
说起Serverless这个词,我想大家应该都不陌生,那么Serverless这个词到底是什么意思?Serverless到底能解决什么问题?可能很多朋友还没有深刻的体会和体感,这篇文章我就和大家一起聊聊Serverless。
什么是Serverless
我们先将Serverless这个词拆开来看。Server,大家都知道是服务器的意思,说明Serverless解决的问题范围在服务端。Less,大家肯定也知道它的意思是较少的。那么Serverless连起来,再稍加修饰,那就是较少的关心服务器的意思。
Serverfull时代
我们都知道,在研发侧都会有研发人员和运维人员两个角色,要开发一个新系统的时候,研发人员根据产品经理的PRD开始写代码开发功能,当功能开发、测试完之后,要发布到服务器。这个时候开始由运维人员规划服务器规格、服务器数量、每个服务部署的节点数量、服务器的扩缩容策略和机制、发布服务过程、服务优雅上下线机制等等。这种模式是研发和运维隔离,服务端运维都由专门的运维人员处理,而且很多时候是靠纯人力处理,也就是Serverfull时代。
DevOps时代
互联网公司里最辛苦的是谁?我相信大多数都是运维同学。白天做各种网络规划、环境规划、数据库规划等等,晚上熬夜发布新版本,做上线保障,而且很多事情是重复性的工作。然后慢慢就有了赋能研发这样的声音,运维同学帮助研发同学做一套运维控制台,可以让研发同学在运维控制台上自行发布服务、查看日志、查询数据。这样一来,运维同学主要维护这套运维控制台系统,并且不断完善功能,轻松了不少。这就是研发兼运维的DevOps时代。
Serverless时代
渐渐的,研发同学和运维同学的关注点都在运维控制台了,运维控制台的功能越来越强大,比如根据运维侧的需求增加了自动弹性扩缩、性能监控的功能,根据研发侧的需求增加了自动化发布的流水线功能。因为有了这套系统,代码质量检测、单元测试、打包编译、部署、集成测试、灰度发布、弹性扩缩、性能监控、应用防护这一系列服务端的工作基本上不需要人工参与处理了。这就是NoOps,Serverless时代。
Serverless在编程教育中的应用
