
点击上方蓝色字体,选择“设为星标”
回复”资源“获取更多资源


点击右侧关注,大数据开发领域最强公众号!


大数据真好玩
点击右侧关注,大数据真好玩!

Flink作为新一代的大数据处理引擎,其批流一体化的设计与出色的流处理性能,在业界得到了很多头部公司的青睐。目前运行Flink的集群多采用Yarn进行资源管理,这是最成熟的方案。Yarn做为Hadoop生态系统中的工具之一,客户端通常需要经过Kerberos认证才能使用Yarn提交或管理任务。那么Flink任务是如何提交到带有Kerberos认证的Yarn集群的呢?我们先从Kerberos的原理开始说起,再说如何让Flink在带有Kerberos认证的Yarn集群上跑起来,知其然知其所以然。
为什么需要Kerberos
在Hadoop1.0.0或者CDH3以前,Hadoop集群中的所有节点几乎就是裸奔的,主要存在以下安全问题:
NameNode与JobTracker上没有用户认证,用户可以伪装成管理员入侵到一个HDFS 或者MapReduce集群上。
DataNode上没有认证:Datanode对读入输出并没有认证,如果知道block的ID,就可以任意的访问DataNode上block的数据
JobTracker上没有认证:可以任意的杀死或更改用户的jobs,也可以更改JobTracker的工作状态
没有对DataNode与TaskTracker的认证:用户可以伪装成DataNode与TaskTracker,去接受JobTracker与Namenode的任务指派。
为了解决这些问题,kerberos认证出现了,它实现的是机器级别的安全认证。

kerberos是希腊神话中的三头狗,地狱之门的守护者
其原理是事先将集群中的机器添加到kerberos数据库中,在数据库中分别产生主机与各个节点的keytab,并将这些keytab分发到对应的节点上。通过这些keytab文件,节点可以从数据库中获得与目标节点通信的密钥防止身份被冒充。针对Hadoop集群可以解决两方面的认证
解决服务器到服务器的认证,确保不会冒充服务器的情况。集群中的机器都是是可靠的,有效防止了用户伪装成Datanode,Tasktracker,去接受JobTracker,Namenode的任务指派。
解决client到服务器的认证,防止用户恶意冒充client提交作业,也无法发送对于作业的操作到JobTracker上,即使知道datanode的相关信息,也无法读取HDFS上的数据。
对于具体到用户粒度上的权限控制,如哪些用户可以提交某种类型的作业,哪些用户不能,目前Kerberos还没有实现,需要有专门的ACL模块进行把控。
Kerberos认证过程
Kerberos认证过程会涉及以下几个基本概念:
Principal(安全个体):被认证的个体,有一个名字和口令,每个server都对应一个principal,其格式如下,@前面部分为具体身份,后面的部分称为REALM。
component1 / component2 @ REALM
KDC(key distribution center ) : 是一个网络服务,提供ticket 和临时会话密钥。
Ticket:一个记录,客户用它来向服务器证明自己的身份,包括客户标识、会话密钥、时间戳。
AS (Authentication Server):认证服务器,率属于KDC,用于认证Client身份。
TGS(Ticket Granting Server):许可证服务器,率属于KDC。
事先对集群中确定的机器由管理员手动添加到kerberos数据库中,在KDC上分别产生主机与各个节点的keytab(包含了host和对应节点的名字,还有他们之间的密钥——Master Key),并将这些keytab分发到对应的节点上。
1. AS Exchange
通过这个过程,KDC(确切地说是KDC中的Authentication Service)可以实现对Client身份的确认,并颁发给该Client一个TGT。具体过程如下:
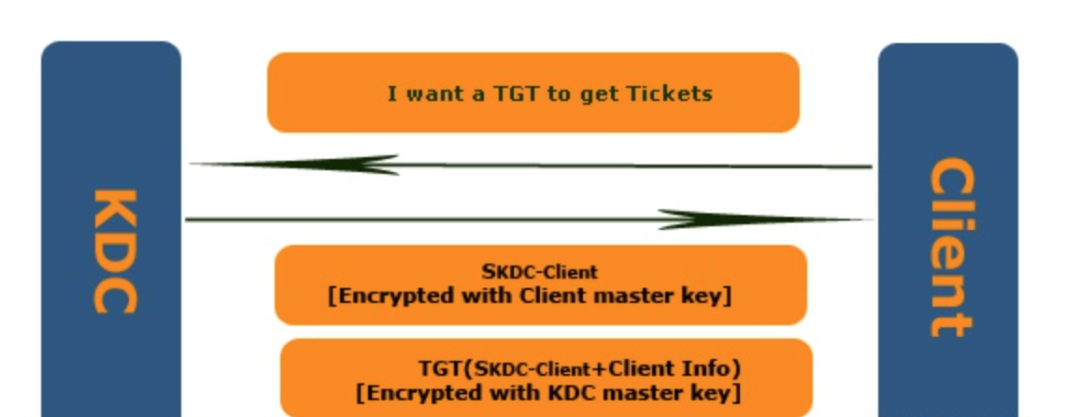
Client向KDC的Authentication Service发送Authentication Service Request(KRB_AS_REQ), 为了确保KRB_AS_REQ仅限于自己和KDC知道,Client使用自己的Master Key对KRB_AS_REQ的内容进行加密。KRB_AS_REQ内容主要包括:
Pre-authentication data:用于证明自己知道自己声称的那个account的Password,一般是一个被Client的Master key加密过的Timestamp。
Client信息: 可以理解为client的principal。
TGS的Server Name。
AS在接收到的KRB_AS_REQ后从Account Database中提取Client对应的Master Key对Pre-authentication data进行解密,如果是一个合法的Timestamp,则可以证明发送方的确是Client信息中声称的那个人。
验证通过之后,AS将一份Authentication Service Response(KRB_AS_REP)发送给请求方。KRB_AS_REQ主要包含两个部分:该Client的Master Key加密过的Session Key(SKDC-Client:Logon Session Key)和被自己(KDC)的Master Key加密的TGT。而TGT大体又包含以下的内容:
Session Key;
Client信息:即Client的principal;
End time: TGT到期的时间。
Client通过自己的Master Key对第一部分解密获得Session Key之后,利用TGT便可以进行Kerberos认证的下一步:TGS Exchange。
2. TGS Exchange
Client先向TGS发送Ticket Granting Service Request(KRB_TGS_REQ),其主要内容为:
被KDC的Master Key加密的TGT;
Authenticator:用于验证确认Client提供的那个TGT是否是AS颁发给它的,其内容为Client信息与Timestamp,并且用Session Key进行加密。
Client信息;
Server信息:Client试图访问的Server的Principal。
TGS收到KRB_TGS_REQ后,先使用他自己的Master Key对TGT进行解密,从而获得Session Key。随后使用该Session Key解密Authenticator,通过比较Authenticator中的Client Info和Session Ticket中的Client Info从而实现对Client的验证。
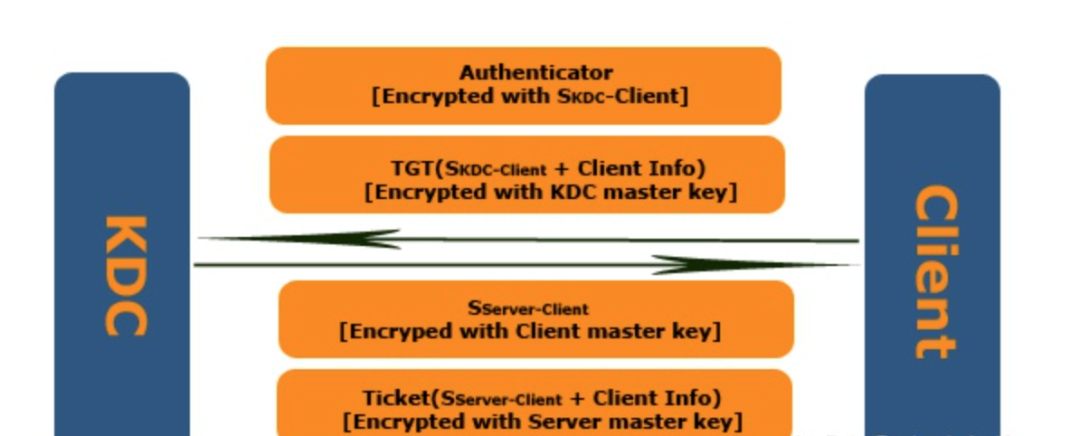
验证通过向对方发送Ticket Granting Service Response(KRB_TGS_REP)。这个KRB_TGS_REP有两部分组成:使用Logon Session Key(SKDC-Client)加密过用于Client和Server认证的Session Key(SServer-Client)和使用Server的Master Key进行加密的Ticket。该Ticket大体包含以下一些内容:
Session Key:SServer-Client;
Client信息;
End time: Ticket的到期时间。
Client收到KRB_TGS_REP,使用Logon Session Key(SKDC-Client)解密第一部分后获得Session Key(SServer-Client)。有了Session Key和Ticket,Client就可以和Server进行交互,这时无须KDC介入了。我们看看 Client是如何使用Ticket与Server怎样进行交互的。
