
↑ 关注 + 星标 ,后台回复【大礼包】送你Python自学大礼
Github上面有很多有趣的python项目,包括软件、库、教程、资源等。这次收集了其中比较受欢迎的100个,供大家参考。
1、awesome-python-webapp:廖老师的 Python 入门教程中的实践项目的代码
2、Minos:一个基于 Tornado/MongoDB/Redis 的社区系统
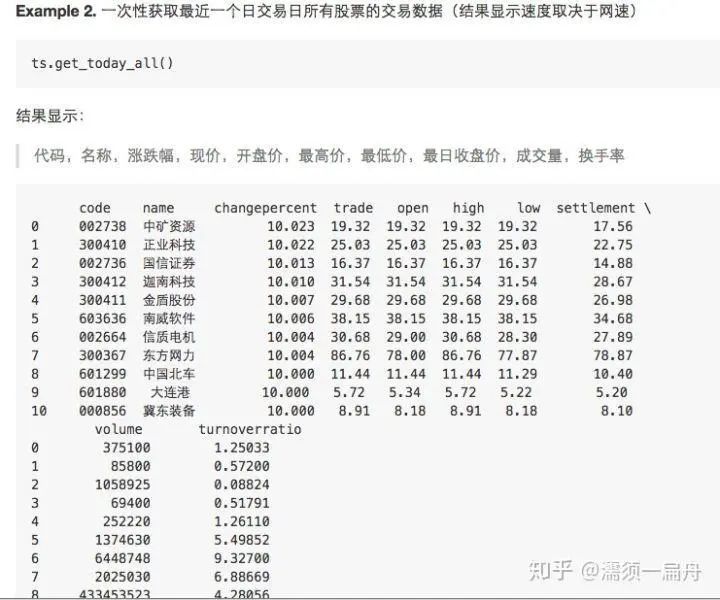
3、tushare:TuShare 是一个免费、开源的 Python 财经数据接口包,TuShare 文档
4、beijing_bus:北京实时公交,可以显示查询的公交到达某站还需多久
5、luokr.com:Python Tornado 写的开源网站——螺壳网,访问,如图:
6、ssbc:Python Django 写的种子搜索网站——手撕包菜,如图:
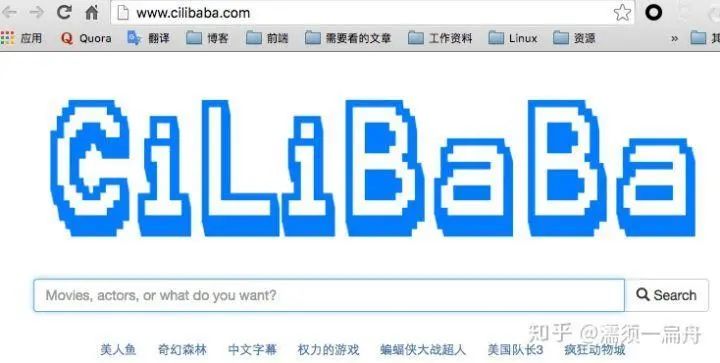
7、listen1:Listen 1 让你用一个网页就能听到多个网站的在线音乐,支持各种平台。如图:

8、python-gems:有趣的 Pyhton 代码片段集合
9、algorithm:老齐的 Python 算法教程
10、python-goose:Goose 用于文章提取器,提取中文内容的示例代码:
>>> from goose import Goose>>> from goose.text import StopWordsChinese>>> url = 'http://www.bbc.co.uk/zhongwen/simp/chinese_news/2012/12/121210_hongkong_politics.shtml'>>> g = Goose({'stopwords_class': StopWordsChinese})>>> article = g.extract(url=url)>>> print article.cleaned_text[:150]香港行政长官梁振英在各方压力下就其大宅的违章建筑(僭建)问题到立法会接受质询,并向香港民众道歉。梁振英在星期二(12月10日)的答问大会开始之际在其演说中道歉,但强调他在违章建筑问题上没有隐瞒的意图和动机。一些亲北京阵营议员欢迎梁振英道歉,且认为应能获得香港民众接受,但这些议员也质问梁振英有
11、mincss:Python 写的用来找到 CSS 中没有用到的代码片段,并删除。适用于:想要做一个页面,但是不会写 CSS 人。示例代码如下:
#coding:utf-8#!/usr/bin/env pythonfrom __future__ import print_functionimport sys, ossys.path.insert(0, os.path.abspath('.'))from mincss.processor import Processor# 这里改成想要参考的页面URL = 'http://localhost:9000/page.html'def run(): p = Processor() p.process(URL) # 输出INlink的css的简化前和简化后的css代码 print("INLINES ".ljust(79, '-')) for each in p.inlines: print("On line %s" % each.line) print('- ' * 40) print("BEFORE") print(each.before) print('- ' * 40) print("AFTER:") print(each.after) # 输出link引用的css的简化前和简化后的css代码 print("LINKS ".ljust(79, '-')) for each in p.links: print("On href %s" % each.href) print('- ' * 40) print("BEFORE") print(each.before) print('- ' * 40) print("AFTER:") print(each.after)if __name__ == '__main__': run()
12、KindleEar:这是一个运行在 Google App Engine(GAE) 上的 Kindle 个人推送服务应用,生成排版精美的杂志模式mobi/epub格式自动每天推送至您的 Kindle 或其他邮箱。
13、python-guide:Requests 库的作者——kennethreitz,写的 Python 入门教程。不单单是语法层面的,涵盖项目结构、代码风格,进阶、工具等方方面面。虽然是英文版(中文翻译版),但我这个英语渣都能看懂,你肯定也可以,快去看看吧,开卷有益。在线阅读
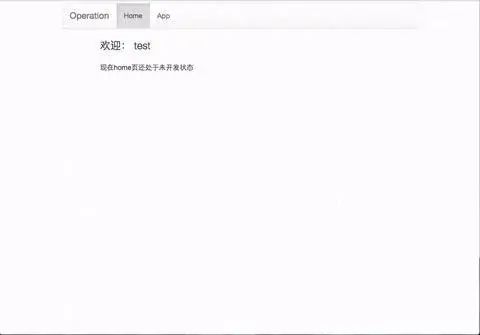
14、flask-admin:我工作中需要写一个微型的管理系统,用的就是这个框架。简直快餐型,页面都写好了,只要设置好相关配置就可以跑起来了。唯一缺点就是文档中的例子少,开发一些特定的需求需要自己看源码,才能知道如何改。文档,下面是我跑起来之后的样子:
15、python-sdk:七牛云存储 SDK。我自己在用他家的服务,上手简单、有免费额度,可以用来做‘图床’,同时,有了这个 SDK 可以写一些好用的小工具。注意:图床不能随便用,我曾经就用超了,账户的钱能扣成负数!
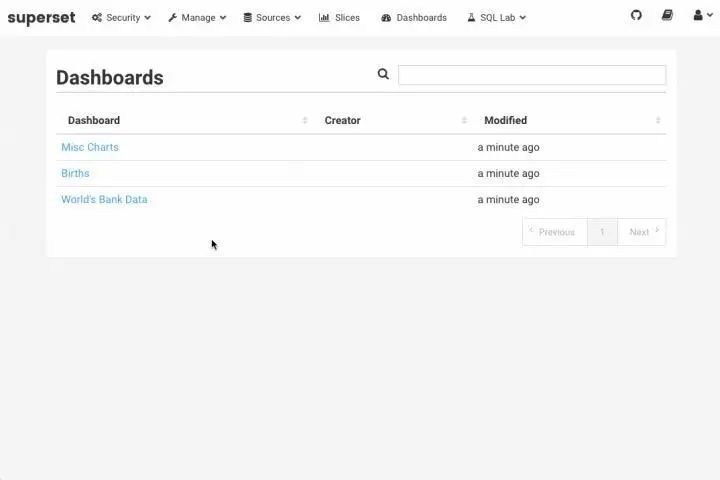
16、superset:企业级的数据探索、展示平台。功能很强大,可以用来做数据分析、展示。如下图:
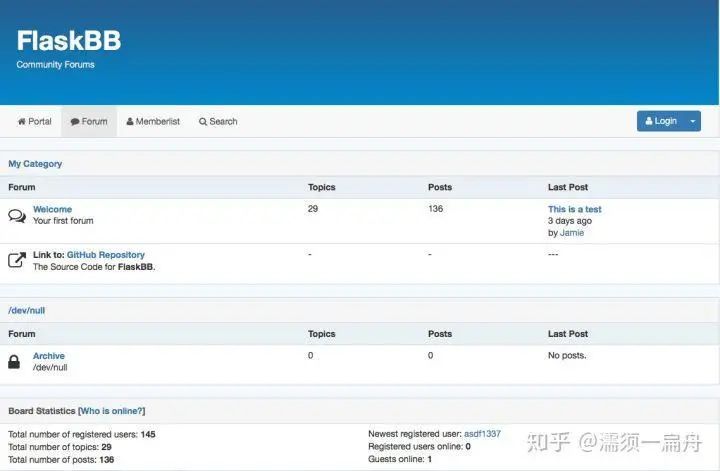
17、flaskbb:基于 Flask 框架做的论坛,功能有限,轻量级的论坛应用在线文档,可以在这个项目上进行二次开发,实现更加复杂的功能。在线预览
18、fuck-login:模拟登录一些知名的网站,为了方便爬取需要登录的网站。注意:控制爬虫的爬取频率!
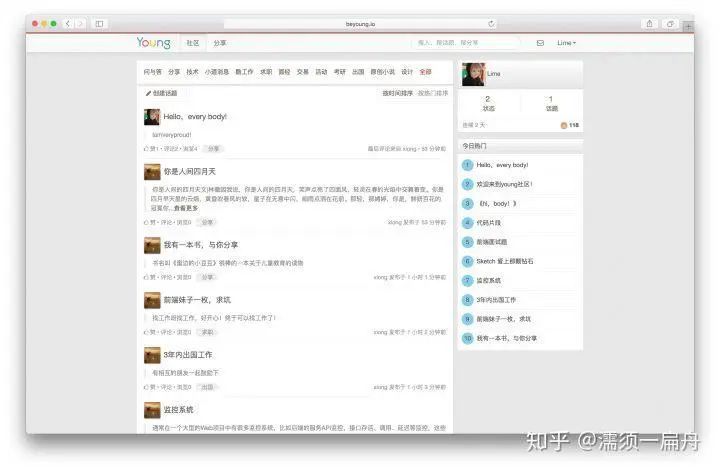
19、Young:基于 Tornado 框架、MongoDB 数据库,写的功能丰富的社区项目。详细的安装步骤,适合学习如何创建社区类 Web App。在线预览,项目运行效果图:
20、textfilter:基于某 1w 词敏感词库,用 Python 实现几种不同的过滤方式。用于过滤敏感词的实用模块,示例代码:
from filter import DFAFiltergfw = DFAFilter()gfw.parse("keywords")print "待过滤:售假人民币 我操操操"print "过滤后:", gfw.filter("售假人民币 我操操操", "*")test_first_character()# 运行结果# 待过滤:售假人民币 我操操操# 过滤后: 售假币
21、qrcode:Python 写的生成动态、彩色、各式各样的二维码,详细的中文文档,通过 qrcode 生成的二维码样式如下:

