
摘要:一个Cope 攻城狮用切身实例告诉你: Cope代码体验一时爽,BUG修改花半天。
前言:此文为r0.7-beta的操作实践,为什么我的眼里常含泪水,因为我对踩坑这件事爱得深沉。谨以此文献给和我一样踩坑的小伙伴,纪念踩坑时刻。
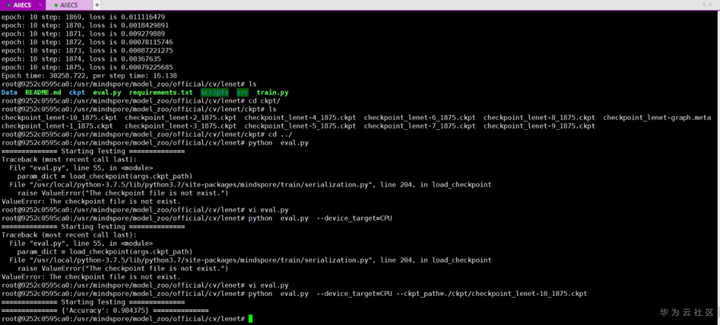
↑开局一张图,故事全靠编。
有时候常常问自己:我一个前端开发,没有python基础,居然敢尝试使用深度学习框架?谁给的勇气,是梁静茹吗?有时候也常常暗示自己“技多不压身”,活得像周树人笔下的阿Q一样洒脱,不过现实就像--我是钻井工,钻了一个又一个的井,因为没有坚持,一次又一次地和宝藏擦肩而过最终空手而归;有时候也常常告慰自己:“Just DO IT”,IT这么吃香,不干IT还能干啥?不就是换个地儿搬砖吗?定个小目标,先跑通MindSpore的LeNet模型!
安装
优秀的全场景深度学习框架开源项目,应该提供Docker安装镜像;先康康我的运行环境:
- Ubuntu 18.04.5 LTS
- Docker version 18.09.6
这次安装的是CPU版本的,命令:
docker pull mindspore/mindspore-cpu:0.7.0-betadocker run -it mindspore/mindspore-cpu:0.7.0-beta /bin/bash
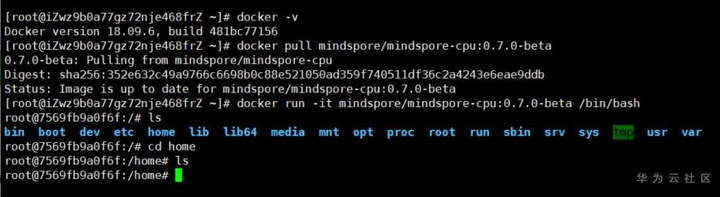
一步到“胃”,直接进入到home目录,接下来Copy攻城狮要开始表演粗劣的Copy***,跑通MindSpore的LeNet模型。
Fork代码
为啥要Fork代码呢?您指望一个毫无核心技术的Copy攻城狮手写一个深度学习框架MindSpore?代码千千万,Fork第一条!不啰嗦,先fork一下**MindSpore官方仓库**,一键拥有深度学习框架。当然Fork之后,我们要将代码clone到本地,因为我的码云账号叫hu-qi,所以我要clone的路径是https://gitee.com/hu-qi/mindspore。
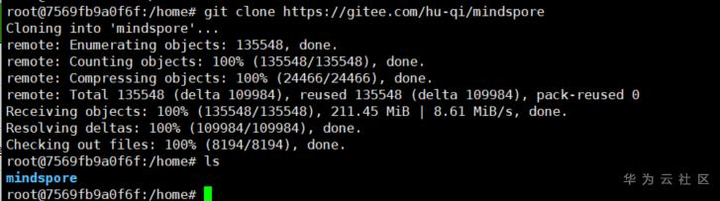
git clone https://gitee.com/hu-qi/mindspore
因为码云是咱自己的,速度倍儿棒,稍等片刻,美味即将呈现。
翻车现场
ModuleNotFoundError: No module named 'mindspore.dataset.vision'.
习惯了瞎折腾,以为直接运行train.py就能一分钟跑通,还是“too young,too simple”。一波错误的示范,然后就是图中巨大的坑:
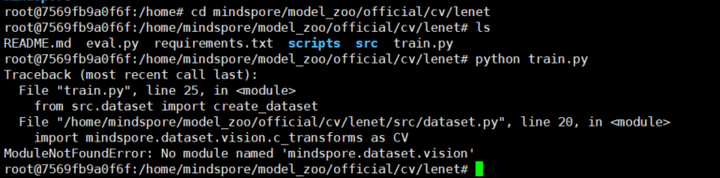
幸好前人已经踩过坑了:Windows系统下跑通华为MindSpore的Lenet网络,尽管是Windows系统的,看上去似乎是相同的问题。为了记录本次踩坑历程,我决定施展一下git技能!
checkout踩坑分支
为了印象更加深刻,我决定将分支命名为9-12,以此纪念"9·12踩坑事件"。
cd /home/mindspore
git checkout -b 9-12