2020年注定是不平凡的一年,疫情期间,多少家企业如割韭菜般倒下,又有多少家企业如雨后春笋般茁壮成长,比如在线教育行业。
没错,在线教育行业是这次疫情的最大受益者,在在线教育在这个行业里,有一个细分市场是在线编程教育,尤其是少儿编程教育和面向非专业人士的编程教育,比如编程猫、斑马AI、小象学院等。这些企业的在线编程系统都有一些共同的特点和诉求:
屏幕一侧写代码,执行代码,另一侧显示运行结果。
根据题目编写的代码都是代码块,每道题的代码量不会很大。
运行代码的速度要快。
支持多种编程语言。
能支撑不可预计的流量洪峰冲击。
例如小象学院的编程课界面:
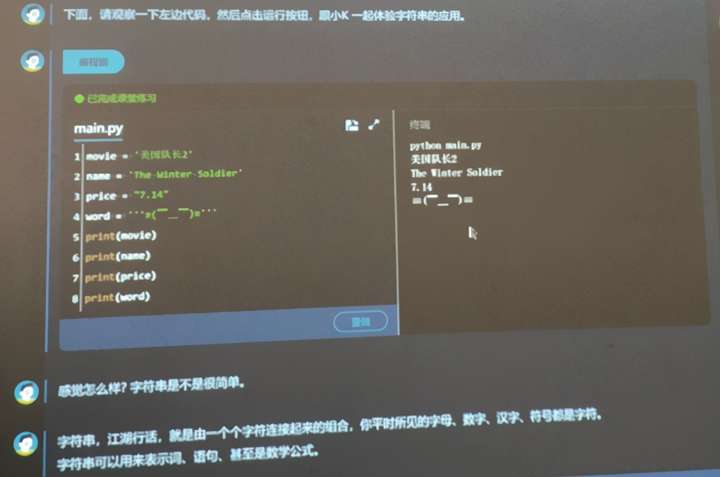
结合上述这些特点和诉求,不难看出,构建这样一套在线编程系统的核心在于有一个支持多种编程语言的、健壮高可用的代码运行环境。
那么我们先来看看传统的实现架构:
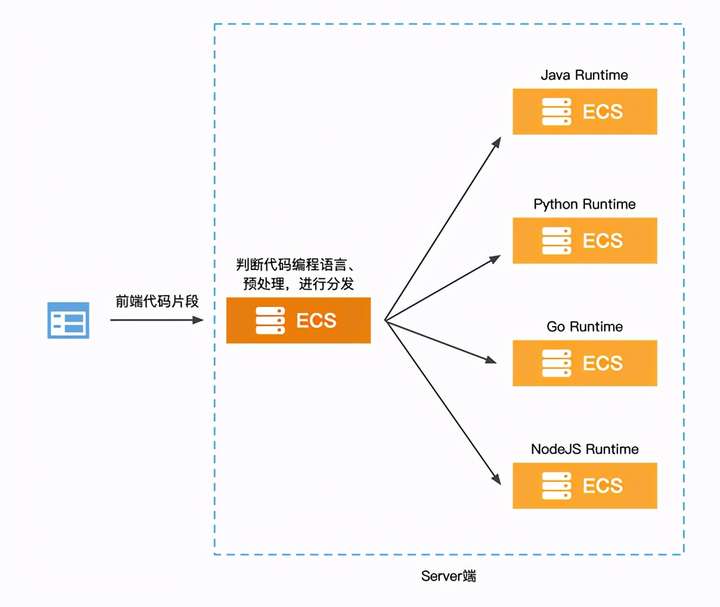
从High Level的架构来看,前端只需要将代码片段和编程语言的标识传给Server端即可,然后等待响应展示结果。所以整个Server端要负责对不同语言的代码进行分类、预处理然后传给不同编程语言的Runtime。这种架构有以下几个比较核心的问题。
工作量大,灵活性差
首先是研发和运维工作量的问题,当市场有新的需求,或者洞察到新业务模式时需要增加编程语言,此时研发侧需要增加编程代码分类和预处理的逻辑,另外需要构建对应编程语言的Runtime。在运维侧需要规划支撑新语言的服务器规格以及数量,还有整体的CICD流程等。所以支持新的编程语言这个需求要落地,需要研发、运维花费不少的时间来实现,再加上黑/白盒测试和CICD流程测试的时间,对市场需求的支撑不能快速的响应,灵活性相对较差。
高可用自己兜底
其次整个在线编程系统的稳定性是重中之重。所以所有Server端服务的高可用架构都需要自己搭建,用以保证流量高峰场景和稳态场景下的系统稳定。高可用一方面是代码逻辑编写的是否优雅和完善,另一方面是部署服务的集群,无论是ECS集群还是K8s集群,都需要研发和运维同学一起规划,那么对于对编程语言进行分类和预处理的服务来讲,尚能给定一个节点数,但是对于不同语言的Runtime服务来讲,市场需求随时会变,所以不好具体衡量每个服务的节点数。另外很重要的一点是所以服务的扩容,缩容机制都需要运维同学来实时手动操作,即便是通过脚本实现自动化,那么ECS弹起的速度也是远达不到业务预期的。
