
同步和异步,阻塞和非阻塞
同步和异步
关注的是结果消息的通信机制
同步:同步的意思就是调用方需要主动等待结果的返回
异步:异步的意思就是不需要主动等待结果的返回,而是通过其他手段比如,状态通知,回调函数等。
阻塞和非阻塞
主要关注的是等待结果返回调用方的状态
阻塞:是指结果返回之前,当前线程被挂起,不做任何事
非阻塞:是指结果在返回之前,线程可以做一些其他事,不会被挂起。
两者的组合
1.同步阻塞:同步阻塞基本也是编程中最常见的模型,打个比方你去商店买衣服,你去了之后发现衣服卖完了,那你就在店里面一直等,期间不做任何事(包括看手机),等着商家进货,直到有货为止,这个效率很低。
2.同步非阻塞:同步非阻塞在编程中可以抽象为一个轮询模式,你去了商店之后,发现衣服卖完了,这个时候不需要傻傻的等着,你可以去其他地方比如奶茶店,买杯水,但是你还是需要时不时的去商店问老板新衣服到了吗。
3.异步阻塞:异步阻塞这个编程里面用的较少,有点类似你写了个线程池,submit然后马上future.get(),这样线程其实还是挂起的。有点像你去商店买衣服,这个时候发现衣服没有了,这个时候你就给老板留给电话,说衣服到了就给我打电话,然后你就守着这个电话,一直等着他响什么事也不做。这样感觉的确有点傻,所以这个模式用得比较少。
4.异步非阻塞:异步非阻塞。好比你去商店买衣服,衣服没了,你只需要给老板说这是我的电话,衣服到了就打。然后你就随心所欲的去玩,也不用操心衣服什么时候到,衣服一到,电话一响就可以去买衣服了。
五种I/O模型

阻塞I/O模型:
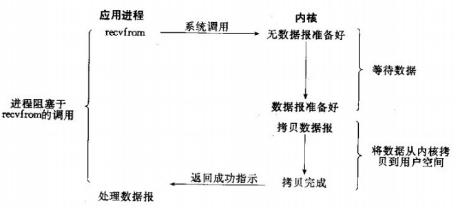
应用程序调用一个IO函数,导致应用程序阻塞,等待数据准备好。 如果数据没有准备好,一直等待….数据准备好了,从内核拷贝到用户空间,IO函数返回成功指示。
当调用recv()函数时,系统首先查是否有准备好的数据。如果数据没有准备好,那么系统就处于等待状态。当数据准备好后,将数据从系统缓冲区复制到用户空间,然后该函数返回。在套接应用程序中,当调用recv()函数时,未必用户空间就已经存在数据,那么此时recv()函数就会处于等待状态。
非阻塞IO模型
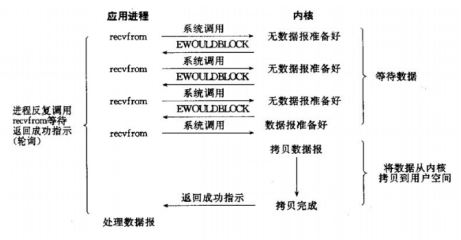
我们把一个SOCKET接口设置为非阻塞就是告诉内核,当所请求的I/O操作无法完成时,不要将进程睡眠,而是返回一个错误。这样我们的I/O操作函数将不断的测试数据是否已经准备好,如果没有准备好,继续测试,直到数据准备好为止。在这个不断测试的过程中,会大量的占用CPU的时间。上述模型绝不被推荐。
IO复用模型:

简介:主要是select和epoll两个系统调用;对一个IO端口,两次调用,两次返回,比阻塞IO并没有什么优越性;关键是能实现同时对多个IO端口进行监听;
I/O复用模型会用到select、poll、epoll函数,这几个函数也会使进程阻塞,但是和阻塞I/O所不同的的,这两个函数可以同时阻塞多个I/O操作。而且可以同时对多个读操作,多个写操作的I/O函数进行检测,直到有数据可读或可写时,才真正调用I/O操作函数。
当用户进程调用了select,那么整个进程会被block;而同时,kernel会“监视”所有select负责的socket;当任何一个socket中的数据准备好了,select就会返回。这个时候,用户进程再调用read操作,将数据从kernel拷贝到用户进程。
这个图和blocking IO的图其实并没有太大的不同,事实上还更差一些。因为这里需要使用两个系统调用(select和recvfrom),而blocking IO只调用了一个系统调用(recvfrom)。但是,用select的优势在于它可以同时处理多个connection。(多说一句:所以,如果处理的连接数不是很高的话,使用select/epoll的web server不一定比使用multi-threading + blocking IO的web server性能更好,可能延迟还更大。select/epoll的优势并不是对于单个连接能处理得更快,而是在于能处理更多的连接。)
信号驱动IO
简介:两次调用,两次返回;

