
本文转载自:安秦
概述
稍微了解行业现状的开发者都知道,现在前端“ES6即正义”,然而浏览器的支持还是进行时。所以我们会用一个神奇的工具将ES6都给转换成目前支持比较广泛的ES5语法。对,说的就是Babel。
本文不再介绍Babel是什么也不讲怎么用,这类文章很多,我也不觉得自己能写得更好。这篇文章的关注点是另一个方面,也是很多人会好奇的事情,Babel的工作原理是什么。
Babel工作的三个阶段
首先要说明的是,现在前端流行用的WebPack或其他同类工程化工具会将源文件组合起来,这部分并不是Babel完成的,是这些打包工具自己实现的,Babel的功能非常纯粹,以字符串的形式将源代码传给它,它就会返回一段新的代码字符串(以及sourcemap)。他既不会运行你的代码,也不会将多个代码打包到一起,它就是个编译器,输入语言是ES6+,编译目标语言是ES5。
在Babel官网,plugins菜单下藏着一个链接:thejameskyle/the-super-tiny-compiler。它已经解释了整个工作过程,有耐心者可以自己研究,当然也可以继续看我的文章。
Babel的编译过程跟绝大多数其他语言的编译器大致同理,分为三个阶段:
解析:将代码字符串解析成抽象语法树
变换:对抽象语法树进行变换操作
再建:根据变换后的抽象语法树再生成代码字符串
像我们在.babelrc里配置的presets和plugins都是在第2步工作的。
举个例子,首先你输入的代码如下:
if (1 > 0) { alert('hi'); }
经过第1步得到一个如下的对象:
{ "type": "Program", // 程序根节点 "body": [ // 一个数组包含所有程序的顶层语句 { "type": "IfStatement", // 一个if语句节点 "test": { // if语句的判断条件 "type": "BinaryExpression", // 一个双元运算表达式节点 "operator": ">", // 运算表达式的运算符 "left": { // 运算符左侧值 "type": "Literal", // 一个常量表达式 "value": 1 // 常量表达式的常量值 }, "right": { // 运算符右侧值 "type": "Literal", "value": 0 } }, "consequent": { // if语句条件满足时的执行内容 "type": "BlockStatement", // 用{}包围的代码块 "body": [ // 代码块内的语句数组 { "type": "ExpressionStatement", // 一个表达式语句节点 "expression": { "type": "CallExpression", // 一个函数调用表达式节点 "callee": { // 被调用者 "type": "Identifier", // 一个标识符表达式节点 "name": "alert" }, "arguments": [ // 调用参数 { "type": "Literal", "value": "hi" } ] } } ] }, "alternative": null // if语句条件未满足时的执行内容 } ] }
Babel实际生成的语法树还会包含更多复杂信息,这里只展示比较关键的部分,欲了解更多关于ES语言抽象语法树规范可阅读:The ESTree Spec。
用图像更简单地表达上面的结构:
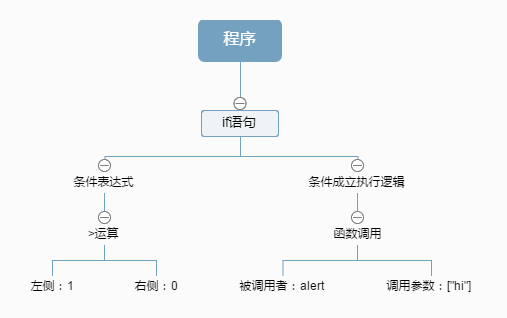
第1步转换的过程中可以验证语法的正确性,同时由字符串变为对象结构后更有利于精准地分析以及进行代码结构调整。
第2步原理就很简单了,就是遍历这个对象所描述的抽象语法树,遇到哪里需要做一下改变,就直接在对象上进行操作,比如我把IfStatement给改成WhileStatement就达到了把条件判断改成循环的效果。
第3步也简单,递归遍历这颗语法树,然后生成相应的代码,大概的实现逻辑如下:
const types = { Program (node) { return node.body.map(child => generate(child)); }, IfStatement (node) { let code = `if (${generate(node.test)}) ${generate(node.consequent)}`; if (node.alternative) { code += `else ${generate(node.alternative)}`; } return code; }, BlockStatement (node) { let code = node.body.map(child => generate(child)); code = `{ ${code} }`; return code; }, ...... }; function generate(node) { return types[node.type](node); } const ast = Babel.parse(...); // 将代码解析成语法树 const generatedCode = generate(ast); // 将语法树重新组合成代码
抽象语法树是如何产生的
第2、3步相信不用花多少篇幅大家自己都能理解,重点介绍的第一步来了。
解析这一步又分成两个步骤:
分词:将整个代码字符串分割成 语法单元 数组
语义分析:在分词结果的基础之上分析 语法单元之间的关系
我们一步步讲。
分词
首先解释一下什么是语法单元:语法单元是被解析语法当中具备实际意义的最小单元,通俗点说就是类似于自然语言中的词语。
看这句话“2020年奥运会将在东京举行”,不论词性及主谓关系等,人第一步会把这句话拆分成:2020年、奥运会、将、在、东京、举行。这就是分词:把整句话拆分成有意义的最小颗粒,这些小块不能再被拆分,否则就失去它所能表达的意义了。
那么回到代码的解析当中,JS代码有哪些语法单元呢?大致有以下这些(其他语言也许类似但通常都有区别):