然后参照前人的经验教训开始修改本地文件。
修改文件
本次修改的是两个文件--lenet/train.py和lenet/src/dataset.py。
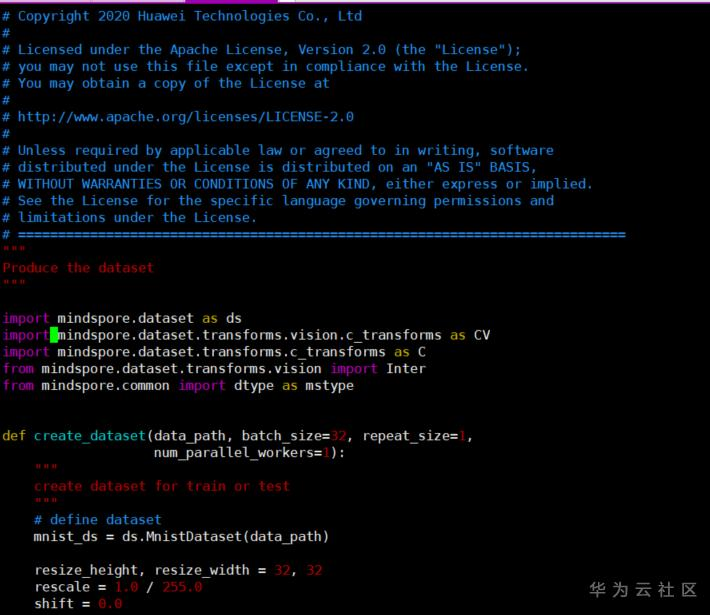
lenet/src/dataset.py
……
line 20新增层级transforms
import mindspore.dataset.transforms.vision.c_transforms as CV
line 22新增层级transforms
from mindspore.dataset.transforms.vision import Int
……
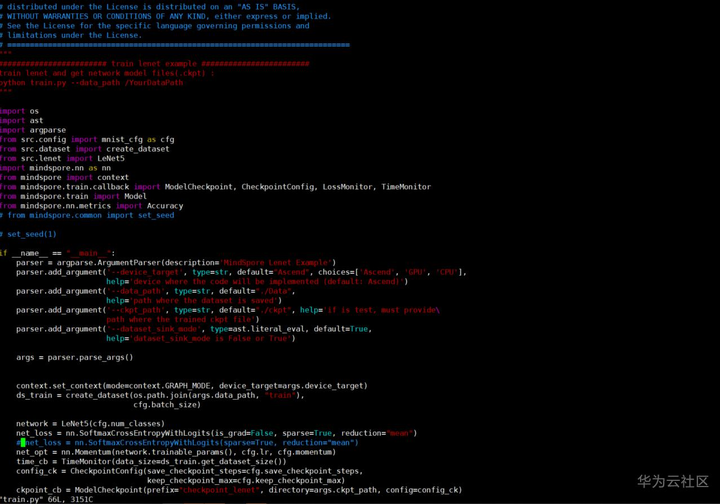
lenet/train.py
……
注释line 32和line34
from mindspore.common import set_seed
set_seed(1)
line 55新增设置is_grad=false
net_loss = nn.SoftmaxCrossEntropyWithLogits(sparse=True, reduction="mean", is_grad=False)
……
在lenet目录满怀信心的执行命令:python train.py --device_target=CPU --dataset_sink_mode=False,结果又是一个错误:**ValueError: The folder ./Data/train does not exist or permission denied!**。
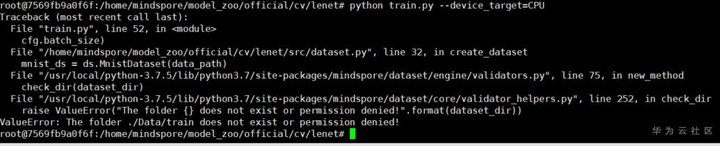
一开始以为是权限的问题,经过一些尝试,发现是没有Data目录。那就在lenet下新建一个Data目录以及子目录test和train吧。
cd /home/mindspore/model_zoo/official/cv/lenet
mkdir Data
mkdir Data/test && mkdir Data/train
然后依旧满怀信心敲下执行训练的命令:python train.py --device_target=CPU --dataset_sink_mode=False