3. CS(Client/Server )Exchange
先是Client向Server认证自己的身份。这个过程与TGS Exchange中认证的过程类似,Client创建用于证明自己就是Ticket的真正所有者的Authenticator,并使用上一步获得的Session Key(SServer-Client)进行加密,然后将它和Ticket一起作为Application Service Request(KRB_AP_REQ)发送给Server。
除了上述两项内容之外,KRB_AP_REQ还包含一个Flag用于表示Client是否需要进行双向验证(Mutual Authentication)。
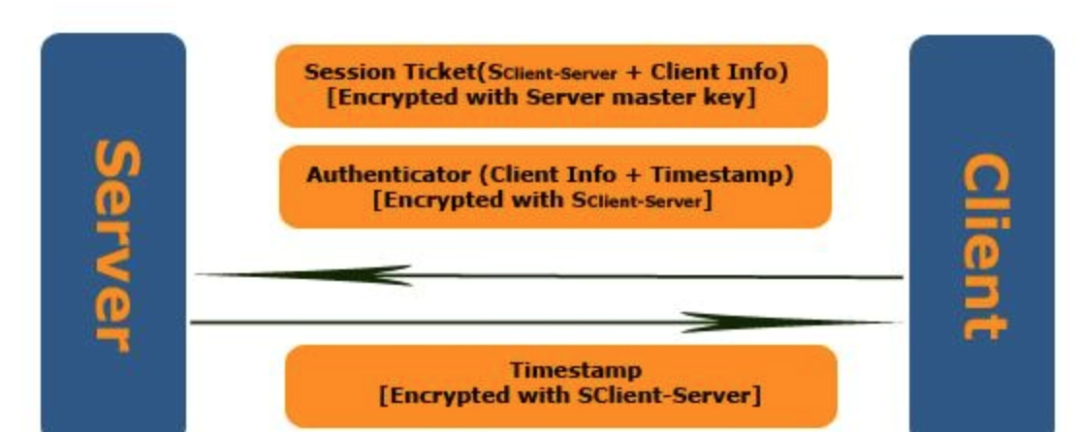
Server接收到KRB_AP_REQ之后,通过自己的Master Key解密Ticket,从而获得Session Key(SServer-Client)。通过Session Key(SServer-Client)解密Authenticator,进而验证对方的身份。验证成功,让Client访问需要访问的资源,否则直接拒绝对方的请求。
对于需要进行双向验证,Server从Authenticator提取Timestamp,使用Session Key(SServer-Client)进行加密,并将其发送给Client用于Client验证Server的身份。
Flink on Kerberos Yarn实现方式
在客户端使用Kerberos认证来获取服务时,需要经过三个步骤:
认证:客户端向认证服务器发送一条报文,并获取一个含时间戳的TGT。
授权:客户端使用TGT向TGS请求一个服务Ticket。
服务请求:客户端向服务器出示服务Ticket,以证实自己的合法性。
其关键在于获取TGT,客户端有了它就可以申请访问服务。所以第一种方式就是使用
1. 使用Delegation token
如果本地安装了Kerberos客户端,可以使用kinit命令来获取TGT,
可以使用密码来向KDC申请
kinit wanghuan70Password for wanghuan70@IDC.XXX-GROUP.NET:
也可以直接使用keytab来获取,keytab文件中包含了密码的散列值;
kinit -kt wanghuan70.keytab wanghuan70
使用klist命令可以查看获取到的tgt的详细信息,包括Client principal、Service principal、位置、有效期等;
$ klistTicket cache: FILE:/tmp/krb5cc_2124Default principal: wanghuan70@IDC.XXX-GROUP.NETValid starting Expires Service principal08/03/2017 09:31:52 08/11/2017 09:31:52 krbtgt/IDC.XXX- GROUP.NET@IDC.XXX-GROUP.NET renew until 08/10/2017 09:31:52
在Flink client上执行这一系列操作后,再在Flink配置文件flink-conf.yaml里面添加如下配置
security.kerberos.login.use-ticket-cache: true
这时Flink客户端就可以像一般情况一样直接用command向Yarn集群提交任务了。但是tgt有一个有效期,通常是一周,过期了就无法使用了,所以这种方式不适合长期任务。这就有了第二种方式——使用keytab,先获取token,后台再启动一个进程定期刷新token。
2. 使用keytab