空白:JS中连续的空格、换行、缩进等这些如果不在字符串里,就没有任何实际逻辑意义,所以把连续的空白符直接组合在一起作为一个语法单元。
注释:行注释或块注释,虽然对于人类来说有意义,但是对于计算机来说知道这是个“注释”就行了,并不关心内容,所以直接作为一个不可再拆的语法单元
字符串:对于机器而言,字符串的内容只是会参与计算或展示,里面再细分的内容也是没必要分析的
数字:JS语言里就有16、10、8进制以及科学表达法等数字表达语法,数字也是个具备含义的最小单元
标识符:没有被引号扩起来的连续字符,可包含字母、_、$、及数字(数字不能作为开头)。标识符可能代表一个变量,或者true、false这种内置常量、也可能是if、return、function这种关键字,是哪种语义,分词阶段并不在乎,只要正确切分就好了。
运算符:+、-、*、/、>、<等等
括号:(...)可能表示运算优先级、也可能表示函数调用,分词阶段并不关注是哪种语义,只把“(”或“)”当做一种基本语法单元
还有其他:如中括号、大括号、分号、冒号、点等等不再一一列举
分词的过过程从逻辑来讲并不难解释,但是这是个精细活,要考虑清楚所有的情况。还是以一个代码为例:
if (1 > 0) { alert("if \"1 > 0\""); }
我们希望得到的分词是:
'if' ' ' '(' '1' ' ' '>' ' ' ')' ' ' '{' '\n ' 'alert' '(' '"if \"1 > 0\""' ')' ';' '\n' '}'
注意其中"if \"1 > 0\""是作为一个语法单元存在,没有再查分成if、1、>、0这样,而且其中的转译符会阻止字符串早结束。
这拆分过程其实没啥可取巧的,就是简单粗暴地一个字符一个字符地遍历,然后分情况讨论,整个实现方法就是顺序遍历和大量的条件判断。我用一个简单的实现来解释,在关键的地方注释,我们只考虑上面那段代码里存在的语法单元类型。
``function tokenizeCode (code) {
const tokens = []; // 结果数组
for (let i = 0; i < code.length; i++) {
// 从0开始,一个字符一个字符地读取
let currentChar = code.charAt(i);
if (currentChar === ';') {
// 对于这种只有一个字符的语法单元,直接加到结果当中
tokens.push({
type: 'sep',
value: ';',
});
// 该字符已经得到解析,不需要做后续判断,直接开始下一个
continue;
}
if (currentChar === '(' || currentChar === ')') {
// 与 ; 类似只是语法单元类型不同
tokens.push({
type: 'parens',
value: currentChar,
});
continue;
}
if (currentChar === '}' || currentChar === '{') {
// 与 ; 类似只是语法单元类型不同
tokens.push({
type: 'brace',
value: currentChar,
});
continue;
}
if (currentChar === '>' || currentChar === '<') {
// 与 ; 类似只是语法单元类型不同
tokens.push({
type: 'operator',
value: currentChar,
});
continue;
}
if (currentChar === '"' || currentChar === ''') {
// 引号表示一个字符传的开始
const token = {
type: 'string',
value: currentChar, // 记录这个语法单元目前的内容
};
tokens.push(token);
const closer = currentChar;
let escaped = false; // 表示下一个字符是不是被转译的
// 进行嵌套循环遍历,寻找字符串结尾
for (i++; i < code.length; i++) {
currentChar = code.charAt(i);
// 先将当前遍历到的字符无条件加到字符串的内容当中
token.value += currentChar;
if (escaped) {
// 如果当前转译状态是true,就将改为false,然后就不特殊处理这个字符
escaped = false;
} else if (currentChar === '\') {
// 如果当前字符是 \ ,将转译状态设为true,下一个字符不会被特殊处理
escaped = true;
} else if (currentChar === closer) {
break;
}
}
continue;
}
if (/[0-9]/.test(currentChar)) {
// 数字是以0到9的字符开始的
const token = {
type: 'number',
value: currentChar,
};
tokens.push(token);
for (i++; i < code.length; i++) {
currentChar = code.charAt(i);
if (/[0-9.]/.test(currentChar)) {
// 如果遍历到的字符还是数字的一部分(0到9或小数点)
// 这里暂不考虑会出现多个小数点以及其他进制的情况
token.value += currentChar;
} else {
// 遇到不是数字的字符就退出,需要把 i 往回调,
// 因为当前的字符并不属于数字的一部分,需要做后续解析
i--;
break;
}
}
continue;
}
if (/[a-zA-Z$_]/.test(currentChar)) {
