你会误认为 ElasticJob 只是作业管控平台么?创始人为你解读产品定位与新版本设计理念
——写于 ElasticJob 3.x 版本发布前夕
作者
张亮,京东数科数据研发负责人,Apache ShardingSphere 创始人 & 项目 VP、ElasticJob 创始人。
热爱开源,主导开源项目 ShardingSphere (原名 Sharding-JDBC) 和 ElasticJob。擅长以 Java 为主分布式架构,推崇优雅代码,对如何写出具有展现力的代码有较多研究。
目前主要精力投入在将 Apache ShardingSphere 打造为业界一流的金融级数据解决方案之上。Apache ShardingSphere 是 Apache 软件基金会旗下的顶级项目,也是 Apache 软件基金会首个分布式数据库中间件。
调度(Scheduling)在计算机领域是个非常庞大的概念,CPU 调度、内存调度、进程调度等都可以称之为调度。它是指在特定的时机分配合理的资源去处理预先确定的任务,用于在适当的时机触发一个包含业务逻辑的应用。
调度无论在单机还是分布式环境中都是很重要的课题。在单机环境,调度与底层操作系统脱离不了干系;而在分布式环境中,调度直接决定运行集群的投入和产出。调度的两个核心要素是资源治理和触发时机。
ElasticJob 是一个分布式调度解决方案,由两个相互独立的子项目 ElasticJob Lite 和 ElasticJob Cloud 组成。ElasticJob Lite 定位为轻量级无中心化解决方案,使用 jar 的形式提供分布式任务的协调服务;ElasticJob Cloud 采用自研 Mesos Framework 的解决方案,额外提供资源治理、应用分发以及进程隔离等功能。
本文将介绍 ElasticJob 的产品定位、3.x 设计理念、未来规划以及社区重启的背后故事。
产品定位:面向互联网生态和海量任务
ElasticJob 自 2015 年开源,可谓几经沉浮。从开源之初的备受关注,到近年的更新停滞,期间随关注的增加,每个开发者心目中都有对它的理解和定位。
然而,误解也随社区停滞产生,其中最大的误解便是认为 ElasticJob 是定时任务管控平台。诚然,任务管控是 ElasticJob 的一个产品目标,但并非全部。从设计者的角度看,任务管控仅为其中的一个目标。
ElasticJob 的定位是面向互联网生态的海量任务的分布式调度解决方案。短短一句话浓缩了 ElasticJob 的大量信息,且容笔者娓娓道来。
- 面向互联网生态
ElasticJob 是面向业务应用的开发框架,它面向的不仅是简单的系统作业或数据处理作业,而是能够结合业务应用的复杂任务。
- 海量任务
ElasticJob 能够同时调度 10w 级别的并发任务,日调度次数可达数千万乃至上亿。
- 分布式调度
ElasticJob 是为分布式而生的产品,可以与云原生、弹性调度、横向扩展等相结合,用户可通过简单的服务器数量增减来提升或降低系统整体的吞吐量。
- 解决方案
ElasticJob 并非仅是 Java 开发框架,也并非简单的调度管控平台,其内容涵盖了 Java 开发框架、调度管控平台、资源管控等很多维度组合,是一整套解决方案。
通过上文解释,相信读者已对 ElasticJob 有些许不同认知,下面再从功能角度详细阐述一下它的产品定位。
- 弹性调度
这是 ElasticJob 最重要的功能,也是这款产品名称的由来。ElasticJob 是一款能够让任务通过分片进行水平扩展的任务处理系统。
ElasticJob 中的任务分片项的概念,使得任务可以在分布式的环境下运行,每台任务服务器只运行分配给自己的分片。随着服务器的增加或宕机,ElasticJob 会近乎实时的感知服务器数量的变更,从而重新为分布式的任务服务器分配更加合理的任务分片项,使得任务可以随着资源的增加而提升效率。
典型的使用场景是数据迁移。如果将百亿的数据从一组数据库集群迁移至另一组数据库集群,单线程的作业可能需要几天到几周不等。通过 ElasticJob 的弹性分片能力,可以大幅减少海量数据迁移所需要的时间。
- 资源分配
在导读中提到过,调度是指在适合的时间将适合的资源分配给任务,并使其生效。ElasticJob 具备资源分配的能力,它能够像分布式的操作系统一样调度任务。资源分配是借由 Mesos 实现的,由 Mesos 负责分配任务声明的所需资源(CPU 和内存),并将分配出去的资源进行隔离。ElasticJob 在获取到资源之后才会执行任务。