这种方式时通过客户端将keytab提交到Hadoop集群,再通过YARN分发keytab给AM和其他 worker container,具体步骤如下
Flink客户端在提交任务时,将keytab上传至HDFS,将其作为AM需要本地化的资源。
AM container初始化时NodeManager将keytab拷贝至container的资源目录,然后再AM启动时通过
UserGroupInformation.loginUserFromKeytab()来重新认证。当AM需要申请其他worker container时,也将 HDFS 上的keytab列为需要本地化的资源,因此worker container也可以仿照AM的认证方式进行认证。
此外AM和container都必须额外实现一个线程来定时刷新TGT。
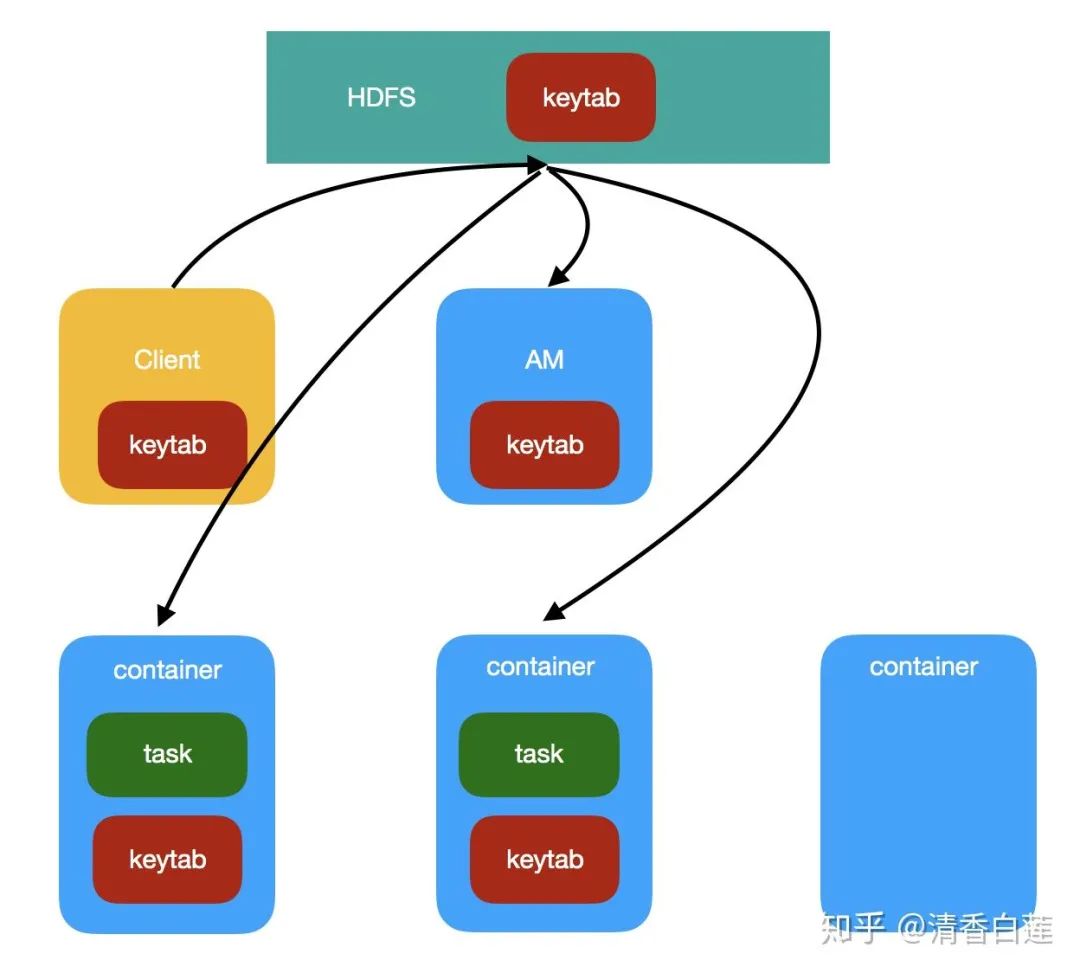
任务运行结束后,集群中的keytab也会随container被清理掉。
使用这种方式的话,Flink客户端需要持有keytab文件,并且在Flink配置文件flink-conf.yaml里面添加如下配置
security.kerberos.login.keytab: /home/hadoop_runner/hadoop-3.2.1/etc/hadoop/krb5.keytabsecurity.kerberos.login.principal: superusersecurity.kerberos.login.contexts: Client
注意:Flink客户端进行Kerberos认证是在加载集群动态配置之前进行的,所以需要在flink-conf.yaml文件中位置principal与keytab。在命令行中添加这个配置参数,实际还是用客户端的用户名作为principal进行认证,会报找不到tgt的错误。
设置Hadoop代理用户
出于于安全考虑,很多时候我们希望客户端能以某一个hadoop用户的身份去运提交任务、访问hdfs文件,目前实现方式主要有以下几种
client端root用户su为joe用户,再使用joe用户的名义提交作业,但这种方法前提是客户端已经有joe的token,并且会造成潜在的权限滥用风险。
设置环境变量或者系统变量HADOOP_USER_NAME,例如希望访问hdfs文件,并在hdfs中进行读写操作,可将用户名设置为hdfs,因为在hdfs文件系统中hdfs具有最高权限。这种方法对于带有Kerberos认证的Hadoop集群并不起作用。
export HADOOP_USER_NAME=hdfs
设置环境变量或者系统变量HADOOP_PROXY_USER,即设置Hadoop代理用户,因为对于带有Kerberos认证的集群,都是通过UserGroupInformation进行认证的,用户名是由getLoginUser方法获取的。
@Public @Evolving public static synchronized UserGroupInformation getLoginUser() throws IOException { if (loginUser == null) { loginUserFromSubject((Subject)null); } return loginUser; } @Public @Evolving public static synchronized void loginUserFromSubject(Subject subject) throws IOException { ensureInitialized(); try { if (subject == null) { subject = new Subject(); } LoginContext login = newLoginContext(authenticationMethod.getLoginAppName(), subject, new