
#局部变量的实现
在字节码层面,每一个方法都有一个局部变量数组,用来存储当前方法的参数,在方法内声明的变量,如果是非静态方法还要存储当前方法实例的引用this。在我们平时使用java的时候,这个局部变量的大小是在源码编译成class的时候就确定了的,那么如何更高效的利用这个局部变量,并且合理分配每个变量对应在局部变量数组中的位置呢,下面我们就介绍ASMSupport是如何规划局部变量的,先看下面的代码。
代码1
public void method(boolean bool) {
int prefix = 1;
if(bool)
{
double d = 2.12;
String s = "string";
...
}
else
{
char c = 'a';
long l = 1L;
}
}
上面的的代码我们用作用域的方式表现出来如下图:
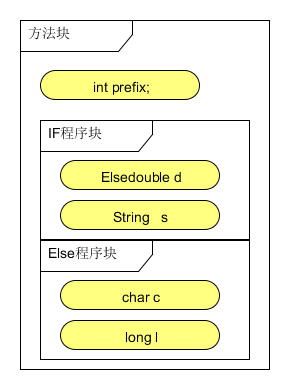
如果按照程序流程执行,很显然这里会有两种执行结果。分别是当bool为真的时候执行if语句块,当bool为false执行else语句块。如下图就是这两种情况的局部变量图

上面前局部变量中,前三个变量是共享的,发生变化的是第后面的变量,对于这两种执行情况,虽然声明的变量类型不同,并且变量字长是不同的,但是由于if和else两个程序块是并行的,所以局部变量中后三个位置是公用的。根据这种情况,ASMSupport采用一种树形结构来模拟和实现作用域和局部变量之间的关系。
我们将上面的代码再修改一下:
_代码2
public void method(boolean bool, boolean bool2)
{
int prefix = 1;
if (bool)
{
double d = 2.12;
String s = "string";
}
else
{
if(bool2)
{
float f = 1;
}
char c = 'a';
long l = 1L;
}
}
我们用方形表示程序块,圆形表示局部变量,并且给予各程序块别名得到如下图的树形结构。
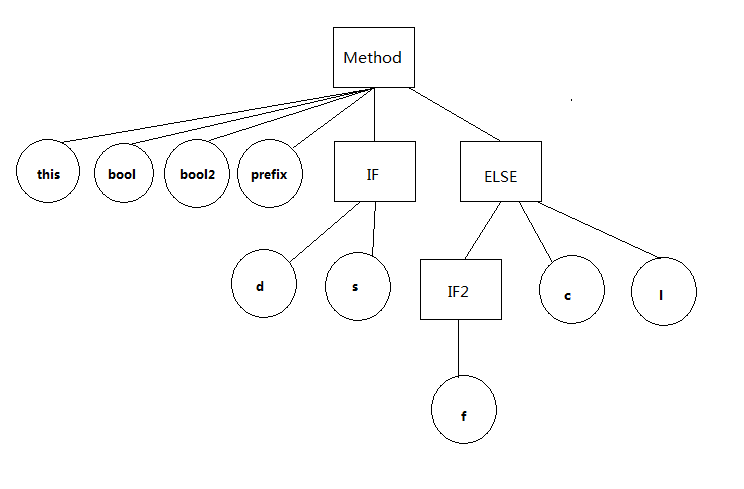 图1
图1
通过这个树,我们能够完成两个事情:
1. 确定哪些变量所占的局部变量空间相对于我们指定的变量是可以复用
2. 确定某一程序块中可以调用哪些变量
##局部变量空间的复用
在方法内所有的变量都存储在一个局部变量数组中的,但是如果在java代码里每声明一个变量都将它存到局部变量中的一个新的位置,势必会造成很大的空间浪费,正如我们在上面对代码1所分析的,有必要对一些局部变量空间进行些复用。
