
写在前面的话
首先如果你看到了这篇文章,可能你就已经指定 Metabase 是啥了,我这里还是简单的做个说明:
Metabase is the easy, open source way for everyone in your company to ask questions and learn from data。
官网是这样描述的,这是一款 BI 开源工具,能让你的数据以漂亮的图表显示出来,虽然我觉得并不是很好看,但是还是叫漂亮吧。同类的产品还有 Superset,Redash 等等。
感兴趣的可以看看官网:
也可以研究下 GITHUB:
数据迁移
故事是酱婶儿滴,公司准备搞一个这样的系统,然后交给就让我搭建了这几个出来做横向比较。当然,我就是把他运行起来,至于配置都丢给了数据组的老哥。然后这个环境就慢慢的配置越来越多。最后一拍脑门就选它了。于是不可能重新配置啊,这样就得把项目迁移到云上。
问题出现了,因为之前我是以 demo 形式搭建丢给他们的,所有数据库这些啥都是默认是,Metabase 的默认是 H2 数据库。在搞这个之前我根本不知道这是啥。然后网上找了很多导出数据的方式都特么扯皮。各种报错或者根本不能用。
问题出在哪里呢?就处在将数据导出到 MySQL 的时候,报错:Data too long xxxx
既然说到这里,那就先回顾一下我的迁移过程:
【1】首先我们先停止在运行 metabase 服务,我是直接 jar 形式运行的,kill 掉就行。
【2】此时我们可以看到默认运行的时候,在 jar 的目录下存在两个数据库的文件:

上面两个 db 文件就是用到 H2 数据库了,我们把这 3 个文件移动到其他目录备份,相当重要,不然挂了你就哭吧!!!
【3】此时我们新建一个 metabase 的库(我的是 MySQL 5.7):
CREATE DATABASE metabase default charset utf8 COLLATE utf8_general_ci;
grant all on metabase.* to 'metabase'@'%' identified by '123456';
【4】配置好连接数据库的环境变量,由于我们是 jar 启动的,这个服务会默认去先读取环境变量(在 /etc/profile 里面追加):
export MB_DB_TYPE=mysql
export MB_DB_DBNAME=metabase
export MB_DB_PORT=3306
export MB_DB_USER=metabase
export MB_DB_PASS=123456
export MB_DB_HOST=192.168.10.204
export MB_JETTY_PORT=8000
export MB_JETTY_HOST=0.0.0.0
我这里指定了数据库连接,已经服务启动以后监听的 IP 和端口,当然,数据库那一部分可以简写:
export MB_DB_CONNECTION_URI="mysql://192.168.10.204:3306/metabase?user=metabase&password=123456&useSSL=false"
写成 jdbc 的样式,这样我们可以指定 SSL 为 false,否则日志有点恶心。
记得让新增的环境变量生效:
source /etc/profile
【5】生效之后,我们就按照网上的方法开始同步,这也是问题开始的地方:
/opt/jdk1.8.0_45/bin/java -jar metabase.jar load-from-h2 ./metabase.db
我们 jdk 是没有配置环境变量的,所有用的是绝对路径,你们可以根据自己修改。一切就这样往美滋滋的方向发展,MySQL 里面也已经开始创建新的表了。
正当一切过的美滋滋,准备搞完就休息的时候,不幸的事情发生了:
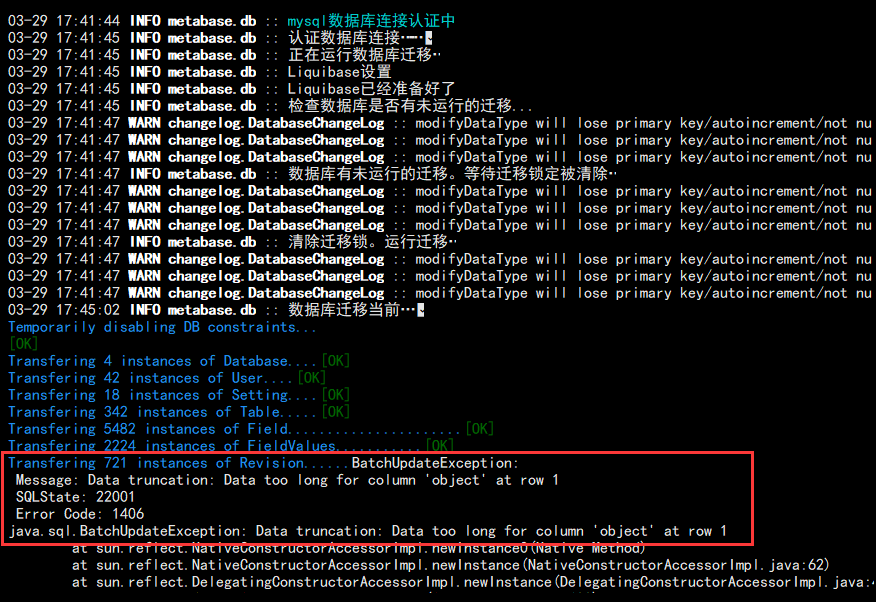
为了方便需要的兄弟更容易检索这篇文章,我这里把错误贴出来:
Transfering 2224 instances of FieldValues...........[OK]
Transfering 721 instances of Revision......BatchUpdateException:
Message: Data truncation: Data too long for column 'object' at row 1
SQLState: 22001
Error Code: 1406
java.sql.BatchUpdateException: Data truncation: Data too long for column 'object' at row 1
提示数据过长,字段长度不够,导致数据传输报异常,传输终止。于是我在这个问题上面卡了至少两个小时,各种搜索文档,找 issue,都没有解决。可能是我英语太烂。
最后还是回归到报错本身,既然长度不够,那我加长度呗,但是我下次同步会不会又把我的表干掉重新建立呢?最终抱着试一试的态度,我去修改表的字段。
问题又来了,那这报错的表是哪一个呢?我们只知道字段啊。给大家推荐一个方法,遇到这种问题,我们完全可以把表结构导出来,然后去搜索指定的列。
最终,在 revision 表中找到了这个字段,此时再看报错:Transfering 721 instances of Revision......BatchUpdateException:,这让我们更加确定就是这个字段。
一看他的类型 text,于是我们将它改成 longtext。
再次执行之前的命令同步,后面还会有几个字段出现类似的报错,类似 report_card 这些表,只需要再度修改为 longtext 类型即可。这里就不再赘述。