22、httpie:非常好用的命令行 HTTP 客户端,cURL 的替代者,返回的结果支持高亮,提高了可读性。用于调试接口、查看服务器返回的 HTTP 协议的信息。在线文档,下面的是 cURL 和 httpie 的返回结果对比图:

23、langid:用于识别输入文本数据所属的语种,目前支持 97 种语言识别。示例代码:
import langidtext1 = "I am a coder and love data mining"text2 = "请注明作者和出处并保留声明和联系方式"print langid.classify(text1)print langid.classify(text2)# ('en', 0.9999957874458753)# ('zh', 1.0)
24、fake-useragent:伪装浏览器身份,常用于爬虫。这个项目的代码很少,可以阅读一下,看看 ua.random 是如何返回随机的浏览器身份的 ,示例代码:
from fake_useragent import UserAgentua = UserAgent()ua.ie# Mozilla/5.0 (Windows; U; MSIE 9.0; Windows NT 9.0; en-US);ua.msie# Mozilla/5.0 (compatible; MSIE 10.0; Macintosh; Intel Mac OS X 10_7_3; Trident/6.0)'ua['Internet Explorer']# Mozilla/5.0 (compatible; MSIE 8.0; Windows NT 6.1; Trident/4.0; GTB7.4; InfoPath.2; SV1; .NET CLR 3.3.69573; WOW64; en-US)ua.opera# Opera/9.80 (X11; Linux i686; U; ru) Presto/2.8.131 Version/11.11ua.chrome# Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.2 (KHTML, like Gecko) Chrome/22.0.1216.0 Safari/537.2'ua.google# Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_4) AppleWebKit/537.13 (KHTML, like Gecko) Chrome/24.0.1290.1 Safari/537.13ua['google chrome']# Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11ua.firefox# Mozilla/5.0 (Windows NT 6.2; Win64; x64; rv:16.0.1) Gecko/20121011 Firefox/16.0.1ua.ff# Mozilla/5.0 (X11; Ubuntu; Linux i686; rv:15.0) Gecko/20100101 Firefox/15.0.1ua.safari# Mozilla/5.0 (iPad; CPU OS 6_0 like Mac OS X) AppleWebKit/536.26 (KHTML, like Gecko) Version/6.0 Mobile/10A5355d Safari/8536.25# and the best one, random via real world browser usage statisticua.random
25、reddit:reddit.com 网站的源码,通过这个项目,可以学习 Python 在构建大型项目中的使用、项目结构、代码风格、Python 技巧的使用方法等。安装教程