考虑到 Mesos 系统部署相对复杂,因此 ElasticJob 将这部分拆分至 ElasticJob cloud 部分,供高级用户使用。随着 Kubernetes 的强劲发展,ElasticJob 未来也会完成 cloud 部分与它的对接。
典型的使用场景是占用大量计算资源的报表作业。如果每天凌晨需要花费数小时计算 T+1 的业务报表,没有资源的管控,则无论报表作业是否启动,都要为其分配足够的资源。ElasticJob 将作业分为常驻作业和瞬时作业,对于报表类作业,瞬时作业是非常适合的。它能否在作业启动时获取资源,在作业结束后归还资源,做到真正的削峰填谷,更加合理的利用资源。
- 作业治理
作业治理主要包含3方面:可视化管理端、分布式治理和作业依赖。
可视化管理端,主要包括作业的增删改查管控端、执行历史记录查询、配置中心的管理等。
分布式治理包括作业的高可用、失效转移、错过作业重新执行等能力。
作业依赖指基于有向无环图(DAG)对作业的调度关系进行梳理。目前的 ElasticJob 还不具备此方面的功能,将于3.1.0 版本开启开发。
- 作业生态
ElasticJob 提供灵活的作业 API,它将作业解耦为作业接口和执行器接口。用户可以定制化全新的作业类型,诸如脚本执行、HTTP 服务执行、大数据类作业、文件类作业等。目前 ElasticJob 内置了脚本执行作业,并且完全开放了扩展接口,开发者可以通过 SPI 的方式引入新的作业类型,并且可以便捷地回馈至社区。
ElasticJob 的作业还能够透明化地与业务应用整合,方便与 Spring 框架配合使用。在作业中可自由使用 Spring 注入的 Bean,如数据源连接池、Dubbo 远程服务等,更方便贴合业务开发。
典型的使用场景是订单拉取作业。订单系统大多采用消息中间件或作业的方式实现订单拉取,用于将订单生成系统和后端履约系统解耦,以便前后端流量分离。采用作业实现的订单系统,可以通过 ElasticJob 实现订单相关业务逻辑,方便利用外围系统所提供的依赖注入服务,无缝融入业务端研发。
最大创新是弹性调度,未来将完全分离调度和执行
相比于业界的其他调度项目,ElasticJob 最大的优势是多样化和灵活的可扩展体系,最大的创新是弹性调度。
多样化是指 ElasticJob 同时支持进程内调度和进程级别的调度,ElasticJob Lite 是去中心化调度,ElasticJob Cloud 是集资源管控为一体的中心化调度,可以适合不同用户的不同场景。
灵活的可扩展体系主要体现在作业类型的定制化扩展。用户可以通过 ElasticJob 提供的 SPI 接口扩展自己的作业类型,而无需修改 ElasticJob 的源码。ElasticJob 可将这些高度抽象的作业类型吸纳入社区,形成丰富的作业库。
弹性调度的创新,是 ElasticJob 最大的亮点。在2015年刚开源时,基于分片的弹性调度少之又少,现有调度项目的分片和弹性调度,都或多或少参考了 ElasticJob 的设计与实现。
未来,ElasticJob 将大刀阔斧的向前迈进,主要的规划如下:
- 作业依赖
支持基于有向无环图(DAG)的作业依赖。依赖包含基于作业整体维度的依赖,以及基于作业分片项的依赖,打造更加灵活的作业治理解决方案。
- 调度执行分离
将调度器和执行器完全分离。调度器可以与执行器一起部署,即为 ElasticJob lite 的无中心化轻量级版本;调度器可以与执行器分离部署,即为 ElasticJob cloud 的资源管控的一站式分布式调度系统。
- 更加易用的云管产品
将目前仅支持 Mesos 的 ElasticJob cloud 打造为支持 Mesos 和 Kubernetes 的作业云管平台,并提供无 Mesos 和 Kubernetes 也能够独立使用的不包含资源管控的纯作业管控平台。
- 可插拔生态
与 Apache ShardingSphere 一脉相承,ElasticJob 也将提供更加可插拔和模块化架构,为开发者提供基础设施。方便开发者基于 ElasticJob 二次开发,添加各种定制化功能,包括但不限于作业类型(如:大数据作业、HTTP作业等)、注册中心类型(如:Eureka等)、执行轨迹存储介质(如其他数据库类型)等。
ElasticJob 最终会将 Lite 和 Cloud 以更贴近的方式供开发工程师和运维工程师使用,共享其调度、执行和作业库。整体规划如下:

近期发布3.0.0,作为回馈社区的快速版本