然我们结合代码2和图1,编译器将代码1转变成class文件,这一个过程中编译器会将程序逐一的转换成字节码,那么扫描的顺序就是对图1中的树做先序遍历(先序遍历其实是针对二叉树的,这里的意义就是先遍历根节点,然后将子节点按从左向右的顺序扫描),得出的结果就是:
this->bool->bool2->prefix-IF->d->s->ELSE-IF2->f->c->l
那么是如何判断变量空间可以复用的呢,ASMSupport是这样做的:
- 执行的prefix,将this,bool,bool2,prefix按顺序为其分配局部不变量空间,其下标分别为:0,1,2,3
- 执行到IF里,任然是为_d ,s_ 分配空间,由于_d_是double,所以分配了空间下标是4和5,_s_分配给了6
- 执行到IF2了,这时候发现_d_和_s_ 这两个变量的空间我是可以复用的,因为IF和ELSE是并行的,同一时刻同一线程不可能同时执行到IF和ELSE,而IF2又是ELSE的子块,所以它将f 分配给了下标为4的空间,这里4位置上已经被变量d 和s 复用了。
- 继续执行到_c_和_l_的时候,发现刚才分配给f 变量的空间是可以复用的,因为f 所在的程序块是IF2,他是ELSE的一个自程序块,在这个程序块的作用域中声明的变量只在当前作用域下有效,所以将_c_分配给下标为 f 所分配的空间4,这时候4位置已经被_d f c_ 三个变量共享了;这时候继续变量到l , 由于l是long型占两个字的空间,同样发现d所占位置5和s所占位置6是可以共享的,所以将5和6位置的局部变量分配给l
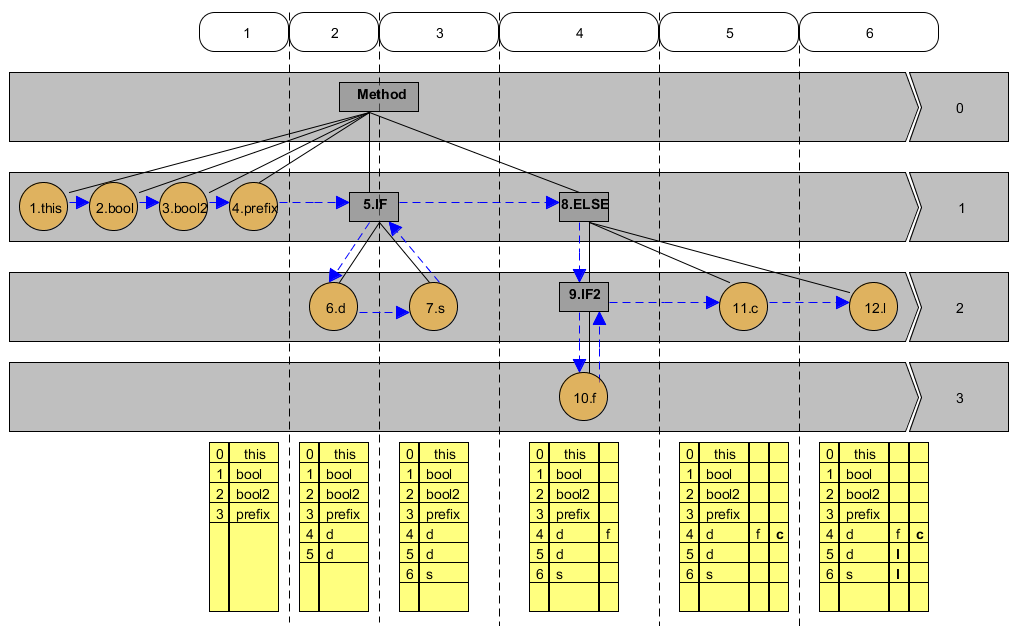 图2
图2
首先来描述下上图的几个图形:
- **方形:**表示程序块,也可以叫做_作用域_
- **圆形:**表示变量,其中数字表示ASMSupport遍历对象的顺序,我们称之为_变量序号_,后面的表示_变量名 _
- **直线:**表示程序块-程序块,程序块-变量之间的从属关系
- **横向的矩形:**表示在这个树结构中的_辈份_ ,而矩形右边的数字表示辈数,比如第一辈,第二辈
- **带箭头的虚线:**ASMSupport对变量创建遍历的路径
- **竖虚线和虚线间的椭圆形:**用来划分每次变量声明以及为该变量的局部变量数组分配,我们姑且称之为道,配椭圆形内的数字,我们称之为_道1,道2_
- **表格:**局部变量数组
还需注意一下几点:
-由于对this,bool,bool2,prefix的分配非常简单,所以这里我们将这些变量的申明操作并入到一个道1内 -每次为变量分配空间的时候都会从0开始遍历成员变量数组,判断当前声明的变量是否可以和遍历的变量服用,如果可以复用我们就使用当前遍历的下标分配给当前声明的变量。 对于第二点就是核心问题就是如何判断变量空间是否可复用 .
