作者:殳鑫鑫,花名辰石,阿里巴巴计算平台事业部EMR团队技术专家,目前从事大数据存储以及Spark相关方面的工作。
2019 年云栖大会上,EMR Jindo 的技术存储分离方案得到很大的关注,视频直达链接【云上大数据的一种高性能数据湖存储方案】
【EMR打造高效云原生数据分析引擎】
JindoFS背景
计算存储分离是云计算的一种发展趋势,传统的计算存储相互融合的的架构存在一定的问题, 比如在集群扩容的时候存在计算能力和存储能力相互不匹配的问题,用户在某些情况下只需要扩容计算能力或者存储能力,传统的融合架构不能单独的扩充计算或者存储能力, 而计算存储分离可以很好的解决这个问题,用户只需要关心整个集群的计算能力。
基于OSS 计算存储分离
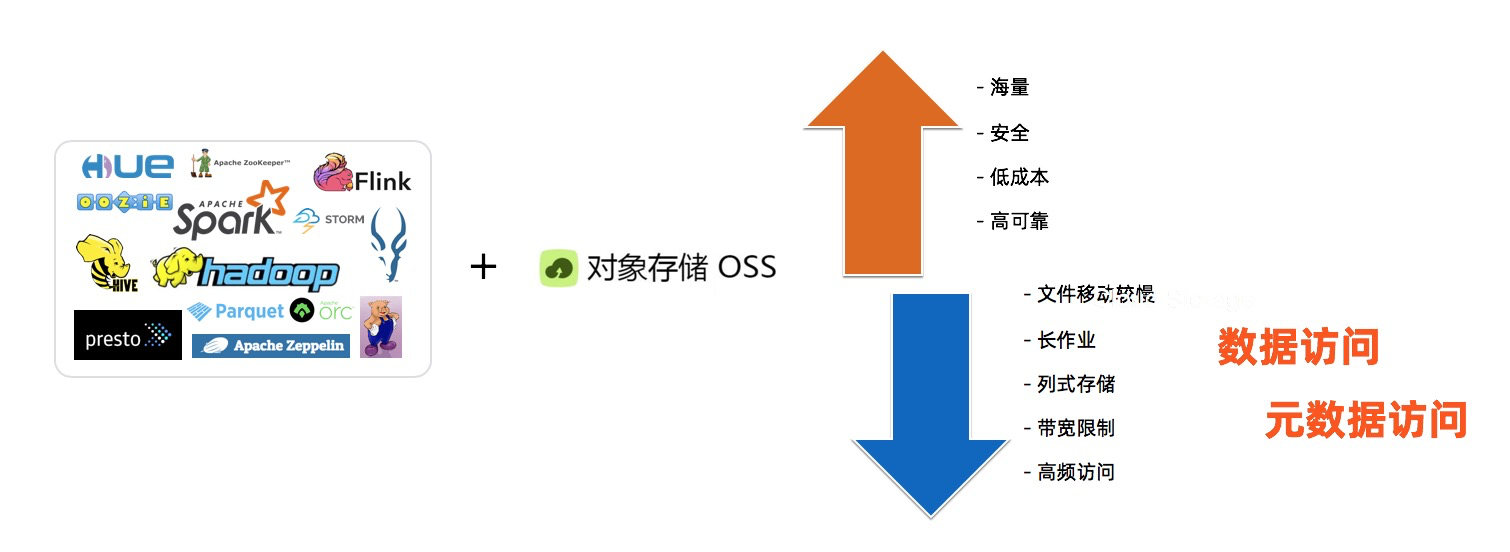
EMR 现有的计算存储分离方案是基于OSS提供兼容Hadoop文件系统的OssFS, 用户通过OssFS 可以访问OSS 上的数据, 因此OssFS 保留了OSS的一些优势,比如提供海量存储,成本低,高可靠等,同时也存在一些问题比如文件重命名操作慢, OSS 带宽限制,高频访问的数据消耗过多的OSS带宽。而JindoFS 除了可以保留上述OssFS的优势,还克服上述OssFS的问题。
JindoFS 介绍
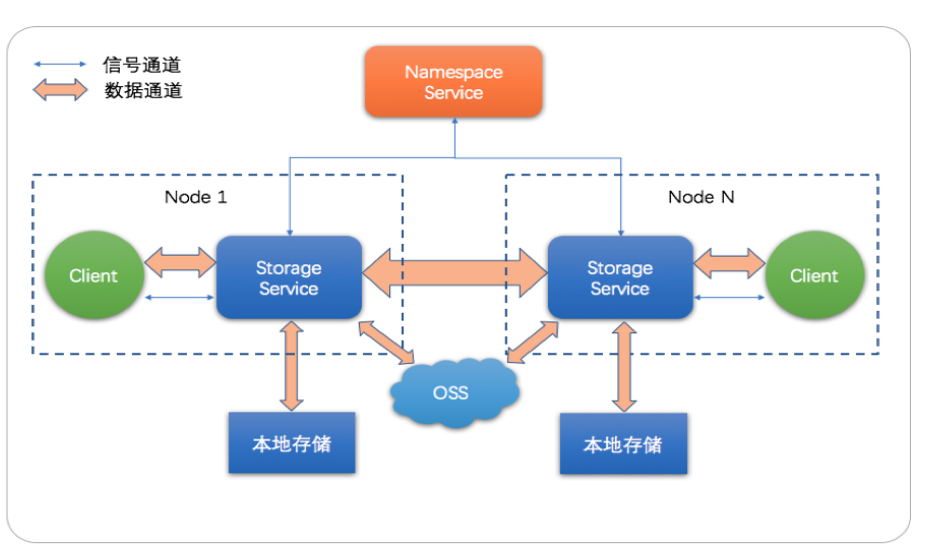
JindoFS 主要包含两个服务组件:Namespace的服务以及Storage 服务,Namespace服务主要JindoFS 元数据管理以及 Storage 服务的管理, Storage 服务主要负责 用户数据的管理包含本地数据的管理和OSS上数据的管理, JindoFS是云原生的文件系统,可以提供本地存储的性能以及OSS的超大容量。下面我们分别介绍下这两个服务的主要功能。