// 标识符是以字母、$、_开始的
const token = {
type: 'identifier',
value: currentChar,
};
tokens.push(token);
// 与数字同理
for (i++; i < code.length; i++) {
currentChar = code.charAt(i);
if (/[a-zA-Z0-9$_]/.test(currentChar)) {
token.value += currentChar;
} else {
i--;
break;
}
}
continue;
}
if (/\s/.test(currentChar)) {
// 连续的空白字符组合到一起
const token = {
type: 'whitespace',
value: currentChar,
};
tokens.push(token);
// 与数字同理
for (i++; i < code.length; i++) {
currentChar = code.charAt(i);
if (/\s]/.test(currentChar)) {
token.value += currentChar;
} else {
i--;
break;
}
}
continue;
}
// 还可以有更多的判断来解析其他类型的语法单元
// 遇到其他情况就抛出异常表示无法理解遇到的字符
throw new Error('Unexpected ' + currentChar);
}
return tokens;
}
const tokens = tokenizeCode( if (1 > 0) { alert("if 1 > 0"); } );
``
以上代码是我个人的实现方式,与babel实际略有不同,但主要思路一样。
执行结果如下:
[ { type: "whitespace", value: "\n" }, { type: "identifier", value: "if" }, { type: "whitespace", value: " " }, { type: "parens", value: "(" }, { type: "number", value: "1" }, { type: "whitespace", value: " " }, { type: "operator", value: ">" }, { type: "whitespace", value: " " }, { type: "number", value: "0" }, { type: "parens", value: ")" }, { type: "whitespace", value: " " }, { type: "brace", value: "{" }, { type: "whitespace", value: "\n " }, { type: "identifier", value: "alert" }, { type: "parens", value: "(" }, { type: "string", value: "\"if 1 > 0\"" }, { type: "parens", value: ")" }, { type: "sep", value: ";" }, { type: "whitespace", value: "\n" }, { type: "brace", value: "}" }, { type: "whitespace", value: "\n" }, ]
经过这一步的分词,这个数组就比摊开的字符串更方便进行下一步处理了。
语义分析
语义分析就是把词汇进行立体的组合,确定有多重意义的词语最终是什么意思、多个词语之间有什么关系以及又应该再哪里断句等。
在编程语言解释当中,这就是要最终生成语法树的步骤了。不像自然语言,像“从句”这种结构往往最多只有一层,编程语言的各种从属关系更加复杂。
在编程语言的解析中有两个很相似但是又有区别的重要概念:
语句:语句是一个具备边界的代码区域,相邻的两个语句之间从语法上来讲互不干扰,调换顺序虽然可能会影响执行结果,但不会产生语法错误
比如return true、var a = 10、if (...) {...}表达式:最终有个结果的一小段代码,它的特点是可以原样嵌入到另一个表达式
比如myVar、1+1、str.replace('a', 'b')、i < 10 && i > 0等
很多情况下一个语句可能只包含一个表达式,比如console.log('hi');。estree标准当中,这种语句节点称作ExpressionStatement。
语义分析的过程又是个遍历语法单元的过程,不过相比较而言更复杂,因为分词过程中,每个语法单元都是独立平铺的,而语法分析中,语句和表达式会以树状的结构互相包含。针对这种情况我们可以用栈,也可以用递归来实现。
我继续上面的例子给出语义分析的代码,代码很长,先在最开头说明几个函数是做什么的:
nextStatement:读取并返回下一个语句
nextExpression:读取并返回下一个表达式
nextToken:读取下一个语法单元(或称符号),赋值给curToken
stash:暂存当前读取符号的位置,方便在需要的时候返回
rewind:返回到上一个暂存点
commit:上一个暂存点不再被需要,将其销毁
这里stash、rewind、commit都跟读取位置暂存相关,什么样的情况会需要返回到暂存点呢?有时同一种语法单元有可能代表不同类型的表达式的开始。先stash,然后按照其中一种尝试解析,如果解析成功了,那么暂存点就没用了,commit将其销毁。如果解析失败了,就用rewind回到原来的位置再按照另一种方式尝试去解析。
以下是代码:
`function parse (tokens) {
let i = -1; // 用于标识当前遍历位置
let curToken; // 用于记录当前符号
// 读取下一个语句
function nextStatement () {