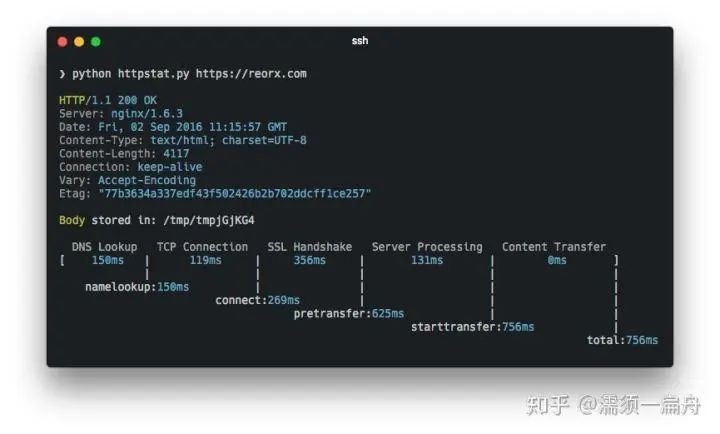
26、httpstat:httpstat 美化了 curl 的结果,使得结果更加可读。同时它无依赖、兼容 Python3、一共才 300 多行。还可以显示 HTTP 请求的每个过程中消耗的时间,如下图:
27、PyMySQL:纯 Pyton 写的 MySQL 库,纯 Python 的好处就是可以运行在任何装有 Python 解释器(CPython、PyPy、IronPython)的平台上。相对于 MySQLdb 性能几乎一样,使用方法也一样,但是 PyMySQL 安装方法极其简单——pip install PyMySQL,PyMySQL 使用示例代码:
# 下面为例子需要的数据库的建表语句CREATE TABLE `users` ( `id` int(11) NOT NULL AUTO_INCREMENT, `email` varchar(255) COLLATE utf8_bin NOT NULL, `password` varchar(255) COLLATE utf8_bin NOT NULL, PRIMARY KEY (`id`)) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_binAUTO_INCREMENT=1 ;# -*- coding: utf-8 -*-import pymysql.cursors# 连接数据库connection = pymysql.connect(host='localhost', user='user', password='passwd', db='db', charset='utf8mb4', cursorclass=pymysql.cursors.DictCursor)try: with connection.cursor() as cursor: # 创建一个新的纪录(record) sql = "INSERT INTO `users` (`email`, `password`) VALUES (%s, %s)" cursor.execute(sql, ('webmaster@python.org', 'very-secret')) # 连接不会自动提交,所以你想下面要调用 commit 方法,存储对数据库的改动 connection.commit() with connection.cursor() as cursor: sql = "SELECT `id`, `password` FROM `users` WHERE `email`=%s" cursor.execute(sql, ('webmaster@python.org',)) # 获取一条的纪录(record) result = cursor.fetchone() print(result) # 结果输出:{'password': 'very-secret', 'id': 1}finally: connection.close() # 操作完数据库一要记得调用 close 方法,关闭连接
28、flask-limiter:一个 Flask 的扩展库,它可以根据访问者的 IP 限制其访问频率、次数等。示例代码如下:
from flask import Flaskfrom flask_limiter import Limiterfrom flask_limiter.util import get_remote_addressapp = Flask(__name__)limiter = Limiter( app, key_func=get_remote_address, global_limits=["2 per minute", "1 per second"],)@app.route("/slow")@limiter.limit("1 per day")def slow(): return "24"@app.route("/fast")def fast(): return "42"@app.route("/ping")@limiter.exemptdef ping(): return 'PONG'app.run()
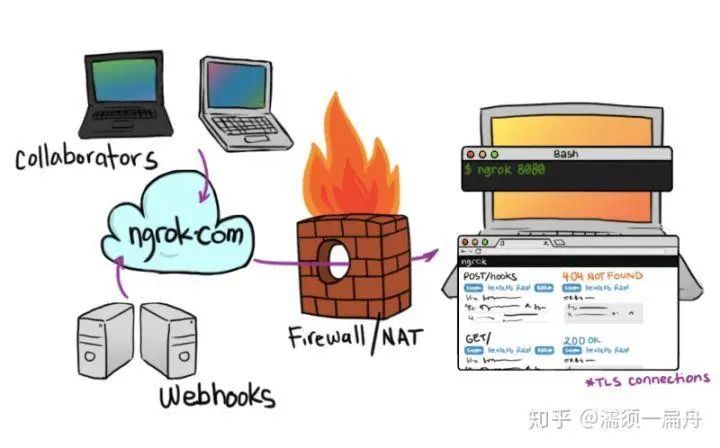
29、ngrok:一个十分方便、好用的内网穿透工具,它可以把本地某个端口的服务,通过一个安全隧道,映射到公网的一个地址。同时它提供了一个 Web 页面,展示了每个请求、响应的所有信息,便于调试本地的程序。基本的使用方法如下:
ngrok 协议 本地服务监听的端口ngrok http 8000创建成功会返回公网地址,然后通过该地址就可以访问到本地的服务。本地访问 http://localhost:4040,就可以查看关于每个请求、响应的相关数据
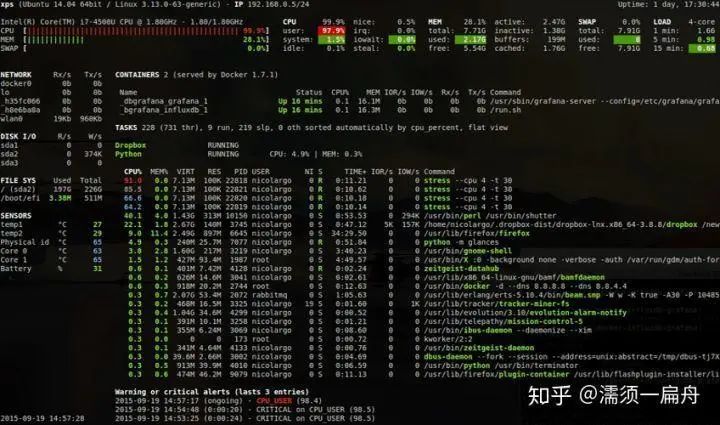
30、glances:一个可以让你一目了然你的系统情况(类 (h)top)的工具,它界面友好,安装方便:pip install glances
31、saythanks.io:Kennethreitz 写的一个简单的网站(基于 Flask),用于向开源项目作者发送感谢邮件的 Web App。该项目结构简单,可以用来学习大神是如何快速开发 Web 项目、方法、代码风格、开发常用库。而且该项目的意义也特别好:感谢开源项目的作者,愿开源社区越来越好,网站地址

32、locust:模拟用户行为的负载测试工具,包含友好的 Web 页面,如下图:

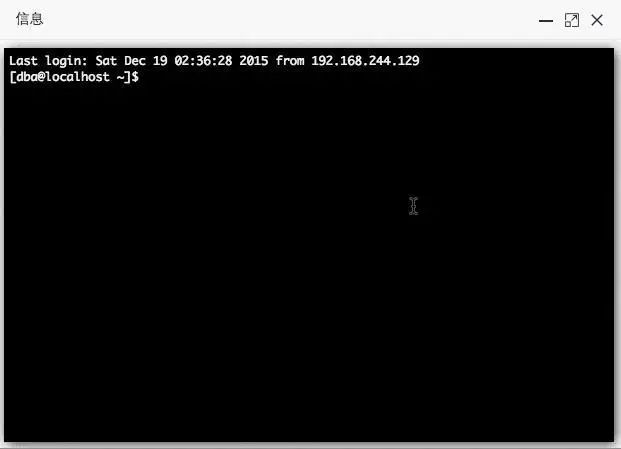
33、jumpserver:Jumpserver 是一款由 Python 编写开源的跳板机(是一类可作为跳板批量操作远程设备的网络设备)系统,实现了跳板机应有的功能。基于 SSH 协议来管理,客户端无需安装 agent。支持常见 Linux 系统,效果如下:
34、sh:sh 是一个成熟,用于替代 subprocess,它允许你调用任何程序,就像它是一个函数,支持 Python2.6 - 3.5
from sh import ifconfigprint ifconfig("eth0")
35、fastText.py:fastText 简而言之,就是把文档中所有词通过 lookup table 变成向量,取平均后直接用线性分类器得到分类结果。fastText 的实现
36、mongoaudit:强大的 MongoDB 渗透测试工具,用于发掘 MongoDB 漏洞、并提出改善方法。
安装:
pip install mongoaudit运行:
python mongoaudit
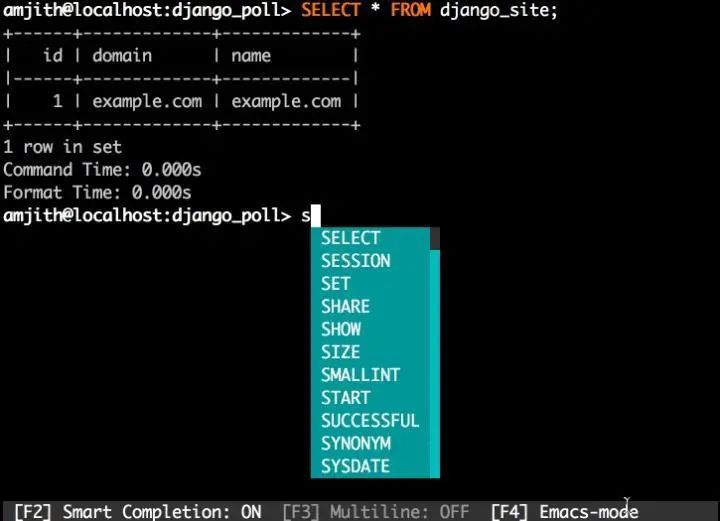
37、mycli:mycli 是一个带语法高亮、自动补全的 MySQL 命令行客户端工具。例如,连接数据库方法:mycli -h localhost -u 用户名 数据库
38、python-fire:Fire 是 Google 开源的 Python 库,可自动将您的代码转变成 CLI,无需您做任何额外工作。您不必定义参数,设置帮助信息,或者编写定义代码运行方式的 main 函数。相反,您只需从 main 模块调用“Fire”函数,其余工作全部交由 Python Fire 来完成。示例代码如下:
import fireclass Example(object): def hello(self, name='world'): """Says hello to the specified name.""" return 'Hello {name}!'.format(name=name)def main(): fire.Fire(Example)if __name__ == '__main__': main()# 在终端中调用效果如下:$ ./example.py helloHello world!$ ./example.py hello DavidHello David!$ ./example.py hello --name=GoogleHello Google!
39、ngxtop:解析 nginx 访问日志并格式化输出有用的信息,可以用来实时了解你的服务器正在发生的情况。安装命令 pip install ngxtop,输出示例如下:
$ ngxtoprunning for 411 seconds, 64332 records processed: 156.60 req/secSummary:| count | avg_bytes_sent | 2xx | 3xx | 4xx | 5xx ||---------+------------------+-------+-------+-------+-------|| 64332 | 2775.251 | 61262 | 2994 | 71 | 5 |Detailed:| request_path | count | avg_bytes_sent | 2xx | 3xx | 4xx | 5xx ||------------------------------------------+---------+------------------+-------+-------+-------+-------|| /abc/xyz/xxxx | 20946 | 434.693 | 20935 | 0 | 11 | 0 || /xxxxx.json | 5633 | 1483.723 | 5633 | 0 | 0 | 0 || /xxxxx/xxx/xxxxxxx | 3624 | 7830.236 | 3621 | 0 | 3 | 0 || /static/js/minified/utils.min.js | 3031 | 1781.155 | 2104 | 927 | 0 | 0 |
40、algorithms:基本算法、数据结构的 Python 实现
.├── array│ ├── circular_counter.py│ └── ...├── backtrack│ ├── anagram.py│ └── ...├── bfs│ ├── shortest_distance_from_all_buildings.py│ └── word_ladder.py├── bit│ ├── count_ones.py│ └── ...│ └── traversal.py└── 等等
41、searx:分分钟打造一个聚合的搜索引擎,使用简单,部署方便。拓展方便,基于插件式的管理。演示地址
42、grequests:Rquests + Gevent 让异步 HTTP 变得简单、人性化。示例代码:
>>> import grequests>>> def exception_handler(request, exception):... print "Request failed">>> reqs = [... grequests.get('http://httpbin.org/delay/1', timeout=0.001),... grequests.get('http://fakedomain/'),... grequests.get('http://httpbin.org/status/500')]>>> grequests.map(reqs, exception_handler=exception_handler)Request failedRequest failed[None, None, <Response [500]>]
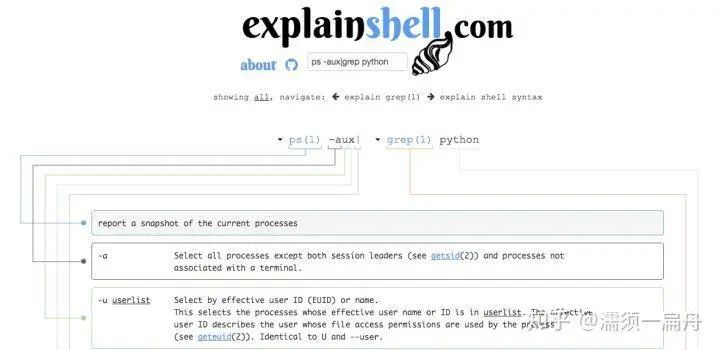
43、explainshell:一个可以解析 Linux 命令的网站,它可以给出命令的解释和其参数的解释,例如:ps -aux|grep python,在线演示
44、certbot:免费的自动启用和部署 HTTPS 的工具,让你的网站开启 HTTPS 变得简单快捷。在部署教程页面选择服务器的操作系统和 Web 服务器,之后根据给出的步骤一步步的执行命令就行了,部署教程
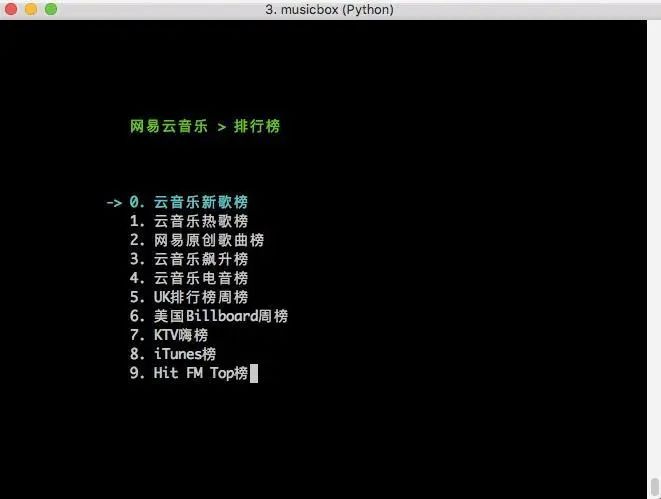
45、musicbox:基于 Python 编写的网易云音乐命令行版本,使用起来简单优雅,能够快速安装及使用
46、django-blog-tutorial:基于最新版 Django 1.10 和 Python 3.5,通过 26 篇教程一步步带你使用 Django 从零开发一个个人博客系统,在实践的同时掌握 Django 的开发技巧,完成效果展示
47、aredis:一款基于 Python3 asyncio 的异步 redis 客户端,支持对于单实例,连接池, 哨兵以及集群。作者希望可以找到志同道合的小伙伴集思广益,一起维护、优化。示例代码如下:
>>> import asyncio >>> from aredis import StrictRedis >>> >>> async def example(): >>> client = StrictRedis(host='127.0.0.1', port=6379, db=0) >>> await client.flushdb() >>> await client.set('foo', 1) >>> assert await client.exists('foo') is True >>> await client.incr('foo', 100) >>> >>> assert int(await client.get('foo')) == 101 >>> await client.expire('foo', 1) >>> await asyncio.sleep(0.1) >>> await client.ttl('foo') >>> await asyncio.sleep(1) >>> assert not await client.exists('foo') >>> >>> loop = asyncio.get_event_loop() >>> loop.run_until_complete(example())
48、freezegun:时间漫步模块,模拟到某一个时间,使用简单方式多样,实现了装饰器、上下文等调用方式。示例代码如下:
from freezegun import freeze_timeimport datetimeimport unittest@freeze_time("2012-01-14")def test(): assert datetime.datetime.now() == datetime.datetime(2012, 1, 14)
49、LearnPython:这一个以”撸代码“的形式学习 Python 的编程技巧的项目,针对 Python 的一些语法特性力求通过代码例子解释该知识点、同时还有一些实践项目,通过动手实践有助于知识的融会贯通。同时可以关注作者的知乎专栏学习更多的 Python 编程技巧
50、getproxy:极简的抓取代理项目,无需配置。不仅提供了获取代理脚本,同时可以通过该页面,直接获取可用代理(15min 更新、类型包含http和https)
51、syncPlaylist:在网易云音乐与 QQ 音乐之间同步歌单。易于使用、配置方便、代码简单,用到的技术:requests + beautifulsoup 以及 selenium + phantomjs
52、GetSubtitles:通过拖曳视频文件进终端,一步下载字幕 到视频对应文件夹,并重命名字幕名称为视频名称。Ubuntu 16.04、Windows 10上测试通过,同时兼容 Python2、3。Python 的魅力之一就是可以快速实现一个适合自己的小工具 Cool ✌️