Namespace 主要用来管理用户的元数据,这部分元数据包含JindoFS 文件系统的元数据, Block 的元数据以及 Storage 服务的元数据,JindoFS Namespace服务可以在单个集群上支持不同的Namespace, 用户可以根据不同的业务划分不同的Namespace,不同的Namespace存放不同业务数据。 此外Namespace可以设置不同存储后端现阶段主要支持RocksDB,OTS的支持预计在下个版本发布,针对Namespace的性能我们支持大量的优化,比如支持目录级别的并发控制,元数据的缓存等等。
Storage 服务主要负责实际的数据管理,本地缓存的数据管理以及OSS数据管理,可以支持不同的存储后端以及存储介质,存储后端现阶段主要支持本地文件系统以及OSS, 本地存储系统可以支持HDD/SSD/DCPM等存储介质,用以提供缓存加速,另外Storage 服务针对用户的小文件较多的场景进行优化,避免过多的小文件给本地文件系统带来过大的压力造成整体性能的下降。
此外在整个生态方面,JindoFS 支持EMR 框架的所有计算引擎,包括Hadoop, Hive, Spark, Flink, Impala, Presto 以及 HBase, 用户只要替换文件访问路径的模式为jfs就可以使用JindoFS,另外在机器学习方面下个版本JindoFS将会推出Python SDK, 方便机器学习用户可以高效率的访问JindoFS上的数据,另外JindoFS 与 EMR Spark高度集成优化,支持基于Spark的物化视图以及Cube的优化,实现秒级Adhoc的分析
JindoFS 使用模式
JindoFS Block模式
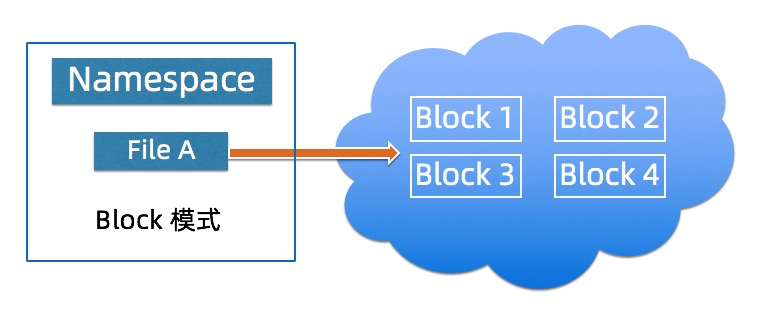
Block模式将JindoFS的文件切分的Block的形式存放本地磁盘以及OSS上,用户通过OSS 只能看到Block的数据,本地的Namespace服务负责管理元数据,通过本地元数据以及Block数据构建出文件数据,该模式相对与后一种模式该模式下JindoFS的性能是最佳的, Block模式适用用户对数据以及元数据都有一定的性能要求的场景,Block模式需要用户将数据迁移到JindoFS。
Block模式为用户提供不同的存储策略适配用户不同的应用场景