// 暂存当前的i,如果无法找到符合条件的情况会需要回到这里
stash();
// 读取下一个符号
nextToken();
if (curToken.type === 'identifier' && curToken.value === 'if') {
// 解析 if 语句
const statement = {
type: 'IfStatement',
};
// if 后面必须紧跟着 (
nextToken();
if (curToken.type !== 'parens' || curToken.value !== '(') {
throw new Error('Expected ( after if');
}
// 后续的一个表达式是 if 的判断条件
statement.test = nextExpression();
// 判断条件之后必须是 )
nextToken();
if (curToken.type !== 'parens' || curToken.value !== ')') {
throw new Error('Expected ) after if test expression');
}
// 下一个语句是 if 成立时执行的语句
statement.consequent = nextStatement();
// 如果下一个符号是 else 就说明还存在 if 不成立时的逻辑
if (curToken === 'identifier' && curToken.value === 'else') {
statement.alternative = nextStatement();
} else {
statement.alternative = null;
}
commit();
return statement;
}
if (curToken.type === 'brace' && curToken.value === '{') {
// 以 { 开头表示是个代码块,我们暂不考虑JSON语法的存在
const statement = {
type: 'BlockStatement',
body: [],
};
while (i < tokens.length) {
// 检查下一个符号是不是 }
stash();
nextToken();
if (curToken.type === 'brace' && curToken.value === '}') {
// } 表示代码块的结尾
commit();
break;
}
// 还原到原来的位置,并将解析的下一个语句加到body
rewind();
statement.body.push(nextStatement());
}
// 代码块语句解析完毕,返回结果
commit();
return statement;
}
// 没有找到特别的语句标志,回到语句开头
rewind();
// 尝试解析单表达式语句
const statement = {
type: 'ExpressionStatement',
expression: nextExpression(),
};
if (statement.expression) {
nextToken();
if (curToken.type !== 'EOF' && curToken.type !== 'sep') {
throw new Error('Missing ; at end of expression');
}
return statement;
}
}
// 读取下一个表达式
function nextExpression () {
nextToken();
if (curToken.type === 'identifier') {
const identifier = {
type: 'Identifier',
name: curToken.value,
};
stash();
nextToken();
if (curToken.type === 'parens' && curToken.value === '(') {
// 如果一个标识符后面紧跟着 ( ,说明是个函数调用表达式
const expr = {
type: 'CallExpression',
caller: identifier,
arguments: [],
};
stash();
nextToken();
if (curToken.type === 'parens' && curToken.value === ')') {
// 如果下一个符合直接就是 ) ,说明没有参数
commit();
} else {
// 读取函数调用参数
rewind();
while (i < tokens.length) {
// 将下一个表达式加到arguments当中
expr.arguments.push(nextExpression());
nextToken();
// 遇到 ) 结束
if (curToken.type === 'parens' && curToken.value === ')') {
break;
}
// 参数间必须以 , 相间隔
if (curToken.type !== 'comma' && curToken.value !== ',') {
throw new Error('Expected , between arguments');
}
}
}
commit();
return expr;
}
rewind();
return identifier;
}
if (curToken.type === 'number' || curToken.type === 'string') {
// 数字或字符串,说明此处是个常量表达式
const literal = {
type: 'Literal',
value: eval(curToken.value),
};
// 但如果下一个符号是运算符,那么这就是个双元运算表达式
// 此处暂不考虑多个运算衔接,或者有变量存在