53、huey:结合 redis 实现的轻量任务队列,但是支持功能还是很多的:
多进程、多线程、协程
任务定时执行
任务执行失败重试
结果存储
54、simiki:一个简单的个人 Wiki 框架,便于快速搭建 Wiki 页。使用 Markdown 书写 Wiki, 生成静态 HTML 页面。Wiki 源文件按目录分类存放, 方便管理维护。中文文档
55、pyecharts:Echarts+Python 实现的一个用于生成 Echarts 图表的类库
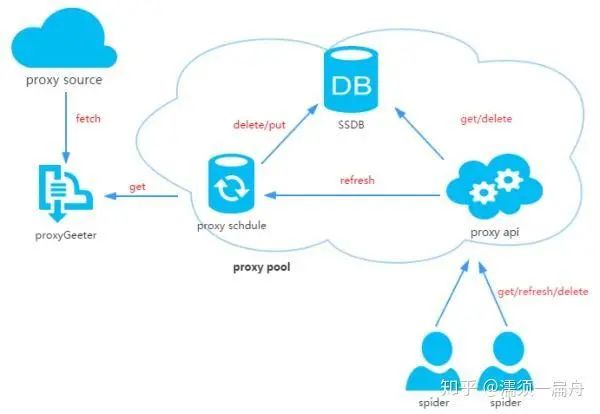
56、proxy_pool:基于 Python 的自建代理 IP 池服务,通过网络爬虫抓取互联网上免费的代理 IP,本地校验、剔除失效的代理IP,从而实现高可用的代理 IP 池。最后使用 Flask 搭建提供代理 IP 服务,包括代理池刷新、无效代理删除、代理获取等。该项目设计文档详细、模块结构简明易懂,同时适合爬虫新手更好的学习爬虫技术
57、WeiboSpider:分布式微博爬虫,支持快速抓取和稳定抓取两种运行模式。项目模块逻辑清晰、注释丰富、便于定制化自己的需求。同时,对于小白用户,可以通过演示视频快速入门,也提供QQ群答疑,已经持续维护一年多。靠谱的项目,小伙伴们要赶快上车~

58、pygorithm:一个帮助学习主要算法的库,可以通过理解这些算法的实现,提高自己的算法水平。冒泡排序示例:
>>> from pygorithm.sorting import bubble_sort>>> my_list = [12, 4, 3, 5, 13, 1, 17, 19, 15]>>> sorted_list = bubble_sort.sort(my_list)>>> print(sorted_list)>>> [1, 3, 4, 5, 12, 13, 15, 17, 19]
59、newspaper:强大的提取 Web 的内容、文章的库,支持多种语言,安装命令 pip3 install newspaper3k。示例代码:
>>> from newspaper import Article>>> url = 'http://fox13now.com/2013/12/30/new-year-new-laws-obamacare-pot-guns-and-drones/'>>> article = Article(url)>>> article.download()>>> article.html'<!DOCTYPE HTML><html itemscope itemtype="http://...'>>> article.parse()>>> article.authors['Leigh Ann Caldwell', 'John Honway']>>> article.publish_datedatetime.datetime(2013, 12, 30, 0, 0)>>> article.text'Washington (CNN) -- Not everyone subscribes to a New Year's resolution...'>>> article.top_image'http://someCDN.com/blah/blah/blah/file.png'>>> article.movies['http://youtube.com/path/to/link.com', ...]>>> from newspaper import Article>>> url = 'http://www.bbc.co.uk/zhongwen/simp/chinese_news/2012/12/121210_hongkong_politics.shtml'>>> a = Article(url, language='zh') # Chinese>>> a.download()>>> a.parse()>>> print(a.text[:150])香港行政长官梁振英在各方压力下就其大宅的违章建筑(僭建)问题到立法会接受质询,并向香港民众道歉。梁振英在星期二(12月10日)的答问大会开始之际在其演说中道歉,但强调他在违章建筑问题上没有隐瞒的意图和动机。 一些亲北京阵营议员欢迎梁振英道歉,且认为应能获得香港民众接受,但这些议员也质问梁振英有>>> print(a.title)港特首梁振英就住宅违建事件道歉
60、faker:用于生成假数据的库,支持多种语言,你值得拥有。示例代码:
fake.address()# '辽宁省雪市静安廉街b座 998259'fake.street_address()# '巢湖街U座'fake.building_number()# 'x座'fake.city_suffix()# '市'fake.latitude()# Decimal('-0.295126')fake.province()# '湖北省'
61、binlog2sql:从 MySQL binlog 解析出你要的 SQL。根据不同选项,提供如下功能
数据快速回滚,闪回原理与实践
主从切换后新 master 丢数据的修复
从 binlog 生成标准SQL,带来的衍生功能
62、pandas-tutorial:这套 pandas 教程包含从初级到进阶的内容,适合初学者和希望进阶建立知识体系的数据科学从业者阅读。作者还在持续更新高级内容,你值得拥有
63、pysheeet:Python 速查表,在线阅读
64、robobrowser:提供多种模拟操作网页的库,比如获得网页内容、访问链接、点击按钮、填充并提交表单、上传文件。使用简单、API 友好。适用于想要通过脚本流程化操作,某些未提供这些操作接口的场景,示例代码如下:
# 上传文件from robobrowser import RoboBrowser# Browse to a page with an upload formbrowser = RoboBrowser()browser.open('http://cgi-lib.berkeley.edu/ex/fup.html')# Find the formupload_form = browser.get_form()upload_form # <RoboForm upfile=, note=># Choose a file to uploadupload_form['upfile'] # <robobrowser.forms.fields.FileInput...>upload_form['upfile'].value = open('path/to/file.txt', 'r')# Submitbrowser.submit(upload_form)
65、ItChat:开源的微信个人号SDK,提供了丰富的功能。从而使得 Python 调用微信、发送消息、传输文件等操作只需要编写极少的代码,示例代码如下:
import itchatitchat.auto_login()itchat.send('Hello, filehelper', toUserName='filehelper')
66、records:Kenneth Reitz 大神的for Humans™系列,Records 是一个支持大多数主流关系数据库的原生 SQL 查询第三方库。API 友好,使用简单、支持命令行模式、功能多样。与此同时该库只有 500 行代码,可以当作入门阅读源码的项目,同时学习大神的编程技巧与习惯,示例代码如下:
import recordsdb = records.Database('postgres://...') # 连接数据库rows = db.query('select * from active_users') # 执行原生 SQL# 遍历结果for r in rows: print(r.name, r.user_email)# 友好的 print 格式print(rows.dataset)# username|active|name |user_email |timezone# --------|------|----------|-----------------|--------------------------# model-t |True |Henry Ford|model-t@gmail.com|2016-02-06 22:28:23.894202# 支持将结果导出成不同格式print(rows.export('json')) # jsonprint(rows.export('csv')) # csvprint(rows.export('yaml')) # yamlrows.export('df') # pandas 的 df 对象with open('report.xls', 'wb') as f: f.write(rows.export('xls')) # xls
67、zdict:方便的终端字典工具,支持多种字典和参数、翻译结果高亮、以及交互模式查询。安装命令 pip install zdict(仅支持 Python3)。查询效果如下图所示:

68、joblib:使用 Python 方便的进行并行计算,示例代码如下:
from joblib import Parallel, delayedfrom math import sqrtParallel(n_jobs=1)(delayed(sqrt)(i2) for i in range(10))
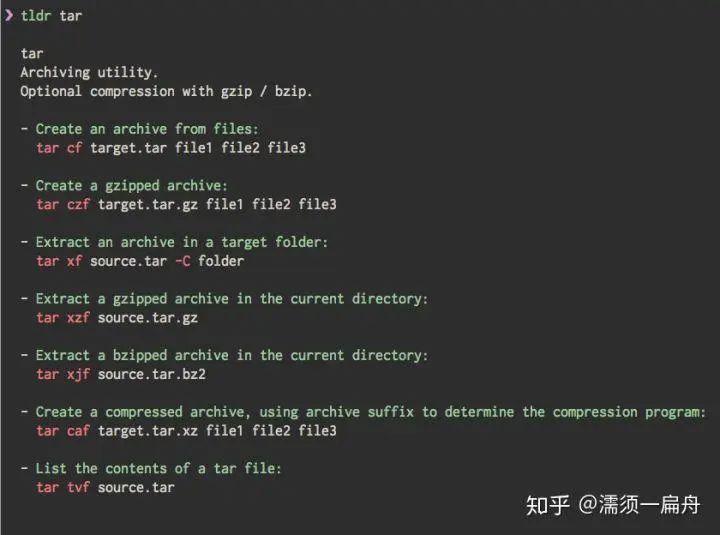
69、tldr-python-client:Linux man 解释一般都太长了,很多时候我们就想用一些比较常用的命令,但却记不起来。这个时候如果不 Google,就可以用 tldr(简化 man 的工程)。该项目为 Python 客户端实现
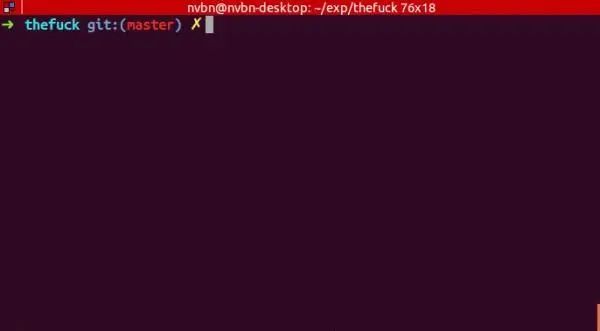
70、thefuck:在 Linux 命令行中,当你输入的命令有错误后,直接输入 fuck 就可以自动执行修复后的命令,效果图如下:
71、youtube-dl:强大的视频下载工具,支持几百个国内外主流视频网站。正如名字一样,最初是为了下载 youtube 上的视频而开发的。如果有国外服务器的朋友,可以充分利用这个工具,下载 youtube 上的视频,速度不要太爽。下面介绍安装、下载视频等命令:
# 1\. 安装命令:sudo pip install youtube-dlInstalling collected packages: youtube-dlSuccessfully installed youtube-dl-2017.12.14# 2\. 查看 URL 支持格式:youtube-dl --list-formats URLformat code extension resolution note134 mp4 450x360 DASH video 449k , avc1.4d4015, 25fps, video only17 3gp 176x144 small , mp4v.20.3, mp4a.40.2@ 24k36 3gp 300x240 small , mp4v.20.3, mp4a.40.218 mp4 450x360 medium , avc1.42001E, mp4a.40.2@ 96k43 webm 640x360 medium , vp8.0, vorbis@128k (best)# 3\. 选择格式下载视频:youtube-dl -f 18 URL (18为mp4 450x360格式)[youtube:playlist] Downloading playlist PLF90USSyuoYzPhhFG7XFBRn63Zvs--lNP - add --no-playlist to just download video JyLducMVYVg[youtube:playlist] PLF90USSyuoYzPhhFG7XFBRn63Zvs--lNP: Downloading webpage[download] Downloading playlist: 情满四合院完整版[youtube:playlist] playlist 情满四合院完整版: Downloading 42 videos[download] Downloading video 1 of 42...# 4\. 下载完成后,最后使用 https://github.com/houtianze/bypy 库把下载的视频同步到百度网盘上
72、jieba:强大的 Python 分词库,拿来直接用就好。示例代码如下:
# encoding=utf-8import jiebaseg_list = jieba.cut("我来到北京清华大学", cut_all=True)print("Full Mode: " + "/ ".join(seg_list)) # 全模式seg_list = jieba.cut("我来到北京清华大学", cut_all=False)print("Default Mode: " + "/ ".join(seg_list)) # 精确模式seg_list = jieba.cut("他来到了网易杭研大厦") # 默认是精确模式print(", ".join(seg_list))seg_list = jieba.cut_for_search("小明硕士毕业于中国科学院计算所,后在日本京都大学深造") # 搜索引擎模式print(", ".join(seg_list))【全模式】: 我/ 来到/ 北京/ 清华/ 清华大学/ 华大/ 大学【精确模式】: 我/ 来到/ 北京/ 清华大学【新词识别】:他, 来到, 了, 网易, 杭研, 大厦 (此处,“杭研”并没有在词典中,但是也被Viterbi算法识别出来了)【搜索引擎模式】: 小明, 硕士, 毕业, 于, 中国, 科学, 学院, 科学院, 中国科学院, 计算, 计算所, 后, 在, 日本, 京都, 大学, 日本京都大学, 深造
73、pydu:该库将平时常用的数据结构和工具都收录其中,可供日常开发的使用,同时方便学习与借鉴,丰富的文档能帮助新手更好的理解和使用它。这些实用的模块都是来自于开源项目和贡献者们的智慧,快来加入到这个项目中,让它变得更加实用和丰富
74、shell-functools:把函数式的编程带入 shell,从而让很多事情变得简单。通过 Python 的高阶函数和内置模块 os.path 与命令的管道结合,达到了强大、高效的功效。相比于单纯的命令实现更加的直观和容易理解,示例代码如下:
示例 1# ls 查看当前目录下的文件> ls document.txtfolderimage.jpg# 通过 map abspath 展示这些文件的绝对路径> ls | map abspath/tmp/demo/document.txt/tmp/demo/folder/tmp/demo/image.jpg示例 2# find 命令找到的文件和目录> find../folder./folder/me.jpg./folder/subdirectory./folder/subdirectory/song.mp3./document.txt./image.jpg# 把找到的结果中的文件,重命名在末尾追加 .bak (备份文件)> find | filter is_file | map basename | map append ".bak"me.jpg.baksong.mp3.bakdocument.txt.bakimage.jpg.bak
75、tqdm:强大、快速、易扩展的 Python 进度条库。我想通过下面的示例代码和效果展示图,你会跑去给这个项目来个 Star 的
from tqdm import tqdmfor i in tqdm(range(10000)): pass# 输出结果:# 76%|████████████████████████████ | 7568/10000 [00:33<00:10, 229.00it/s]
76、HAipproxy:使用 Scrapy+Redis 实现的高可用分布式 IP 代理池,为大型分布式爬虫提供高可用低延迟的代理 IP 资源。
from client.py_cli import ProxyFetcherargs = dict(host='127.0.0.1', port=6379, password='123456', db=0)# 这里`zhihu`的意思是,去和`zhihu`相关的代理ip校验队列中获取ip# 这么做的原因是同一个代理IP对不同网站代理效果不同fetcher = ProxyFetcher('zhihu', strategy='greedy', redis_args=args)# 获取一个可用代理print(fetcher.get_proxy())# 获取可用代理列表print(fetcher.get_proxies()) # or print(fetcher.pool)
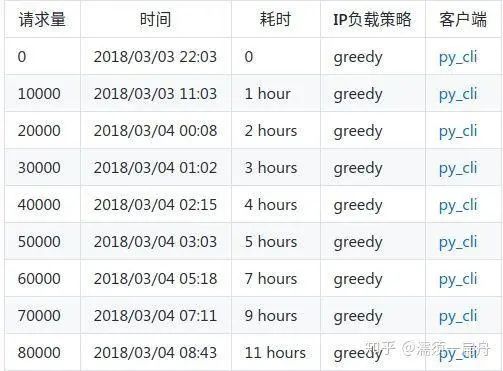
以知乎为目标抓取网站,该代理IP池的实际性能测试结果如下:
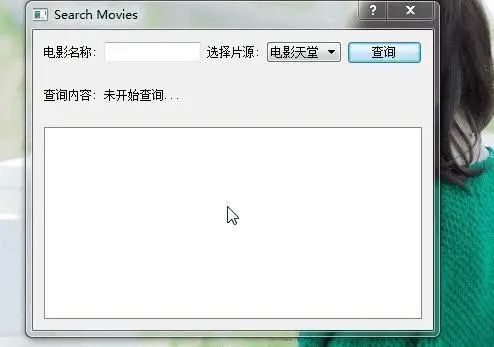
77、MovieHeavens:基于 Pyqt4 的电影天堂电影搜索工具,再也不用忍受各种广告和点击跳转了
78、WechatSogou:基于搜狗微信搜索的微信公众号爬虫库,极易上手。示例代码:
import wechatsogouws_api = wechatsogou.WechatSogouAPI()ws_api.get_gzh_info('微信名称')
79、Synonyms:中文近义词工具包。支持自然语言理解的很多任务:文本对齐、推荐算法、相似度计算、语义偏移、关键字提取、概念提取、自动摘要、搜索引擎等。示例代码如下:
import synonymssynonyms.seg("能量")