我们知道,变量实际存储在局部变量中的,也就是上图中的表格部分,而我们将存储在这些表格中的局部变量赋予了一个逻辑上的树结构,通过这个结构去判断变量是否可复用,一旦变量可以复用那么他的变量空间也是可以复用的。根据这个树形结构以及上面的图我们可以得出以步骤来判断变量是否可以复用的(变量的复用是相对与两个变量的),假设我们现在判断A变量的空间是否可以被B变量复用。
- 判读A变量的遍历序号是否小于B变量的遍历序号,如果大于则不能复用,否则进入2
- 如果A的辈份和B的辈份相同(在图二中表示为辈数值相同,比如变量d,s,c,l)并且具有同一个父辈,说明不能复用,不同说明允许复用。
- 如果A变量的辈数大于B变量的辈数(比如图二中的f和c),则A变量的空间可以被复用。
- 如果A变量的辈数小于B变量的辈数(比如图二中的d和f),从B变量开始向上获取长辈(作用域),直到找到的长辈和A变量的辈数相同的作用域T,如果A和T是同一个父辈则不能复用,如果父辈不同则可以复用。
##确定程序块中可调用的变量
前面介绍了如何判断变量是否可以复用,这里将介绍ASMSupport是如何判断当前所在的作用域可以调用哪些对象的。其实这个逻辑和判断是否可以复用的逻辑正好相反,我们将作用域看作是一个变量,然后判断是否可以复用,可以复用则说明在该作用域下不能使用指定变量,否则可以使用。而且实际上如果是编写代码,我们能够很直观的看到在子作用域中能够调用父作用域中定义的变量,这里我们还是简述下实现逻辑,ASMSupport实现的话则还是按照图一中的树形结构,假设我们需要判断A变量是否可以在S作用域中使用。
我们结合图2中的序号能得到如下判断方法:
- A的遍历序号大于S的遍历序号
- 如果A和S的辈份相同,并且具有同一父辈,说明A可以在S作用域内使用
- 如果A的辈数大于S的辈数则A不能在S作用域内使用
- 如果A的辈数小于S的辈数,则从S辈数向上获取长辈,直到找到的长辈和A变量的辈数相同的作用域T,如果A和T是同一个父辈则可以在S中使用A,否则不能使用。
##代码实现
###局部变量数组
在图二中我们看到了局部变量数组的模型,在ASMSupport中我们也是采用一个List来作为主体容器。起初我们只是在这个List中每个位置存储最新的变量,比如图二中道4 存储f 的时候,就会将之前的d 覆盖,类似于下图的过程:
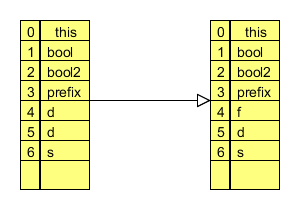 图3
图3
但是由于我们希望通过【如何查看ASMSupport的log文件】,在生产每一条局部变量操作指令的时候都打印出当前局部变量状态,这样更便于我们调试和跟踪自己的程序。所以我们在局部变量这个List的容器中存储的是一个自定义的类LocalHistory的对象,每一个LocalHistory对象对应一个本地变量数组中的一个单元位置,比如图二中的局部变量d 是double类型的,占两个单元,所以将会创建两个LocalHistory对象,并且在LocalHistory类中通过一个List存储在该位置上局部变量的变更历史,也就是我们图二中的局部变量的结构。
这些逻辑在ASMSupport代码中使用cn.wensiqun.asmsupport.utils.memory.LocalVariables 和 cn.wensiqun.asmsupport.utils.memory.LocalVariables.LocalHistory 实现的。后者是前者的一个内部类,并且是一个静态私有类型,仅仅在内部被LocalVariables使用。
LocalVariables还有个功能是打印局部变量的状态,这部分代码并不是局部变量实现的核心所以不做解释。
###作用域和局部变量的逻辑抽象