策略名称
策略描述
适用场景
COLD
数据只有一份存放在OSS上
主要适用冷数据存储的场景
WARM
默认策略,数据本地一份,OSS一份
本地数据提供性能加速
HOT
数据本地多份,OSS一份
针对热数据提供进一步加速功能
TEMP
数据仅有本地一个备份
针对一些零时数据存储场景
对比HDFS, JindoFS的Block 模式提供以下优势:
- 利用OSS 的廉价和无限容量 JindoFS 提可以 OSS 优势成本以及容量的优势
- 冷热数据自动分离,计算透明,冷热数据自动迁移的时候逻辑位置不变,无须修改表元数据 location 信息
- 维护简单,无须 decommission,节点坏掉或者下掉就去掉,数据 OSS 上有,不会丢失
- 系统快速升级/重启/恢复,没有 block report
- 原生支持小文件,避免小文件过程造成文件系统过大的压力
JindoFS Cache模式
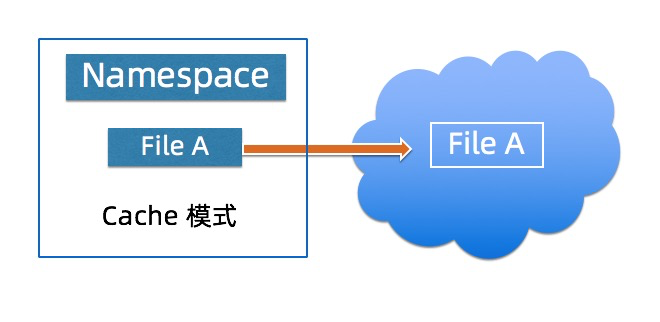
Cache模式将JindoFS文件以对象的形式存在OSS,用户可以通过OSS 看到原有的目录结构以及文件,该模式提供数据以及元数据的缓存加速用户的读写数据的性能,该模式下用户无需迁移数据到OSS,但是性能相对Block模式有一定的性能损失。 在元数据同步方面用户可以根据不同的需求选择不同的元数据同步策略。
对比OssFS, JindoFS的Cache模式提供以下优势:
- 由于本地备份存在,读写吞吐与HDFS相当
- 能够支持全部 HDFS 接口, 支持更多的场景,如Delta Lake,支持 HBase on JindoFS
- JindoFS作为数据以及元数据的缓存, 用户在读写数据以及List/Status操作相对OssFS有性能提升
- JindoFS作为数据缓存, 可以加速用户的数据读写
JindoFS 外部客户端
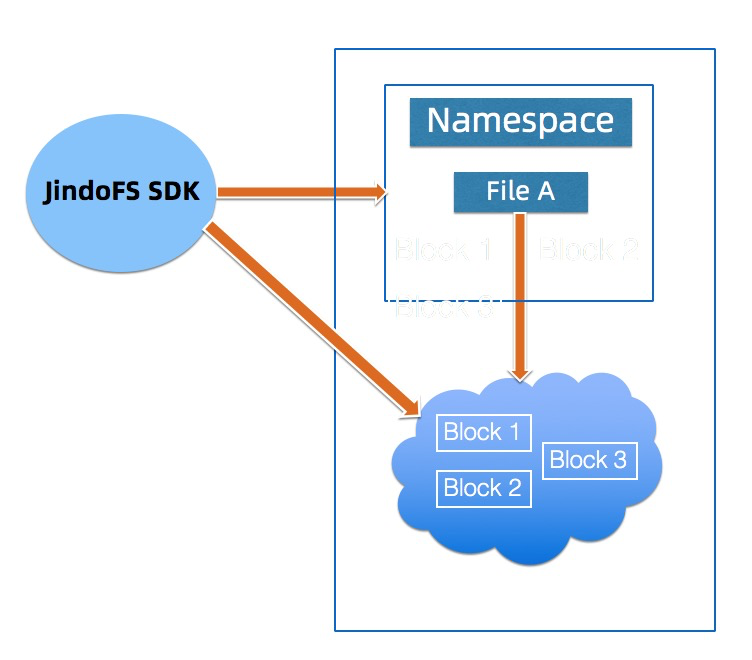