成本控制粒度粗
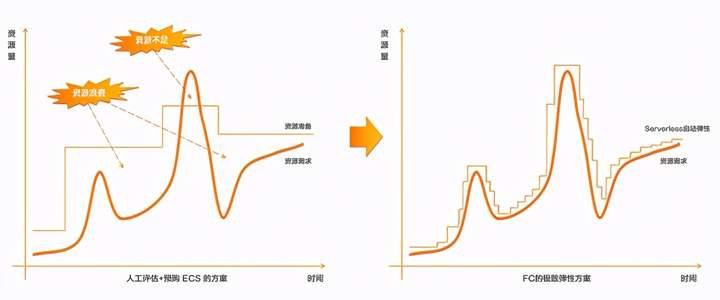
再次是整个IaaS资源的成本控制,我们都知道这种在线教育是有明显的流量潮汐的,比如上午10点到12点,下午3点到5点,晚上8点到10点这几个时段是流量比较大的时候,其他时间端流量比较小,而且夜晚更是没什么流量。所以在这种情况下,传统的部署架构无法做到IaaS资源和流量的贴合。举个例子,加入为了应对流量高峰时期,需要20台ECS搭建集群来承载流量冲击,此时每台ECS的资源使用率可能在70%以上,利用率较高,但是在流量小的时候和夜晚,每台ECS的资源使用率可能就是百分之十几甚至更低,这就是一种资源浪费。
Serverless架构
那么我们来看看如何使用Serverless架构来实现同样的功能,并且解决上述几个问题。在选择Serverless产品时,在国内自然而然优先想到的就是阿里云的产品。阿里云有两款Serverless架构的产品Serverless 应用引擎和函数计算,这里我们使用函数计算来实现编程教育的场景。
函数计算(Function Compute)是事件驱动的全托管计算服务,简称FC。使用函数计算,我们无需采购与管理服务器等基础设施,只需编写并上传代码。函数计算为您准备好计算资源,弹性地、可靠地运行任务,并提供日志查询、性能监控和报警等功能。
这里不对FC的含义做过多赘述,只举一个例子。FC中有两个概念,一个是服务,一个是函数。一个服务包含多个函数:
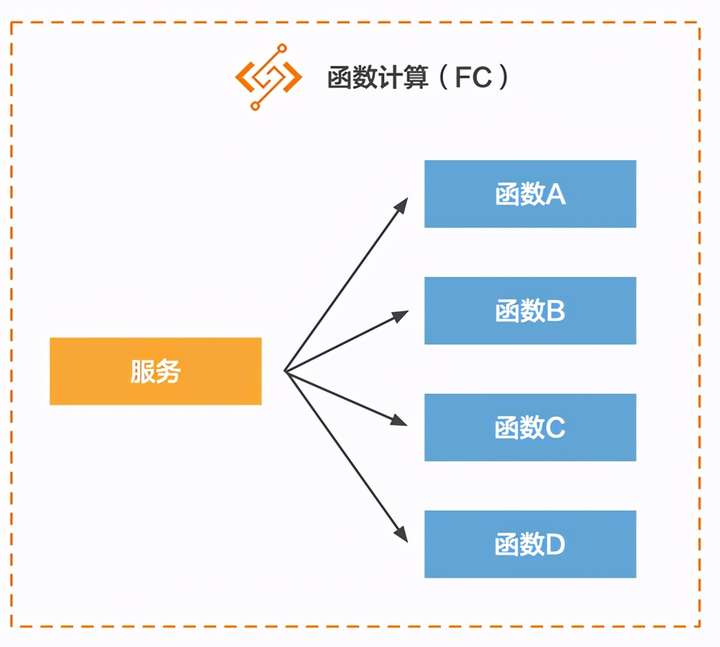
这里拿Java微服务架构来对应,可以理解为,FC中的服务是Java中的一个类,FC中的函数是Java类中的一个方法:
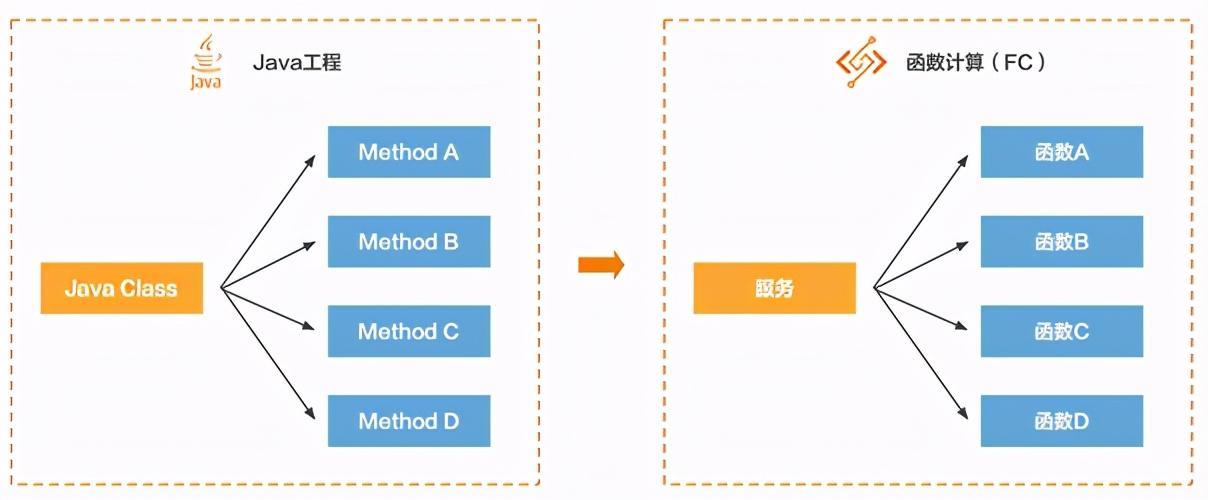