80、pook:模拟 HTTP 请求结果的库,可用于单元测试等场景。采用装饰器方式调用的示例代码如下:
import pookimport requests@pook.get('http://httpbin.org/status/500', reply=204)@pook.get('http://httpbin.org/status/400', reply=200)def fetch(url): return requests.get(url)res = fetch('http://httpbin.org/status/400')print('#1 status:', res.status_code)res = fetch('http://httpbin.org/status/500')print('#2 status:', res.status_code)
81、incubator-airflow:定时任务管理平台,管理和调度各种离线定时任务,自带 Web 管理界面。当定时任务量达到百级别的时候,就无法再使用 crontab 有效、方便地管理这些任务了。该项目就是为了解决了这个问题而诞生的

82、wtfpython:有趣、令人惊讶(坑爹)、鲜为人知的 Python 代码片段集合。中文

83、redis-faina:Redis 性能分析器。提供两种模式分析模式:命令实时、读取日志。其原理是使用 Redis MONITOR 命令,将该命令的结果通过管道传递给 redis-faina 脚本,脚本将返回的信息解析,并汇成总成统计信息。具体信息如下所示:
注意:分析非常闲的 redis 实例时,分析的结果可能偏差的很多。时间单位为微秒:ms = 1.0 × 10^-6 secondsOverall Stats========================================# 总命令数Lines Processed 10# QPSCommands/Sec 1.03 # 出现最多的 key 的前缀Top Prefixes ========================================startchart 9 (90.00%)# 请求最多的keyTop Keys ========================================startchart:521xueweihan/hellogithub 9 (90.00%)# 请求最多的命令Top Commands ========================================get 9 (90.00%)# 请求响应时间的分布Command Time (microsecs) ========================================Median 583914.075% 637395.090% 5703923.099% 5703923.0# 总耗时最多的命令Heaviest Commands (microsecs)========================================get 9746157.0# 慢请求列表Slowest Calls ========================================5703923.0 "get" "startchart:521xueweihan/hellogithub"637395.0 "get" "startchart:521xueweihan/hellogithub"633909.0 "get" "startchart:521xueweihan/hellogithub"583914.0 "get" "startchart:521xueweihan/hellogithub"569207.0 "get" "startchart:521xueweihan/hellogithub"548745.0 "get" "startchart:521xueweihan/hellogithub"545493.0 "get" "startchart:521xueweihan/hellogithub"523571.0 "get" "startchart:521xueweihan/hellogithub"
84、marshmallow:使用类似于 ORM 的语法,序列化、反序列化 Python 对象。可以将序列化的对象呈现为标准格式,适用于例如数据校验、返回 HTTP API 的 JSON。示例代码如下:
from datetime import datefrom marshmallow import Schema, fields, pprintclass ArtistSchema(Schema): name = fields.Str()class AlbumSchema(Schema): title = fields.Str() release_date = fields.Date() artist = fields.Nested(ArtistSchema())bowie = dict(name='David Bowie')album = dict(artist=bowie, title='Hunky Dory', release_date=date(1971, 12, 17))schema = AlbumSchema()result = schema.dump(album)pprint(result, indent=2)# 输出如下# { 'artist': {'name': 'David Bowie'},# 'release_date': '1971-12-17',# 'title': 'Hunky Dory'}
85、tenacity:使用该库可以优雅地实现各种需求的重试。示例代码如下:
from tenacity import retry, stop_after_attempt# 通过装饰器,实现遇到异常重试3次@retry(stop=stop_after_attempt(3)) def get_data(url): response = requests.get(url) response_json = response.json()
86、unimatrix:模拟“黑客帝国”影片中的终端动画脚本

