
摘要:童年时候,我们会对着墙上挂着的中国地图,来认识一处处山川河流和城市人文。如今,数字化时代下,传统的地图已经不能满足人们的需求,如何获取各种丰富的地理内容和实时动态信息成为现代人普遍的地理信息诉求。作为国家基础地理信息公共服务平台,天地图集成了来自国家、省、市(县)各级测绘地理信息部门,以及相关政府部门、企事业单位 、社会团体、公众的地理信息公共服务资源,以门户网站、服务接口、前置服务等形式向政府、专业部门、企业、公众等用户提供在线地理信息服务。此前,国家基础地理信息中心携手华为云,基于天地图平台,共同打造云上智慧地图,促进地理信息资源共享和高效利用,让世界触手可及。
地理数据量增加,数据库弹性迎挑战
天地图覆盖全国300多个地级以及地级以上城市0.6米分辨率的卫星遥感影像等地理信息数据,全库数据量达到17TB,数据吞吐量巨大。巨大的吞吐量和高额运维成本,促使国家基础地理信息中心迫切寻求低成本、高可用、高性能、大容量的数据库产品,同时希望可以将迁移时间压缩到2天左右。
- 低成本:早期天地图运营投入较多资金,包括数据库在内的IT投入成本居高不下。业务有读写分离诉求,希望在保证性能的前提下,通过一套实例实现读写分离,从而降低数据库成本。
- 高可用:社区版MongoDB一个shard多数节点故障,就会导致该shard成为只读,因此希望提供无状态的路由节点,实现快速故障转移。
- 高性能:天地图每天的访问量在6亿左右,随着数据量和业务访问量的增加,现有系统不足以支撑日益增长的业务需求,需要更高性能的数据库来支撑日益增长的业务数据。
- 容量:随着瓦片层级增加,数据量越来越大,现有MongoDB扩容难度大,需要一款数据库支持不少于20TB的瓦片数据,支持在线扩容。
- 运维效率:运维人力有限,系统运维压力越来越大,运维工作成本越来越高,现有社区版MongoDB难以支撑运维工作需求。希望能够提供数据库自运维能力,能为数据库做技术兜底,降低运维成本。

天地图&华为云
- 彰显云上“数字中国”新魅力
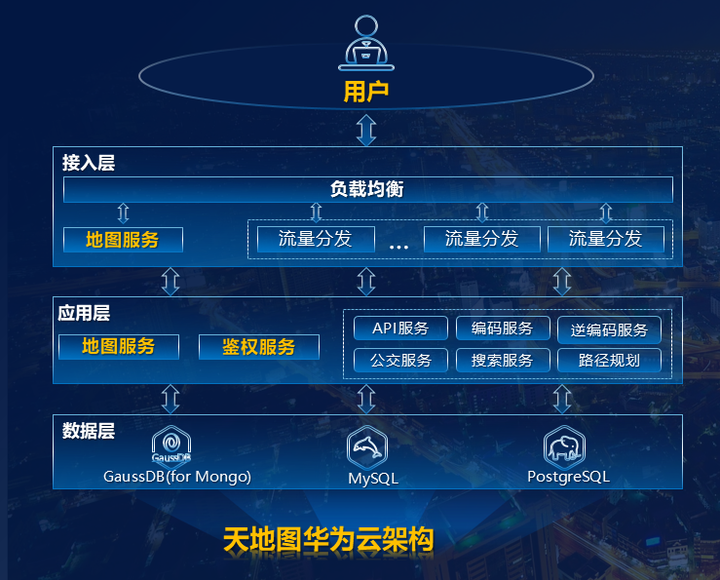
天地图业务数据复杂,数据种类多样,结合客户诉求和业务特点,华为云数据库采用公有云对外服务为主,私有云对内测试为辅的混合云架构,提供多种数据库引擎方案,联合打造高性能、高可用的数字底座。
华为云GaussDB(for Mongo)提供在线地图的瓦片数据处理服务;华为云RDS for PostgreSQL提供矢量数据和三维数据处理服务;华为云RDS for MySQL提供用户管理和专题图层属性服务,多款数据库极速融合,共同发力,17TB的海量数据迁移仅仅用了2天。
- 高可用特性加持,业务稳定运行
天地图作为国家级的服务平台,数据的安全可靠可谓至关重要。华为云GaussDB(for Mongo)支持跨AZ高可用,拥有完善的跨区域容灾策略,每天自动进行全量备份和增量备份,并定期进行恢复演练,验证备份恢复流程的有效性,实现分钟级备份恢复。同时提供无状态的路由节点,支持秒级故障转移,客户业务无感知,业务运行稳定。
- 超高性能与大容量,再大流量也不怕
天地图为30+部委机构和全国30多个省市提供地理信息基础平台服务,日均API和服务调用超过6亿次,访问压力极大。华为云GaussDB(for Mongo) 可实现分钟级节点扩容和秒级存储扩容,满足敏捷业务弹性需要,对天地图高达上亿的访问毫无压力,响应能力快稳准,有效保障了天地图在高负载情景下业务的正常运行。而且GaussDB(for Mongo)基于存算分离架构和rocksdb优化,相比开源MongDB性能提高3倍以上,最大支持96TB的数据处理能力,完全满足天地图海量业务请求。
- 降本增效不止一点点
GaussDB(for Mongo)完全兼容MongoDB协议,客户业务无需任何改造,即可轻松切换数据库,极大减少了改造成本;而且通过实时生成快照和删除快照的能力,GaussDB(for Mongo)实现一套集群即可提供读写分离的能力,数据库成本节省至少50%。天地图上华为云之后,基于数据库服务自动化运维平台,数据更新效率提升5倍,新业务上线速度提高2倍,还减轻了DBA繁重的运维压力,让客户更聚焦业务层面。
自2019年2月上线以来,华为云数据库已轻松支撑天地图6亿+的日均访问量,保障业务平稳运行,实现零事故;同时为公众提供了更为全面、精准、权威、 智能、人性化的地理信息服务,让全社会共享测绘发展成果,感受“数字中国”的独特魅力。
Ps:【云数据库特惠专场】新用户4.5折起,助力企业效益增长, 详情请戳https://activity.huaweicloud.com/dbs_Promotion/index.html