stash();
nextToken();
if (curToken.type === 'operator') {
commit();
return {
type: 'BinaryExpression',
left: literal,
right: nextExpression(),
};
}
rewind();
return literal;
}
if (curToken.type !== 'EOF') {
throw new Error('Unexpected token ' + curToken.value);
}
}
// 往后移动读取指针,自动跳过空白
function nextToken () {
do {
i++;
curToken = tokens[i] || { type: 'EOF' };
} while (curToken.type === 'whitespace');
}
// 位置暂存栈,用于支持很多时候需要返回到某个之前的位置
const stashStack = [];
function stash (cb) {
// 暂存当前位置
stashStack.push(i);
}
function rewind () {
// 解析失败,回到上一个暂存的位置
i = stashStack.pop();
curToken = tokens[i];
}
function commit () {
// 解析成功,不需要再返回
stashStack.pop();
}
const ast = {
type: 'Program',
body: [],
};
// 逐条解析顶层语句
while (i < tokens.length) {
const statement = nextStatement();
if (!statement) {
break;
}
ast.body.push(statement);
}
return ast;
}
const ast = parse([
{ type: "whitespace", value: "\n" },
{ type: "identifier", value: "if" },
{ type: "whitespace", value: " " },
{ type: "parens", value: "(" },
{ type: "number", value: "1" },
{ type: "whitespace", value: " " },
{ type: "operator", value: ">" },
{ type: "whitespace", value: " " },
{ type: "number", value: "0" },
{ type: "parens", value: ")" },
{ type: "whitespace", value: " " },
{ type: "brace", value: "{" },
{ type: "whitespace", value: "\n " },
{ type: "identifier", value: "alert" },
{ type: "parens", value: "(" },
{ type: "string", value: ""if 1 > 0"" },
{ type: "parens", value: ")" },
{ type: "sep", value: ";" },
{ type: "whitespace", value: "\n" },
{ type: "brace", value: "}" },
{ type: "whitespace", value: "\n" },
]);
`
最终得到结果:
{ "type": "Program", "body": [ { "type": "IfStatement", "test": { "type": "BinaryExpression", "left": { "type": "Literal", "value": 1 }, "right": { "type": "Literal", "value": 0 } }, "consequent": { "type": "BlockStatement", "body": [ { "type": "ExpressionStatement", "expression": { "type": "CallExpression", "caller": { "type": "Identifier", "value": "alert" }, "arguments": [ { "type": "Literal", "value": "if 1 > 0" } ] } } ] }, "alternative": null } ] }
以上就是语义解析的部分主要思路。注意现在的nextExpression已经颇为复杂,但实际实现要比现在这里展示的要更复杂很多,因为这里根本没有考虑单元运算符、运算优先级等等。
结语
真正看下来,其实没有哪个地方的原理特别高深莫测,就是精细活,需要考虑到各种各样的情况。总之要做一个完整的语法解释器需要的是十分的细心与耐心。
在并不是特别远的过去,做web项目,前端技术都还很简单,甚至那时候的网页都尽量不用JavaScript。之后jQuery的诞生真正地让JS成为了web应用开发核心,web前端工程师这种职业也才真正独立出来。但后来随着语言预处理和打包等技术的出现,前端真的是越来越强大但是技术栈也真的是变得越来越复杂。虽然有种永远都学不完的感觉,但这更能体现出我们前端工程存在的价值,不是吗?
最后
看完点个赞,分享一下吧,让更多的朋友能够看到。如果你喜欢前端开发博客的分享,就给公号标个星吧,这样就不会错过我的文章了。

好文和朋友一起看~
本文分享自微信公众号 - 前端开发博客(caibaojian_com)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。