结果又是一个坑:**Unexpected error. There is no valid data matching the dataset API MnistDataset.Please check file path or dataset API validation first.**。怎么办?意识到脚本并没有给我自动下载Mnist数据集,又不懂代码,只好手动去下载了。
下载Mnist数据集
Mnist数据集: http://yann.lecun.com/exdb/mnist/
数据目录结构:
└─Data
├─test
│ t10k-images.idx3-ubyte
│ t10k-labels.idx1-ubyte
│
└─train
train-images.idx3-ubyte
train-labels.idx1-ubyte
既然是linux,二话不说,先来四个wget!
# 切换到Data目录
cd Data
# 下载训练图片
wget
# 下载训练标签
wget
#下载测试图片
wget
# 下载测试标签
wget http://yann.lecun.com/exdb/mnist/t10k-labels-idx1-ubyte.gz

然后又是一波解压操作,来四个gunzip:
gunzip train-images-idx3-ubyte.gz
gunzip train-labels-idx1-ubyte.gz
gunzip t10k-images-idx3-ubyte.gz
gunzip t10k-labels-idx1-ubyte.gz

最后,再来一波移动文件操作压压惊。来四个mv:
mv train-images-idx3-ubyte ./train
mv train-labels-idx1-ubyte ./train
mv t10k-images-idx3-ubyte ./test/
mv t10k-labels-idx1-ubyte ./test/
此时此刻,感受到不懂代码真吃亏,明明几行代码就解决了,我要这么多套“切克闹”才能获取到数据集,我一定向明明学习,争取早日摆脱Copy攻城狮的称号,实现代码自由,赢取开源硕果,走向撸码巅峰!咳咳,再来一盘花生米,我还能唠嗑!
训练及验证
新司机再次上路,这回我总能愉快的训练了吧?
cd /home/mindspore/model_zoo/official/cv/lenet
python train.py --device_target=CPU --dataset_sink_mode=False
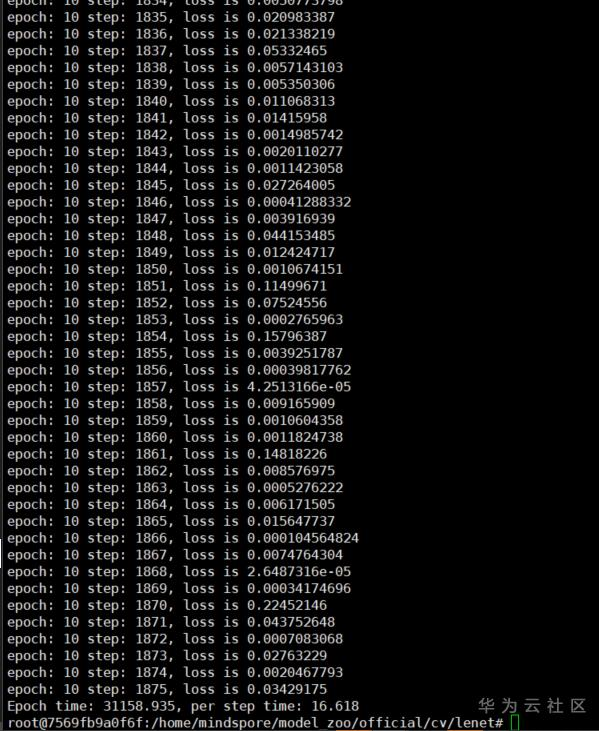
然后终于看到了胜利的曙光,跑起来了!跑起来了!跑起来了! 看到一行行日志不断涌现,我的眼眶噙满了泪水--“小胡,你在干啥?你丫一前端上班在跑模型,不想干了吗?明天去财务领钱……” 还好隔壁王哥及时解围--“他这是在深度学习,以后不会再把1像素切成2像素了”
接下还需要验证一下:
cd /home/mindspore/model_zoo/official/cv/lenet
python eval.py --ckpt_path="ckpt/checkpoint_lenet-10_1875.ckpt" --device_target=CPU
运行结果:
============== Starting Testing ==============
============== {'Accuracy': 0.9847756410256411} ==============

勉强能接受吧,毕竟只整了10个epoch。
上传到远程仓库
尽管我们已经跑通了MindSpore的LeNet,不过我还是希望能把踩的这些坑记录下来,最后再使用一下git技能:
# 切换到本地仓库目录
cd /home/mindspore
# 设置git
git config --global user.email "huqi1008301@163.com"
git config --global user.name "hu-qi"
# 查看本地分支,确保我的9-12还在
git branch
# 查看有哪些改变
git status
# 新增改变
git add .
# 提交改变到缓存仓库
git commit -m 'finish LeNet'
# 推送分支到远程(按照提示登录)
git push origin 9-12
一顿操作猛如虎,一看代码原地杵,当然要切换到9-12这个分支才有的啦。
结语
所谓“一分钟”的体验,大概花了一个小时踩坑了,然后大概花了三个小时来记录。不足之处,期待各位大佬多多指教!