【6】同步完成以后只需要启动服务即可使用以 MySQL 作为数据库的 Metabase 了。
这里附带一个我的 jar 服务启动脚本,可以方便我们管理这种单个服务:
#!/bin/bash
#################################################################
# 作者:Dylan <1214966109@qq.com>
# 时间:2018-03-29
# 用途:Metabase 启动管理
#################################################################
if [ -f /etc/init.d/functions ]; then
. /etc/init.d/functions
fi
#################################################################
# 定义变量
#################################################################
SERVICE_NAME='metabase'
SERVICE_PACKAGE="${SERVICE_NAME}.jar"
SERVICE_PATH='/opt/METABASE'
LOG_PATH="${SERVICE_PATH}/logs"
JAVA_CMD='/opt/jdk1.8.0_45/bin/java'
#################################################################
# 判断日志目录
#################################################################
if [[ ! -d ${LOG_PATH} ]]; then
mkdir -p ${LOG_PATH}
fi
#################################################################
# 定义命令
#################################################################
function START_COMMAND()
{
${JAVA_CMD} -Duser.timezone=Asia/Shanghai -Xms4g -Xmx4g -jar ${SERVICE_PATH}/${SERVICE_PACKAGE} >> ${LOG_PATH}/${SERVICE_NAME}.log &
if [[ $? -eq 0 ]]; then
action "${SERVICE_NAME} start successed" /bin/true
else
action "${SERVICE_NAME} start failed" /bin/false
fi
}
function STOP_COMMAND()
{
SERVICE_PID=`ps -ef | grep "${SERVICE_PACKAGE}" | grep -v 'grep' | awk '{print $2}'`
if [[ ${SERVICE_PID} == '' ]]; then
action "${SERVICE_NAME} is not running" /bin/false
else
kill -9 ${SERVICE_PID} >/dev/null 2>&1
if [[ $? -eq 0 ]]; then
action "${SERVICE_NAME} stop successed" /bin/true
else
action "${SERVICE_NAME} stop failed" /bin/false
fi
fi
}
function STATUS_COMMAND()
{
SERVICE_PID=`ps -ef | grep "${SERVICE_PACKAGE}" | grep -v 'grep' | awk '{print $2}'`
if [[ ${SERVICE_PID} == '' ]]; then
action "${SERVICE_NAME} is not running" /bin/false
else
action "${SERVICE_NAME} is running" /bin/true
fi
}
#################################################################
# 定义命令
#################################################################
case "$1" in
start)
START_COMMAND
;;
stop)
STOP_COMMAND
;;
restart|reload)
STOP_COMMAND
START_COMMAND
;;
status)
STATUS_COMMAND
;;
*)
echo "Usage: $0 {start|stop|restart|status|reload}"
;;
esac
小结
H2 迁移到 MySQL 出现问题可能大多都是字段的类型导致迁移失败,另外我们在迁移的时候也可能会出现:
java.lang.IllegalArgumentException: No matching clause: :h2
这样的报错,这说明是环境变量的问题。
如果还有其它迁移问题,也可以留言或者加我 QQ 大家讨论一下,如果你觉得这个还 OK,推荐 走一波~
另外,如果你喜欢我这博客园主题,在我博客首页置顶文章有相关说明~