首先我们允许套接口进行信号驱动I/O,并安装一个信号处理函数,进程继续运行并不阻塞。当数据准备好时,进程会收到一个SIGIO信号,可以在信号处理函数中调用I/O操作函数处理数据。
异步IO模型
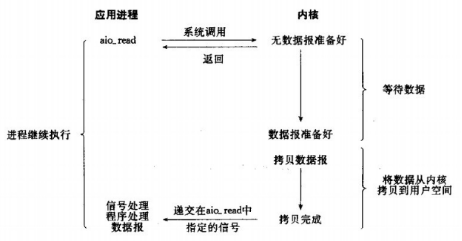
当一个异步过程调用发出后,调用者不能立刻得到结果。实际处理这个调用的部件在完成后,通过状态、通知和回调来通知调用者的输入输出操作
5个I/O模型的比较
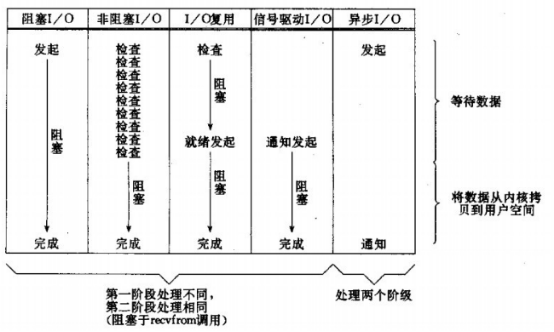
不同I/O模型的区别,其实主要在等待数据和数据复制这两个时间段不同,图形中已经表示得很清楚了。
select、poll、epoll****的区别? :
1、支持一个进程所能打开的最大连接数
select
单个进程所能打开的最大连接数有FD_SETSIZE宏定义,其大小是32个整数的大小(在32位的机器上,大小就是32*32,同理64位机器上FD_SETSIZE为32*64),当然我们可以对进行修改,然后重新编译内核,但是性能可能会受到影响。
poll
poll本质上和select没有区别,但是它没有最大连接数的限制,原因是它是基于链表来存储的
epoll
虽然连接数有上限,但是很大,1G内存的机器上可以打开10万左右的连接,2G内存的机器可以打开20万左右的连接
2、FD剧增后带来的IO效率问题
select
因为每次调用时都会对连接进行线性遍历,所以随着FD的增加会造成遍历速度慢的“线性下降性能问题”。
poll
同上
epoll
因为epoll内核中实现是根据每个fd上的callback函数来实现的,只有活跃的socket才会主动调用callback,所以在活跃socket较少的情况下,使用epoll没有前面两者的线性下降的性能问题,但是所有socket都很活跃的情况下,可能会有性能问题。
3、 消息传递方式
select
内核需要将消息传递到用户空间,都需要内核拷贝动作
poll
同上
epoll
epoll通过内核和用户空间共享一块内存来实现的。
总结:
综上,在选择select,poll,epoll时要根据具体的使用场合以及这三种方式的自身特点。
1、表面上看epoll的性能最好,但是在连接数少并且连接都十分活跃的情况下,select和poll的性能可能比epoll好,毕竟epoll的通知机制需要很多函数回调。
2、select低效是因为每次它都需要轮询。但低效也是相对的,视情况而定,也可通过良好的设计改善
补充知识点:
Level_triggered(水平触发):当被监控的文件描述符上有可读写事件发生时,epoll_wait()会通知处理程序去读写。如果这次没有把数据一次性全部读写完(如读写缓冲区太小),那么下次调用 epoll_wait()时,它还会通知你在上没读写完的文件描述符上继续读写,当然如果你一直不去读写,它会一直通知你!!!如果系统中有大量你不需要读写的就绪文件描述符,而它们每次都会返回,这样会大大降低处理程序检索自己关心的就绪文件描述符的效率!!!
Edge_triggered(边缘触发):当被监控的文件描述符上有可读写事件发生时,epoll_wait()会通知处理程序去读写。如果这次没有把数据全部读写完(如读写缓冲区太小),那么下次调用epoll_wait()时,它不会通知你,也就是它只会通知你一次,直到该文件描述符上出现第二次可读写事件才会通知你!!!这种模式比水平触发效率高,系统不会充斥大量你不关心的就绪文件描述符!!
select(),poll()模型都是水平触发模式,信号驱动IO是边缘触发模式,epoll()模型即支持水平触发,也支持边缘触发,默认是水平触发。