在图2中的核心是作用域和局部变量的树结构,作为树中的每一个节点,我们为其定义一个父类cn.wensiqun.asmsupport.core.utils.memory.Component,再分别定义Component的两个子类cn.wensiqun.asmsupport.core.utils.memory.Scope和cn.wensiqun.asmsupport.core.utils.memory.ScopeLogicVariable表示作用域和局部变量。层级结构图如下:
Component
|-Scope
|-ScopeLogicVariable
_图4
Component
作为父类,必然是需要定义一些基本信息,如下:
- locals: 这个是一个LocalVariabbles对象的引用
- generation: 存储该节点在树形结构中的辈数,对应予图二中的横向矩形
- componentOrder : 表示出现的顺序,对应于图二中每一个节点前的数字
- parent : 表示直接的父辈
这里的componentOrder并不像图二中是一串连续的数字,二是用辈数和点号实现的,类似如下结构:
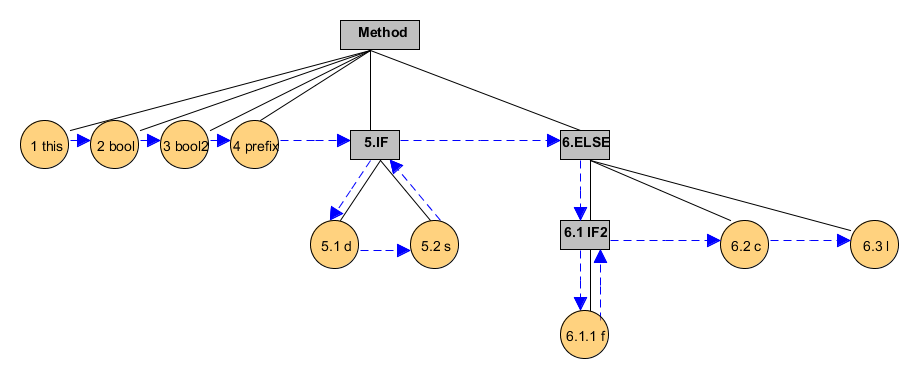 图5
图5
那么比较两个Component的先后顺序的话先比较第一个点前面的数字,数字值大的componentOrder比另一个componentOrder大,如果相等则继续比较第二个点前面的数字依次类推,比如“5.1 > 4", "6.1.1 > 5.2", "6.2 > 6.1.1"。具体实现是在compareComponentOrder方法中实现的。
Scope
这个类是对作用域的抽象,也就是我们图二中的方形部分。这个类中主要存储了以下属性:
- components : 一个List类型,存储这个的子节点
- start:【参考字节码Label】,用来划定当前作用域的起始位置
- innerEnd :【参考字节码Label】,用来划定当前作用域的结束位置
- outerEnd:【参考字节码Label】,用来划定当前作用域的结束位置
components和start比较好理解,按照上面解释。但是innerEnd和outerEnd有什么区别呢。这里就要涉及ASMSupport生成作用域的策略,详细参考【ASMSupport作用域划分策略】。
ScopeLogicVariable
这个类是对局部变量的抽象,在图二中表示为圆形的部分。这个类有下面一些属性:
- String name : 变量名
- Type declareType : 变量的声明类型
- Type actuallyType : 变量的实际类型
- int[] positions : 变量所占局部变量数组的位置
- **int initStartPos :**变量在局部变量的中的起始位置
- **boolean anonymous :**是否是匿名变量
- **Label specifiedStartLabel :**变量所在作用域的起始位置
- int compileOrder : 生成变量指令在字节码中的编译顺序
这里对某些属性做些说明:
- **1)actuallyType:**这个属性表示变量的实际类型,但是这个属性不完全能够确定变量的实际类型,比如我通过调用方法获取到的一个对象,我仅仅只能将方法的返回类型作为actuallType,但是方法返回的类型很可能是个接口,所以这个属性不建议使用。
- 2)positions : 这个属性是个数组,原因是如果当前变量是个double或者long类型,是占两个单位的局部变量空间的,所以这里用数组来存储,可以肯定的如果这个数组里面的有值,一定是连续的,比如[1,2], [3,4],这是因为局部变量空间的存储就是一个连续的存储。当然这个数组也可能没有值,因为在上面我们介绍过,变量空间是可能被复用的,一旦他某个位置被复用率,这里的数组就为变,比如图二中第三道 d变量的positions应该是[4,5], 到了第四道 就变成了5, 而新创建的变量 c 的positions就变成了4.