但是Java类中的方法固然只能是Java代码,而FC中的函数可以设置不同语言的Runtime来运行不同的编程语言:
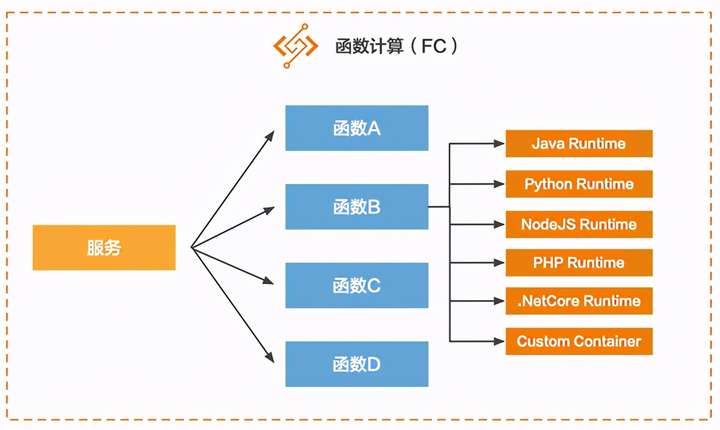
这个结构理解清楚之后,我们来看看如何调用FC的函数,这里会引出一个触发器的概念。我们最常使用的HTTP请求协议其实就是一种类型的触发器,在FC里称为HTTP触发器,除了HTTP触发器以外,还提供了OSS(对象存储)触发器、SLS(日志服务)触发器、定时触发器、MNS触发器、CDN触发器等。
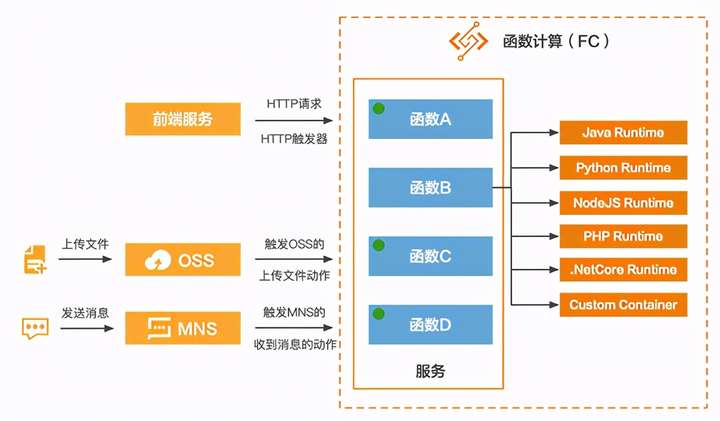
从上图可以大概理解,我们可以通过多种途径调用FC中的函数。举例两个场景,比如每当我在指定的OSS Bucket的某个目录下上传一张图片后,就可以触发FC中的函数,函数的逻辑是将刚刚上传的图片下载下来,然后对图片做处理,然后再上传回OSS。再比如向MNS的某个队列发送一条消息,然后触发FC中的函数来处理针对这条消息的逻辑。
最后我们再来看看FC的高可用。每一个函数在运行代码时底层肯定还是IaaS资源,但我们只需要给每个函数设置运行代码时需要的内存数即可,最小128M,最大3G,对使用者而言,不需要考虑多少核数,也不需要知道代码运行在什么样的服务器上,不需要关心启动了多少个函数实例,也不需要关心弹性扩缩的问题等,这些都由FC来处理。
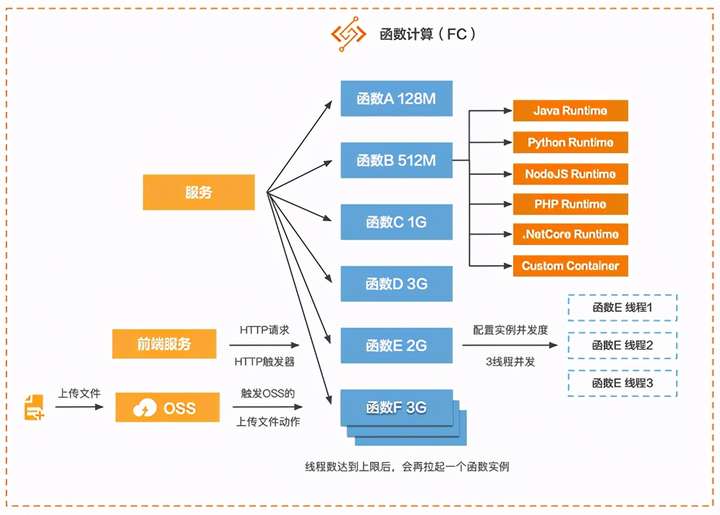
从上图可以看到,高可用有两种策略:
给函数设置并发实例数,假如设置为3,那么有三个请求进来时,该函数只启一个实例,但是会启三个线程来运行逻辑。
线程数达到上限后,会再拉起一个函数实例。
大家看到这里,可能已经大概对基于FC实现在线编程教育系统的架构有了一个大概的轮廓。
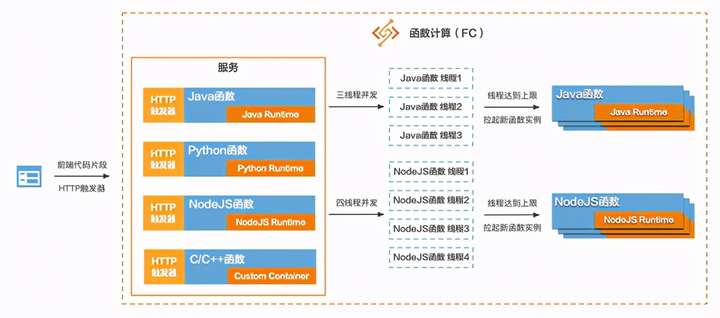
上图是基于FC实现的在线编程教育系统的架构图,在这个架构下来看看上述那三个核心问题怎么解:
工作量和灵活性:我们只需要关注在如何执行代码的业务逻辑上,如果要加新语言,只需要创建一个对应语言Runtime的FC函数即可。高可用:多线程运行业务逻辑和多实例运行业务逻辑两层高可用保障,并且函数实例的扩缩完全都是FC自动处理,不需要研发和运维同学做任何配置。成本优化:当没有请求的时候,函数实例是不会被拉起的,此时也不会计费,所以在流量低谷期或者夜间时,整个FC的成本消耗是非常低的。可以做到函数实例个数、计费粒度和流量完美的贴合。
Python编程语言示例
下面以运行Python代码为例来看看如何用FC实现Python在线编程Demo。
创建服务和函数
打开函数计算(FC)控制台,选择对应的Region,选择左侧服务/函数,然后新建服务:
输出服务名称,创建服务。
进入新创建的服务,然后创建函数,选择HTTP函数,即可配置HTTP触发器的函数:
设置函数的各个参数:
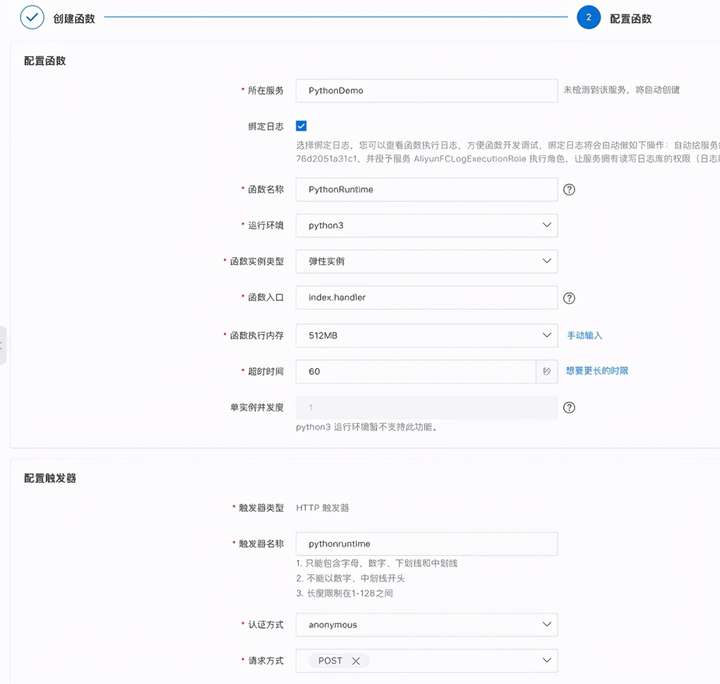
几个需要的注意的参数这里做以说明:
运行环境:这个很好理解,这里选择Python3函数实例类型:这里有弹性实例和性能实例两种,前者最大支持2C3G规格的实例,后者支持更大的规格,最大到8C16G。函数入口:详细参见文档HTTP触发器认证方式:anonymous为不需要鉴权,function是需要鉴权的。
代码解析
函数创建好,进入函数,可以看到概述、代码执行、触发器、日志查询等页签,我们先看触发器,会看到这个函数自动创建了一个HTTP触发器,有调用该函数对应的HTTP路径:

然后我们选择代码执行,直接在线写入我们的代码:
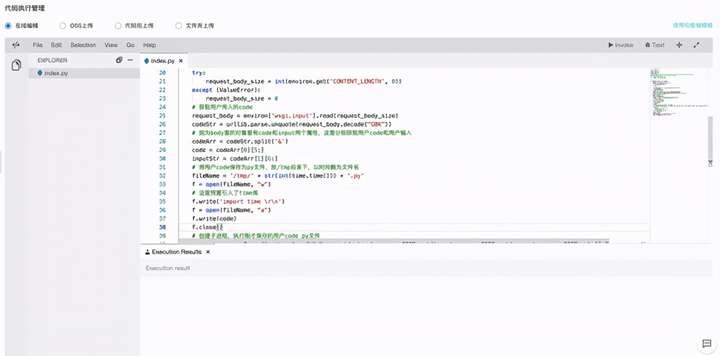
具体代码如下:
-_- coding: utf-8 -_-
import logging
import urllib.parse
import time
import subprocess
def handler(environ, start_response):
context = environ['fc.context']
request_uri = environ['fc.request_uri']
for k, v in environ.items():
if k.startswith('HTTP_'):
