
击上方“ Python爬虫与数据挖掘 ”,进行关注
回复“书籍”即可获赠Python从入门到进阶共10本电子书
今
日
鸡
汤
衣裳已施行看尽,针线犹存未忍开。
最近偶然看到了腾讯的大数据星云图,非常漂亮,如下图:
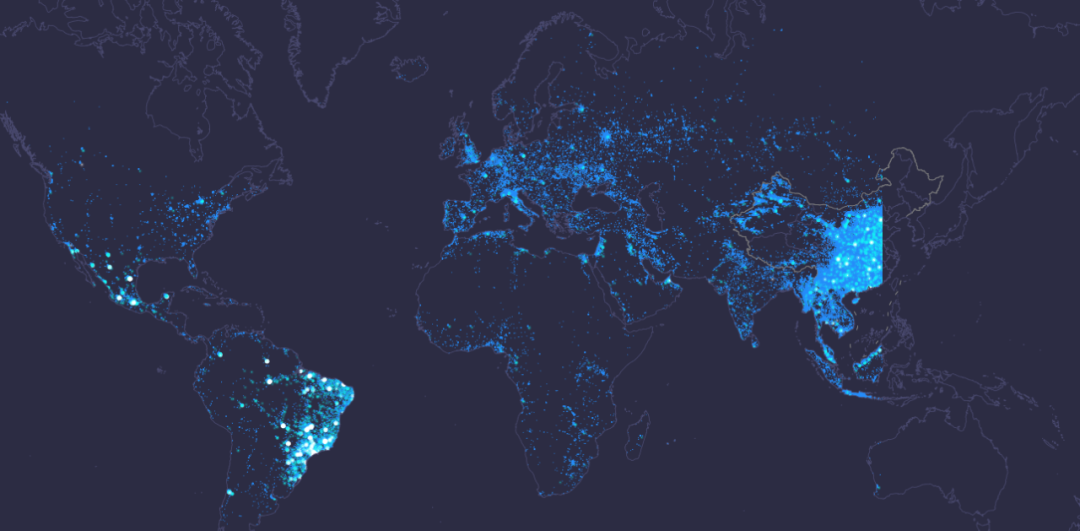
这些数据代表使用腾讯定位服务的用户实际地理位置,例如微信、QQ、腾讯地图等,所以使用量还是表达的,此图可以间接显示人流量情况
该网站还可以查看区域热力图:
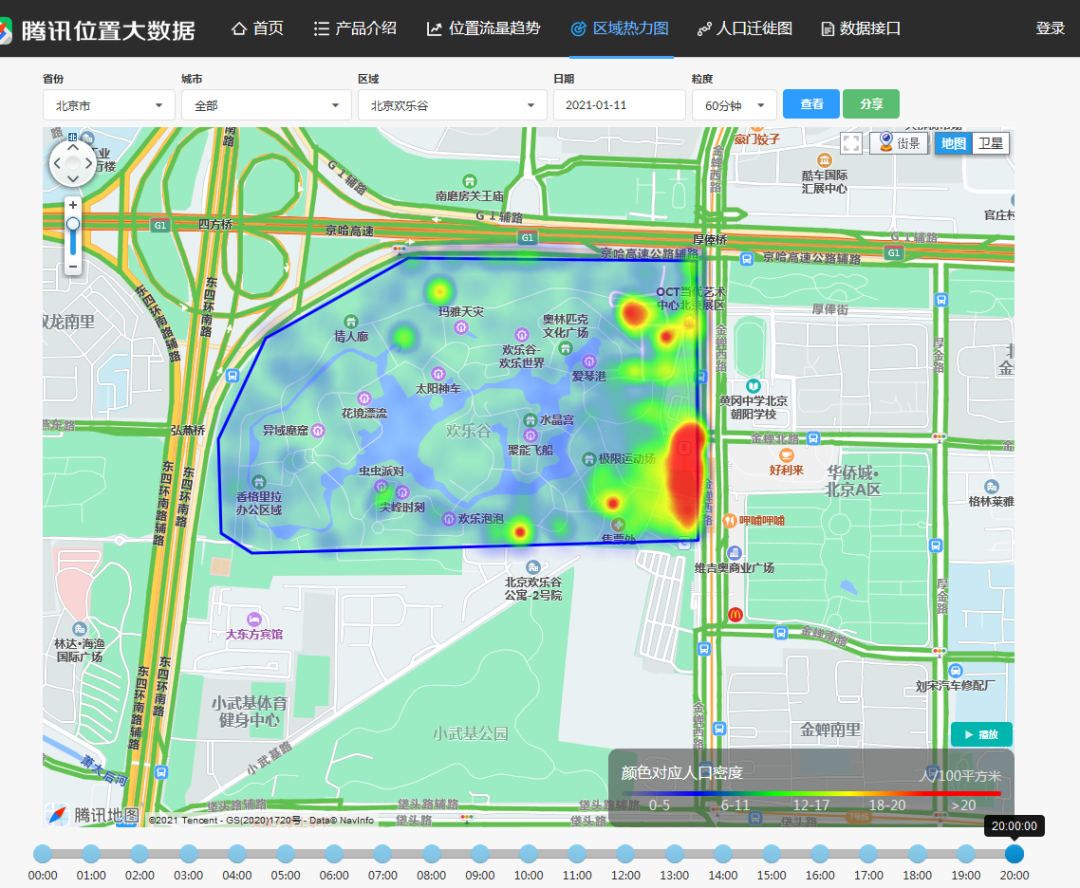
但是只有个别区域
于是我萌生一个想法,用python任意区域人员流量图
经过不懈努力,没想到还真给实现了,下面带大家一起学习一下这一过程:
一、首先是数据获取数据获取
腾讯其实开放了数据接口,但是只能商用:
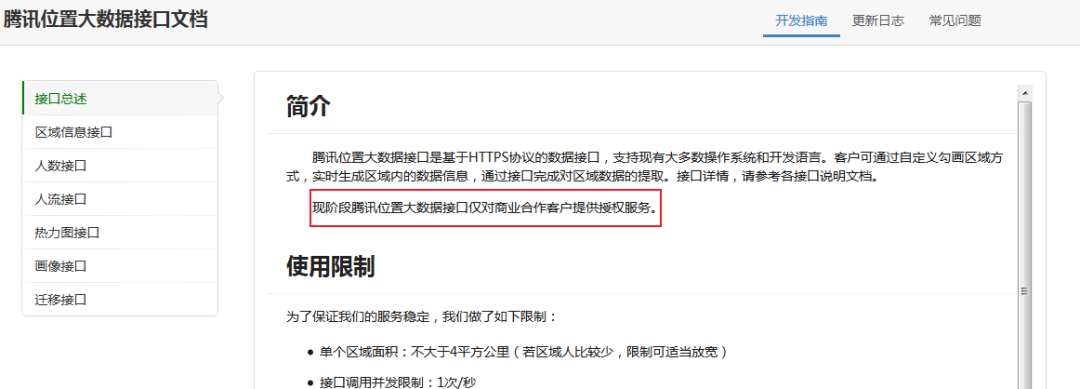
但是不用怕,我们还有其他办法获取
进入主页:https://xingyun.map.qq.com/
在主页抓包,获得数据接口:

经过分析发现,每次请求都会发送4个post请求,每次请求的参数如下:

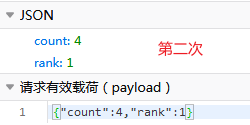
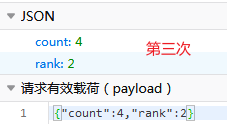

rank值从1变化到4,咱也不知道是啥意思,索性就都爬了,大不了再去重
返回数据如下:
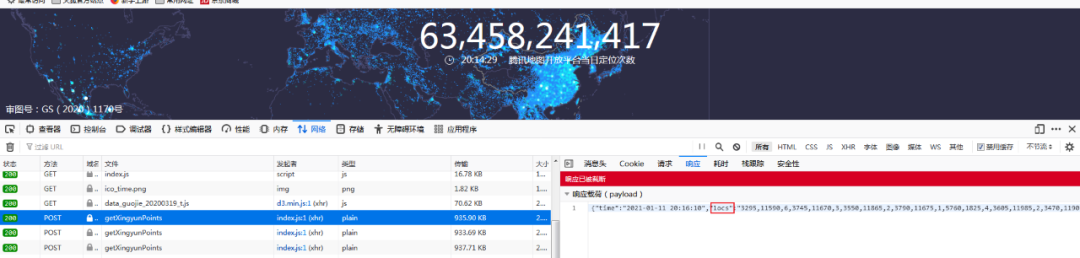
主要是locs字段,以第一组数据为例,3295代表纬度信息,11590代表经度信息,分别除100既是经纬度原始值,6代表该位置人数。
下面我们开始写写代码获取数据:
import requests import json header={ 'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:82.0) Gecko/20100101 Firefox/82.0'} url = 'https://xingyun.map.qq.com/api/getXingyunPoints' for i in range(1,5): payload = {'count': i, 'rank': 0} response = requests.post(url, data=json.dumps(payload)) datas=json.loads(response.text)['locs'] datas=datas.split(',') datas=[int(i) for i in datas[:-1]] all_data=[] a=[] for n,data in enumerate(datas): a.append(data) all_data.append(a) if (n+1)%3==0: a=[] all_data=[[i[0]/100,i[1]/100,i[2]] for i in all_data]
将数据转换为DataFrame格式:
import pandas as pd lat=[float(i[0]) for i in all_data] long=[i[1] for i in all_data] weight=[i[2] for i in all_data] dataframe=pd.DataFrame({'纬度':lat,'经度':long,'人数':weight})
对数据进行去重:
dataframe=dataframe.drop_duplicates(keep='first')
有了这些坐标信息,我们可以估算一个区域人流量
pandas小知识:
DataFrame.drop_duplicates(subset=None, keep='first', inplace=False)
subset用来指定特定的列,默认所有列;
keep="first"表示删除重复项并保留第一次出现的项,此外,keep值还可以为'last':表示保留最后一次出现的值;'false':表示所有相同的数据都删除
选定区域:
data1=dataframe[(dataframe.纬度.between(39.26,41.03)) & (dataframe.经度.between(115.25,117.30))]
二、用folium画热力图:
import folium from folium.plugins import HeatMap map_data = data1[['纬度', '经度', '人数']].values.tolist() hmap = folium.Map( location=[data1['纬度'].mean(), data1['经度'].mean()], #地图中心坐标 control_scale=True, zoom_start=13 #地图显示级别 ) hmap.add_child(HeatMap(map_data, radius=5, gradient={.1: 'blue',.3: 'lime', .5: 'yellow',.7:'red'}))
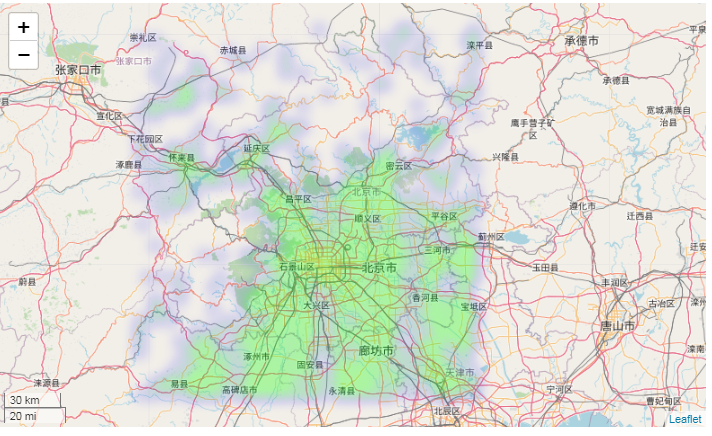
真方!
**********---**--****-------------- End **********---**--****--------------
往期精彩文章推荐:

欢迎大家点赞,留言,转发,转载,****感谢大家的相伴与支持
想加入Python学习群请在后台回复【入群】
万水千山总是情,点个【在看】行不行
/今日留言主题/
随便说一两句吧~
本文分享自微信公众号 - Python爬虫与数据挖掘(crawler_python)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。







