
本文源码:GitHub·点这里 || GitEE·点这里
一、搭建Kafka环境
1、下载解压
-- 下载
wget http://mirror.bit.edu.cn/apache/kafka/2.2.0/kafka_2.11-2.2.0.tgz
-- 解压
tar -zxvf kafka_2.11-2.2.0.tgz
-- 重命名
mv kafka_2.11-2.2.0 kafka2.11
2、启动Kafka服务
kafka依赖ZooKeeper服务,需要本地安装并启动ZooKeeper。
-- 执行位置
-- /usr/local/mysoft/kafka2.11
bin/kafka-server-start.sh config/server.properties
3、查看服务
ps -aux |grep kafka
4、开放地址端口
-- 基础路径
-- /usr/local/mysoft/kafka2.11/config
vim server.properties
-- 添加下面注释
advertised.listeners=PLAINTEXT://192.168.72.130:9092
二、Kafka基础概念
1、基础描述
Kafka是由Apache开源,具有分布式、分区的、多副本的、多订阅者,基于Zookeeper协调的分布式处理平台,由Scala和Java语言编写。通常用来搜集用户在应用服务中产生的动作日志数据,并高速的处理。日志类的数据需要高吞吐量的性能要求,对于像Hadoop一样的日志数据和离线分析系统,但又要求实时处理的限制,这是一个可行的解决方案。Kafka的目的是通过Hadoop的并行加载机制来统一线上和离线的消息处理,也是为了通过集群来提供实时的消息。
2、功能特点
(1)、通过磁盘数据结构提供消息的持久化,消息存储也能够保持长时间稳定性;
(2)、高吞吐量,即使是非常普通的硬件Kafka也可以支持每秒超高的并发量;
(3)、支持通过Kafka服务器和消费机集群来分区消息;
(4)、支持Hadoop并行数据加载;
(5)、API包封装的非常好,简单易用,上手快 ;
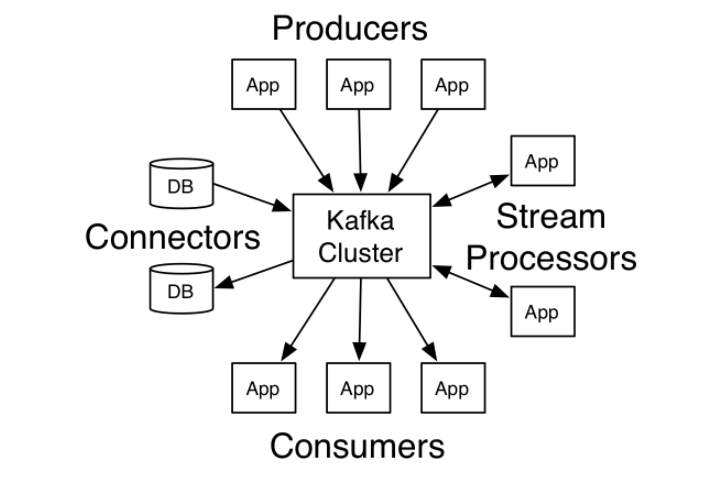
(6)、分布式消息队列。Kafka对消息保存时根据Topic进行归类,发送消息者称为Producer,消息接受者称为Consumer;
3、消息功能
- 点对点模式
点对点模型通常是一个基于拉取或者轮询的消息传递模型,消费者主动拉取数据,消息收到后从队列移除消息,这种模型不是将消息推送到客户端,而是从队列中请求消息。特点是发送到队列的消息被一个且只有一个消费者接收处理,即使有多个消费者监听队列也是如此。
- 发布订阅模式
发布订阅模型则是一个基于推送的消息传送模型,消息产生后,推送给所有订阅者。发布订阅模型可以有多种不同的订阅者,临时订阅者只在主动监听主题时才接收消息,而持久订阅者则监听主题的所有消息,即使当前订阅者不可用,处于离线状态。
4、消息队列作用
- 程序解耦,生产者和消费者独立,各自异步执行;
- 消息数据进行持久化存储,直到被全部消费,规避了数据丢失风险;
- 流量削峰,使用消息队列承接访问压力,尽量避免程序雪崩 ;
- 降低进程间的耦合度,系统部分组件崩溃时,不会影响到整个系统;
- 保证消息顺序执行,解决特定场景业务需求 ;
5、专业术语简介
- Broker
一台kafka服务器就是一个broker。一个集群由多个broker组成。一个broker可以容纳多个topic。
- Producer
消息生产者,就是向kafka broker发消息的客户端。
- Consumer
消息消费者,向kafka broker取消息的客户端。
- Topic
每条发布到Kafka集群的消息都有一个类别,这个类别被称为Topic,可以理解为一个队列。
- Consumer Group
每个Consumer属于一个特定的Consumer Group,可为每个Consumer指定group name,若不指定group name则属于默认的分组。
- Partition
一个庞大大的topic可以分布到多个broker上,一个topic可以分为多个partition,每个partition是一个有序的队列。partition中的每条消息都会被分配一个有序的id。kafka只保证按一个partition中的顺序将消息发给consumer,不保证一个topic的整体的顺序。Partition是物理上的概念,方便在集群中扩展,提高并发。
三、整合SpringBoot2框架
1、案例结构
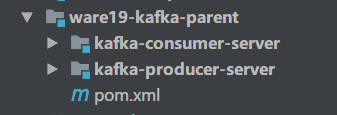
消息生产者 :
kafka-producer-server消息消费方 :
kafka-consumer-server
2、基础依赖
<!-- SpringBoot依赖 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!-- kafka 依赖 -->