外部客户端提供用户在EMR 集群外访问 JindoFS的一种方式,现阶段该客户端只支持JindoFS的Block模式,客户端的权限与OSS 权限绑定,用户需要有相应OSS的权限才能够通过外部客户端访问JindoFS的数据。
JindoFS + DCPM 性能
测试环境

性能
下面主要JindoFS + DCPM的性能,测试主要分为三部分:Micro-benchmark, TPC-DS查询在JindoFS上的性能以及 SSB在Spark Relational Cache + JindoFS 上的性能。 其中DCPM 为Intel 傲腾数据中心级可持久化内存。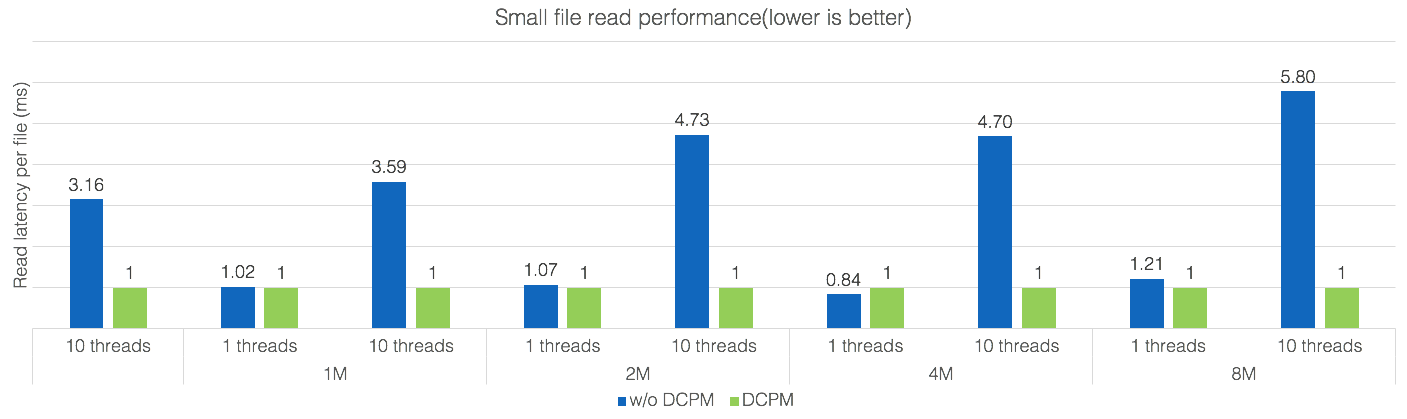
上图为Micro-benchmark的性能,主要测试了不同文件大小( 512K, 1M, 2M, 4M and 8M )和不同并行度(1-10)下的100个小文件读操作,从图中可以看出DCPM为小文件读带来了性能的显著提高,文件越大,并行度越高,性能提升的也更明显。
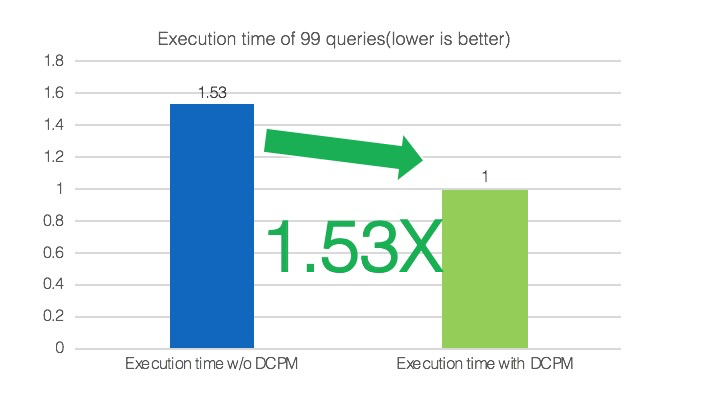
上图TPC-DS的测试结果,TPC-DS数据量为2TB,测试整个TPC-DS的99个查询。基于归一化时间,DCPM总体上带来了1.53倍的性能提升。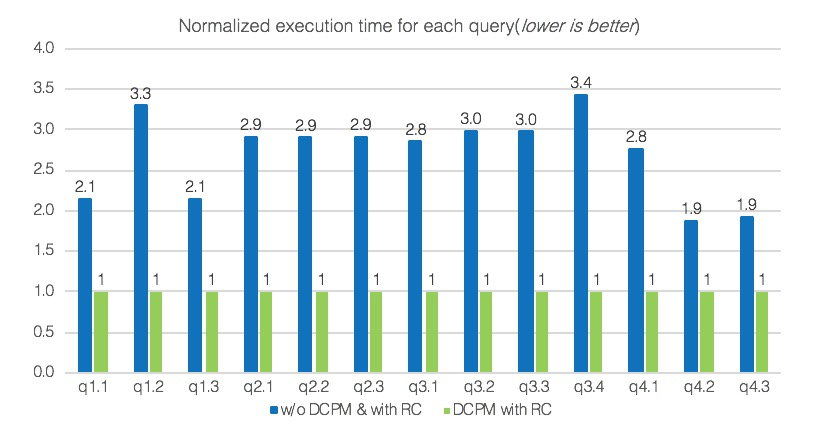
上图SSB在Spark Relational Cache + JindoFS 测试结果,其中SSB( 星型基准测试 )是基于TPC-H的针对星型数据库系统性能的测试基准。Relational Cache是EMR Spark支持的一个重要特性,主要通过对数据进行预组织和预计算加速数据分析,提供了类似传统数据仓库物化视图的功能。 在SSB测试中,使用1TB数据来单独执行每个查询,并在每个查询之间清除系统cache。基于归一化时间,总体上DCPM 能带来2.7倍的性能提升。对于单个query,性能提升在1.9倍至3.4倍。
相关文章推荐:【JindoFS概述:云原生的大数据计算存储分离方案】
本文为云栖社区原创内容,未经允许不得转载。