87、pudb:基于控制台的全屏 Python 可视化调试器。比 pdb 好用太多了,特性:
源码语法高亮,栈、断点、变量可见并且一直动态更新。变量展示还有很多可以定制化的功能。
基于键盘,简单高效。支持 VI 的鼠标移动。还支持 PDB 的某些命令
支持查找源代码,可以使用 m 代用 module browser 查看载入的模块
断点设置。鼠标移到某行代码,按 b,然后可以在断点窗口编辑断点
88、Scylla:一款高质量的免费代理 IP 池工具,仅支持 Python 3.6。中文文档,特性如下:
自动化的代理 IP 爬取与验证
易用的 JSON API
简单但美观的 web 用户界面,基于 TypeScript 和 React(例如,代理的地理分布)
最少仅用一行代码即可与 Scrapy 和 requests 进行集成
等等
89、hue:开源的 Apache Hadoop UI 系统。通过使用 Hue 我们可以在浏览器端的 Web 控制台上与 Hadoop 集群进行交互来分析处理数据。核心功能:
数据可视化
SQL 编辑器,支持 Hive、Impala、MySQL等
可进行 workflow 的编辑、查看
90、FeelUOwn:一个符合 Unix 哲学的跨平台的音乐播放器,主要面向 Linux/macOS 用户。特性:
安装简单,新手友好
默认提供国内各音乐平台插件(网易云、虾米、QQ)
较强的可扩展性可以满足大家折腾的欲望
核心模块有较好文档和测试覆盖
91、tinydb:TinyDB 是使用纯 Python 编写的 NoSQL 数据库,使用 json 文件存储数据。它区别于 SQLite 的关系性数据库。同样的小、不需要依赖外部服务器。适用于桌面程序、客户端,不适用于 Web 应用、高性能的数据查询。友好的 API,示例代码:
>>> from tinydb import TinyDB, Query>>> db = TinyDB('path/to/db.json')>>> User = Query()>>> db.insert({'name': 'John', 'age': 22})>>> db.search(User.name == 'John')[{'name': 'John', 'age': 22}]

92、TGmeetup:搜集、整理、展示、报名技术类线下聚会的命令行工具,让使用者可以更加方便、及时的获取技术类活动资讯
93、termtosvg:Python 写的终端记录器。通过命令 termtosvg 运行该工具,然后在终端执行你要展示的命令,最终输入 exit 命令结束录制,本地会生成一份 SVG 动画,可用于分享、展示终端操作。效果如下:

94、cx-extractor-python:这是一个对网页正文进行抽取的工具。cx-extractor 算法的 python 版本,改进了原有算法,使其支持中英文,对新闻类网页正文抽取效果较好。示例代码:
from crawler.cx_extractor_Python import cx_extractor_Pythoncx = cx_extractor_Python()test_html = cx.getHtml('http://news.163.com/16/0101/10/BC84MRHS00014AED.html')content = cx.filter_tags(test_html)s = cx.getText(content)print(s)
95、awslogs:一个简单的命令行工具,用于在本地查询 Amazon CloudWatch 日志,强大的支持多实例日志汇总查看。简单的查看命令:awslogs get /var/logs/syslog ALL -s1d
96、CUP:CUP 基础库是百度开源的 Python 语言基础库,致力将 DEV 从涉及底层操作、Util 操作类解放出来,使其更关注构建 service 上层业务逻辑。目前已涵盖了构建一个服务的各个方面,大家可以从基础库的代码结构、wiki、doc 中进行简单了解。
cup |-- cache.py module 缓存相关模块 ( Memory cache related module ) |-- decorators.py module python 修饰符,比如 @Singleton 单例模式 (Decorators of python) |-- err.py module 异常 exception 类, Exception classes for CUP |-- __init__.py module 默认__init__.py, Default __init__.py |-- log.py module 打印日志类,CUP 的打印日志比较简洁、规范,设置统一、简单(cup logging module) |-- mail.py module 发送邮件 ( CUP Email module (send emails)) |-- net package 网络相关操作( Network operations, such as net handler parameter tuning ) |-- oper.py module 一些混杂操作(Mixin operations) |-- platforms.py module 跨平台、平台相关操作函数(Cross-platform operations) |-- res package 资源获取、实时用量统计等,所有在 /prco 可获得的系统资源、进程、设备等信息 ( Resource usage queries (in /proc)、Prcoess query、etc ) |-- shell package 命令 Shell 操作 pakcage ( Shell Operations、cross-hosts execution ) |-- services package 构建服务支持的类(比如心跳、线程池 based 执行器等等) Heartbeat、Threadpool based executors、file service、etc |-- thirdp package 第三方依赖纯 Py 模块( Third-party modules:pexpect、httplib2 ) |-- timeplus.py module 时间相关的模块(Time related module) |-- unittest.py module 单元测试支持模块( Unittest、assert、noseClass ) |-- util package 线程池、可打断线程、语义丰富的配置文件支持( ThreadPool、Interruptable-Thread、Rich configuration、etc ) |-- version.py module 内部版本文件,CUP Version
97、supervisor:Python 开发的一个 C/S 服务,是 Linux/Unix 系统下的一个进程管理工具,不支持 Windows 系统。它可以很方便的监听、启动、停止、重启一个或多个进程。用 Supervisor 管理的进程,当一个进程意外被杀死,supervisort 监听到进程死后,会自动将它重新启动,很方便的做到进程自动恢复的功能,提高系统、服务的稳定性,多用于生产环境
98、himawaripy:一个 Python3 脚本,它会定时(需设置定时任务)抓取由日本 Himawari 8 气象卫星拍摄的接近实时的地球照片,并将它设置成你的桌面背景

99、loguru:一个让 Python 记录日志变得简单的库

100、weixin_crawler:基于 Scrapy、Flask、Echarts、Elasticsearch 等实现的爬虫。自带 UI 界面、分析报告、搜索功能
推荐阅读
通过简历造假进了大公司之后......
肝了6个月,《Python黑魔法指南》全新版本 v2.0 上线发布
那个从深圳流水线工人去Google上班程序媛,最近失业了!
华为搜索引擎面世!
卧槽,又一款Python神器
感动:Python 与 Excel 终于在一起了
再见,Visio!
推荐两个团队技术号
Github研习社:
目前是由国内985博士,硕士组成的团体发起并运营,主要分享和研究业界开源项目,学习资源,程序设计,学术交流。
回复就无套路送你一份自学大礼包。
机器学习研习社目前是由国内985博士,硕士组成的团体发起并运营。主要分享和研究机器学习、深度学习、NLP 、Python,大数据等前沿知识、干货笔记和优质资源。
回复就无套路送你一份机器学习大礼包。
后台回复【大礼包】送你我整理的全套Python自学资料,再也不用到处找资料了
本文分享自微信公众号 - Python绿色通道(Python_channel)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。