pass
try:
request_body_size = int(environ.get('CONTENT_LENGTH', 0))
except (ValueError):
request_body_size = 0
# 获取用户传入的code
request_body = environ['wsgi.input'].read(request_body_size)
codeStr = urllib.parse.unquote(request_body.decode("GBK"))
# 因为body里的对象里有code和input两个属性,这里分别获取用户code和用户输入
codeArr = codeStr.split('&')
code = codeArr[0][5:]
inputStr = codeArr[1][6:]
# 将用户code保存为py文件,放/tmp目录下,以时间戳为文件名
fileName = '/tmp/' + str(int(time.time())) + '.py'
f = open(fileName, "w")
# 这里预置引入了time库
f.write('import time \r\n')
f = open(fileName, "a")
f.write(code)
f.close()
# 创建子进程,执行刚才保存的用户code py文件
p = subprocess.Popen("python " + fileName, stdout=subprocess.PIPE, stdin=subprocess.PIPE, stderr=subprocess.PIPE, shell=True, encoding='utf-8')
# 通过标准输入传入用户的input输入
if inputStr != '' :
p.stdin.write(inputStr + "\n")
p.stdin.flush()
# 通过标准输出获取代码执行结果
r = p.stdout.read()
status = '200 OK'
response_headers = [('Content-type', 'text/plain')]