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
<version>2.2.4.RELEASE</version>
</dependency>
3、生产者配置
spring:
kafka:
bootstrap-servers: 127.0.0.1:9092
4、消息生成
@RestController
public class ProducerWeb {
@Resource
private KafkaTemplate<String, String> kafkaTemplate;
@RequestMapping("/send")
public String sendMsg () {
MsgLog msgLog = new MsgLog(1,"消息生成",
1,"消息日志",new Date()) ;
String msg = JSON.toJSONString(msgLog) ;
// 这里Topic如果不存在,会自动创建
kafkaTemplate.send("cicada-topic", msg);
return msg ;
}
}
5、消费者配置
spring:
kafka:
bootstrap-servers: 127.0.0.1:9092
consumer:
group-id: test-consumer-group
6、消息消费
@Component
public class ConsumerMsg {
private static Logger LOGGER = LoggerFactory.getLogger(ConsumerMsg.class);
@KafkaListener(topics = "cicada-topic")
public void listenMsg (ConsumerRecord<?,String> record) {
String value = record.value();
LOGGER.info("ConsumerMsg====>>"+value);
}
}
四、消息流程分析
1、生产者分析
- 写入方式
生产者基于推push推模式将消息发布到broker,每条消息都被追加到分区patition中,属于磁盘顺序写,效率比随机写内存要高,保障kafka高吞吐量。
- 分区概念
消息发送时都被发送到一个topic,而topic是由Partition Logs(分区日志)组成,其组织结构如下图所示:
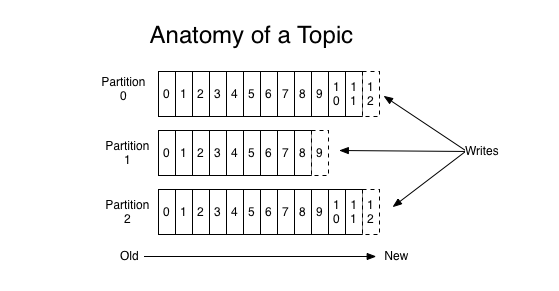
 每个Partition中的消息都是有序的,生产的消息被不断追加到Partitionlog上,其中的每一个消息都被赋予了一个唯一的offset值。每个Partition可以通过调整以适配它所在的机器,而一个topic又可以有多个Partition组成,因此整个集群就可以适应任意大小的数据。分区的原则:指定patition,则直接使用;未指定patition但指定key,通过对key的value进行hash出一个patition;patition和key都未指定,使用轮询选出一个patition。
每个Partition中的消息都是有序的,生产的消息被不断追加到Partitionlog上,其中的每一个消息都被赋予了一个唯一的offset值。每个Partition可以通过调整以适配它所在的机器,而一个topic又可以有多个Partition组成,因此整个集群就可以适应任意大小的数据。分区的原则:指定patition,则直接使用;未指定patition但指定key,通过对key的value进行hash出一个patition;patition和key都未指定,使用轮询选出一个patition。
2、消费者分析
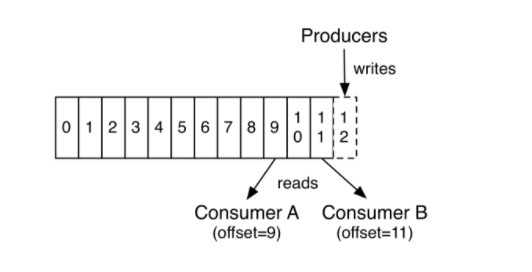
- 消费图解
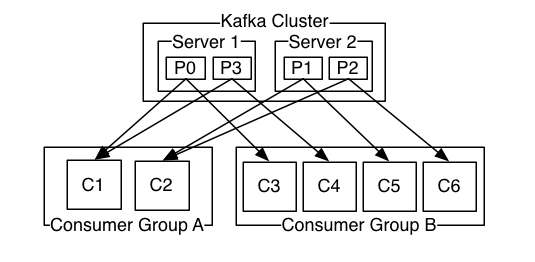
消费者是以consumer group消费者组的方式工作,由一个或者多个消费者组成一个组,共同消费一个topic。每个分区在同一时间只能由group中的一个消费者读取,但是多个group可以同时消费一个partition。
- 消费方式
消费者采用pull拉模式从broker中读取数据。对于Kafka而言,pull模式更合适,它可简化broker的设计,consumer可自主控制消费消息的速率,同时consumer可以自己控制消费方式——即可批量消费也可逐条消费,同时还能选择不同的提交方式从而实现不同的数据传输场景。
五、源代码地址
GitHub·地址
https://github.com/cicadasmile/middle-ware-parent
GitEE·地址
https://gitee.com/cicadasmile/middle-ware-parent

推荐阅读:SpringBoot2整合中间件
《整合 ElasticSearch框架,实现高性能搜索引擎》