- 3) initStartPos : 这个表示该变量在局部变量数组中所占空间的起始位置,这个值等于positions数组在最初状态的第0个下标的值,为什么说是最初状态,前面在介绍positions的时候有介绍,positions是一直在变化的,所以我们在第一次初始化positions的时候就将其第0个下标的值赋予到initStartPos属性。
- 4) anonymous : 这个属性表示变量是否为匿名,一旦这个属性是true,那么name属性则失效
- 5) compileOrder : 根据上面的解释,这个属性和其父类的属性componentOrder有相似之处。其区别有两个地方
A. 模型不同:componentOrder是作用于我们抽象出来的属性结构,如图二中的树形结构中;compileOrder作用于方法生成字节码的模型中,可以认为是编译顺序每执行一次执行队列中的对象,都会把当前执行的序号设置的当前执行的对象的compileOrder 属性中。
B. 作用不同:componentOrder是用来判断变量是否可以复用,变量是否在某一作用域中可用;compileOrder的用来判断当前变量是否可以被某一操作使用,比如System.ou.println(var)中,var的肯定是在调用println方法之前就创建了的,也就意味var的compileOrder肯定要比println操作的compileOrder小。
除了属性这里还介绍下这个类的方法:
- isShareable : 这个方法传入一个ScopeLogicVariable类型的参数var,判断当前变量空间是否可以被传入的参数复用,具体算法见上文【局部变量空间的复用】
- availableFor : 传入一个Component,判断在Component中是否可以使用当前变量,算法见上文【确定程序块中可调用的变量】
- **isSubOf :**判断当前变量是否是传入的Scope的子代。
- store : 将当前变量存入局部变量数组。
这里介绍下store方法
- 设当前变量为C
- 获取C所需要的局部变量单位空间个数N。
- 从0 下标开始遍历局部变量数组,设I为遍历的次数(从0开始),如果有变量还没遍历,设V(我们称之为幸存者survivor)为下一个需要遍历的对象进入4,否则进入7。
- 如果V的所占的空间可以被C所复用,进入5,否则进入6
- 删除V的positions的第一个位置,并且将I加入到C的positions 中,同时将C存入到局部变量的I位置,令N=N-1,如果N等于0则跳出循环,否则进入3
- 如果C和V都是非匿名变量,判断C的名字和V是否相同,如果相同抛出异常,否则进入3
- 到这一步说明所有可复用变量空间都已经判断完成,如果N依然大于0,则存N次C到局部变量的末尾处,并且将每次存入到局部变量数组的位置添加到C的positions中。进入8
- 令C的initStartPos等于C的positions下标为0的值。
文字描述起来可能比较生涩,具体可以参考代码cn.wensiqun.asmsupport.utils.memory.ScopeLogicVariable.store(),有了上述一些列的操作和模型就能获得变量的一下属性:
- **name:**变量名
- **desc:**变量声明类型
- **start:**变量所在作用域的起始位置,对应于所在Scope的start
- **end :**变量所在作用域的结束位置,对应于所在Scope的innerEnd
- index : 变量在局部变量数组的其实下标值,对应于initStartPos
再调用MethodVisitor.visitLocalVariable(name, desc, null, start, end, index)的方法,告诉编译器,在start和end范围内,局部变变量位置为index的空间是desc类型的,并且叫做name。这个方法的第三个参数是变量签名,如果使用泛型可以使用,但是ASMSupport暂不支持泛型,所以这个值在ASMSupport中恒为空。