start_response(status, response_headers)
return [r.encode('UTF-8')]
整个代码思路如下:
从前端传入代码片段,格式是字符串。
- 在FC函数中获取到传入的代码字符串,截取code内容和input的内容。因为这里简单实现了Python中input交互的能力。
- 将代码保存为一个Python文件,以时间戳为文件名,保存在FC函数的/tmp目录下。(每个FC函数都有独立的/tmp目录,可以存放临时文件)
- 然后在文件中追加了引入time库的代码,应对sleep这种交互场景。
- 通过subprocess创建子进程,以Shell的方式通过Python命令执行保存在/tmp目录下的Python文件。如果有用户输入的信息,则通过标准输入输出写入子进程。
- 最后读取执行结果返回给前端。
前端代码
前端我使用VUE写了简单的页面,这里解析两个简单的方法:
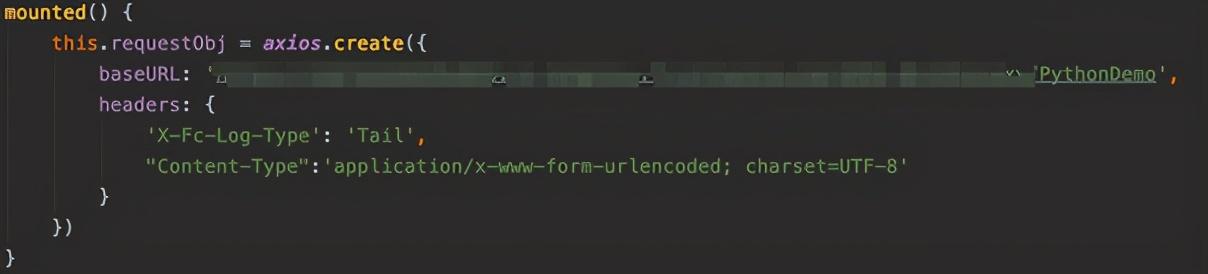
页面加载时初始化HTTP请求对象,调用的HTTP路径就是方才函数的HTTP触发器的路径。
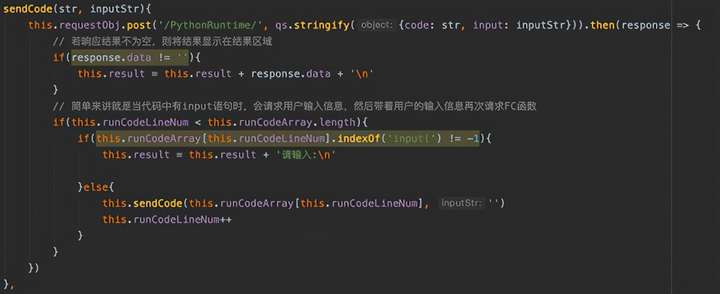
这个方法就是调用FC中的PythonRuntime函数,将前端页面的代码片段传给该函数。这里处理input交互的思路是,扫描整个代码片段,以包含input代码为标识将整个代码段分成多段。没有包含input代码的直接送给FC函数执行,包含input代码的,请求用户的输入,然后代码片段带着用户输入的信息一起送给FC函数执行。

演示如下:
结束语
这篇文章给大家介绍了Serverless,阿里云的Serverless产品函数计算(FC)以及基于函数计算(FC)实现的在线编程系统的Demo。大家应该有所体感,基于函数计算(FC)实现在线编程系统时,研发同学只需要专注在如何执行由前端传入的代码即可,整个Server端的各个环节都不需要研发同学和运维同学去关心,基本体现了Serverless的精髓。
本文为阿里云原创内容,未经允许不得转载。











