new SimpleStringSchema(),
properties);//test0是kafka中开启的topic
myConsumer.assignTimestampsAndWatermarks(new CustomWatermarkEmitter());
DataStream<String> keyedStream = env.addSource(myConsumer);//将kafka生产者发来的数据进行处理,本例子我进任何处理
keyedStream.print();//直接将从生产者接收到的数据在控制台上进行打印
// execute program
env.execute("Flink Streaming Java API Skeleton");
}
import org.apache.flink.streaming.api.functions.AssignerWithPunctuatedWatermarks;
import org.apache.flink.streaming.api.watermark.Watermark;
public class CustomWatermarkEmitter implements AssignerWithPunctuatedWatermarks<String> {
private static final long serialVersionUID = 1L;
public long extractTimestamp(String arg0, long arg1) {
if (null != arg0 && arg0.contains(",")) {
String parts[] = arg0.split(",");
return Long.parseLong(parts[0]);
}
return 0;
}
public Watermark checkAndGetNextWatermark(String arg0, long arg1) {
if (null != arg0 && arg0.contains(",")) {
String parts[] = arg0.split(",");
return new Watermark(Long.parseLong(parts[0]));
}
return null;
}
}
4.开启一台配置好zookeeper和kafka的Ubuntu虚拟机,输入以下命令分别开启zookeeper、kafka、topic、producer。(zookeeper和kafka的配置可参考https://www.cnblogs.com/ALittleMoreLove/p/9396745.html)
bin/zkServer.sh start
bin/kafka-server-start.sh config/server.properties
bin/kafka-topics.sh --create --zookeeper 10.192.12.106:2181 --replication-factor 1 --partitions 1 --topic test0
bin/kafka-console-producer.sh --broker-list 10.192.12.106:9092 --topic test0
5.检测Flink程序是否可以接收到来自Kafka生产者发来的数据,运行Java类KafkaDemo,在开启kafka生产者的终端下随便输入一段话,在IDEA控制台可以收到该信息,如下为kafka生产者终端和控制台。
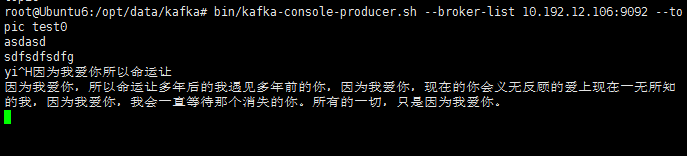
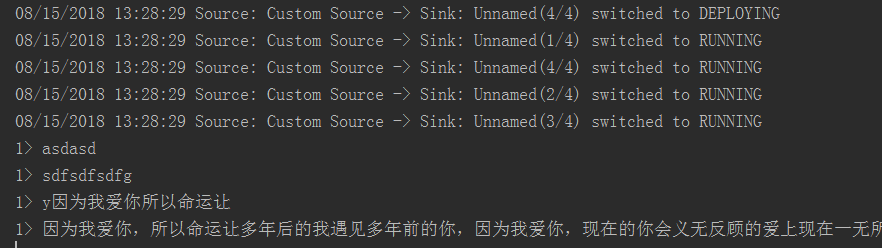
OK,成功的接收到了来自Kafka生产者的消息^.^。