经过了一个多月的开发,ElasticJob 社区近期计划发布3.0.0-alpha,以作为它进入 Apache 软件基金会的第一个发布版本。它的主要功能包括:
- 作业生态圈初现
灵活定制化作业是3.x 版本的最重要设计变革。新版本基于 Apache ShardingSphere 可插拔架构的设计理念,打造了全新作业 API。意在使开发者能够更加便捷且以相互隔离的方式拓展作业类型,打造 ElasticJob 作业生态圈。
- 多元化调度器
在保留原有的基于 cron 的时间触发调度器的基础上,增加了一次性的调度 API,为 ElasticJob 增加了时间维度之外的全新调度维度。
- 微内核 & 生态分离
抽象作业内核模块,将作业执行轨迹追踪等辅助功能以及作业生态等可扩展模块从内核模块完全抽离。作业执行轨迹追踪模块作为二级生态,修改了之前只支持 MySQL 作为存储介质的限制,完全开放持久化的适配。
3.0.0的版本作为一个快速给社区回馈的版本,并未进行颠覆性的革新,而是尝试将项目内核一点一滴的解耦。
重启运营,复刻 ShardingSphere 经验到 ElasticJob
作为 ElasticJob 的作者,我为 ElasticJob 社区停滞的这段时间致歉。
在 ElasticJob 社区停滞的这段时间内,Apache ShardingSphere 的开发及 Apache 社区的孵化,占据了我的大部分时间精力。在接近3年的时间里,ShardingSphere 从 Sharding-JDBC 改名,其模块由个位数不断增加,至今已接近破百,巨大的工作量不言而喻。
与此同时,我也获得了运营 Apache 一线社区的经验。因此在今年4月,Apache ShardingSphere 正式于 Apache 基金会毕业成为顶级项目时,我便萌生了将 Apache 社区的运营经验复刻至 ElasticJob 社区的想法。Apache 社区运营相关情况可查看文章:《80% 的代码曾由一人提交, Apache ShardingSphere 何以从 ASF 毕业并晋升 TLP 》
同时,Apache ShardingSphere 的弹性迁移模块需要一个强大及稳定的分布式调度框架,ElasticJob 是目前唯一的能够进程内调度以及轻量级 SDK 的方式融入 Apache ShardingSphere 的解决方案。因此,我决定将 ElasticJob 捐赠入 Apache 软件基金会,成为 Apache ShardingSphere 的子项目。这使得 ElasticJob 避免了 Apache 孵化器的流程,可以直接以 Apache 社区的运作方式前进。
此外,Apache ShardingSphere 所使用的弹性迁移,将是 ElasticJob 至今为止面对的最复杂场景之一,它在分布式、自动化、弹性伸缩、面向的数据量、作业状态管控等方面均是前所未有的挑战。相信 Apache ShardingSphere 对 ElasticJob 的应用将推进 ElasticJob 的进一步升级革新。
Apache ShardingSphere 弹性迁移的应用场景之外,ElasticJob 在接近5年的开源时间中,也积累了大量应用案例,点此查看。目前官方收录了 70 家采用公司的名称,而实际采用公司远远多于这个数量。欢迎已经使用 ElasticJob 的公司在 GitHub 上联系我们,我们会将您的公司登记在官方的采用列表。
目前 ElasticJob 使用场景涵盖业务作业、监控作业、系统作业、大数据作业等各个维度,并且衍生出了诸如 Saturn 这样的优秀 fork 作品。
接下来,ElasticJob 社区的目标是成为和 Apache ShardingSphere 一样的 Apache 软件基金会的顶级项目,达成更广泛的应用。
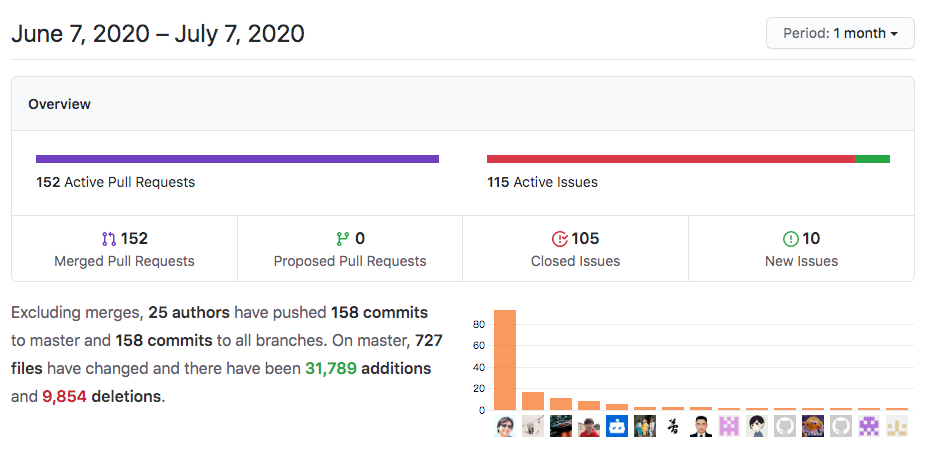
项目重启的这段时间,ElasticJob 持续在 GitHub 的周和月度排行榜上有名。


最近一个月,ElasticJob 社区合并了 152 个 Pull Requests,关闭了 105 个 Issues;25个提交者总共 158 次提交,完成了4w+ 行代码的改动。
基石已经搭建完成,欢迎开源爱好者加入 ElasticJob 社区的建设。GitHub 地址:https://github.com/apache/shardingsphere-elasticjob-lite