UserGroupInformation.HadoopConfiguration()); login.login(); UserGroupInformation realUser = new UserGroupInformation(subject); realUser.setLogin(login); realUser.setAuthenticationMethod(authenticationMethod); realUser = new UserGroupInformation(login.getSubject()); String proxyUser = System.getenv("HADOOP_PROXY_USER"); if (proxyUser == null) { proxyUser = System.getProperty("HADOOP_PROXY_USER"); } loginUser = proxyUser == null ? realUser : createProxyUser(proxyUser, realUser); String fileLocation = System.getenv("HADOOP_TOKEN_FILE_LOCATION"); if (fileLocation != null) { Credentials cred = Credentials.readTokenStorageFile(new File(fileLocation), conf); loginUser.addCredentials(cred); } loginUser.spawnAutoRenewalThreadForUserCreds(); } catch (LoginException var6) { LOG.debug("failure to login", var6); throw new IOException("failure to login", var6); } if (LOG.isDebugEnabled()) { LOG.debug("UGI loginUser:" + loginUser); } }
然而直接在客户端设置这个环境变量或者Java系统变量是不work的,因为实际访问Hadoop的Operator是在TaskManager中运行的,所以需要将这个变量传到运行tm的NodeManager中,可以通过在Flink客户端配置参数env.ssh.opts或者env.java.opts来实现。
env.java.opts: -DHADOOP_PROXY_USER=hdfs # 配置所有Flink进程的JVM启动参数env.ssh.opts: export HADOOP_PROXY_USER=hdfs # 启动jm、tm、zookeeper等服务的额外命令
也可以通过配置containerized.master.env.与containerized.taskmanager.env.来传递环境变量。
然而,在目前版本(Flink 1.10)中,如果配置了keytab文件与Principal,Flink在后续中始终会以该Principal的名义提交任务,即便配置了HADOOP_PROXY_USER也起不到效果。针对这个issue,Uber提出了Flink on Yarn Security的改进方案,其进展详见Flink-11271。


版权声明:
本文为大数据技术与架构整理,原作者独家授权。未经原作者允许转载追究侵权责任。
编辑|冷眼丶
微信公众号|import_bigdata
欢迎点赞+收藏+转发朋友圈素质三连

文章不错?点个【在看】吧!** 👇**
本文分享自微信公众号 - 大数据技术与架构(import_bigdata)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。











