
声明:师从老男孩太白金星,不对代码做任何保证,如有问题请自携兵刃直奔沙河
2.6.1 字典的初识
**Why:**咱们目前已经学习到的容器型数据类型只有list,那么list够用?他有什么缺点呢?
1. 列表可以存储大量的数据类型,但是如果数据量大的话,他的查询速度比较慢。
2. 列表只能按照顺序存储,数据与数据之间关联性不强。
所以针对于上的缺点,说咱们需要引入另一种容器型的数据类型,解决上面的问题,这就需要dict字典。
what:
数据类型可以按照多种角度进行分类,就跟咱们人一样,人按照地域可以划分分为亚洲人,欧洲人,美洲人等,但是按照肤色又可以分为白种人,黄种人,黑种人,等等,数据类型可以按照不同的角度进行分类,先给大家按照可变与不可变的数据类型的分类:
不可变(可哈希)的数据类型:int,str,bool,tuple。
可变(不可哈希)的数据类型:list,dict,set。
字典是Python语言中的映射类型,他是以{}括起来,里面的内容是以键值对的形式储存的:
Key: 不可变(可哈希)的数据类型.并且键是唯一的,不重复的。
Value:任意数据(int,str,bool,tuple,list,dict,set),包括后面要学的实例对象等。
在Python3.5版本(包括此版本)之前,字典是无序的。
在Python3.6版本之后,字典会按照初建字典时的顺序排列(即第一次插入数据的顺序排序)。
当然,字典也有缺点:他的缺点就是内存消耗巨大。
字典查询之所以快的解释:(了解)
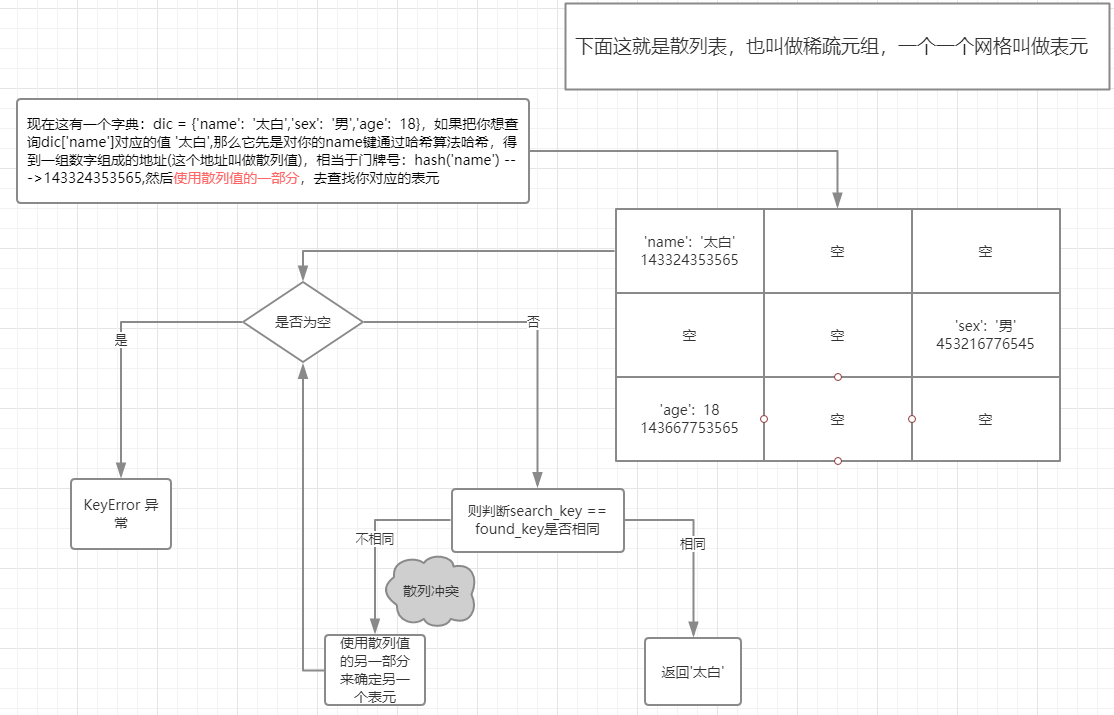
字典的查询速度非常快,简单解释一下原因:字典的键值对会存在一个散列表(稀疏数组)这样的空间中,每一个单位称作一个表元,表元里面记录着key:value,如果你想要找到这个key对应的值,先要对这个key进行hash获取一串数字咱们简称为门牌号(非内存地址),然后通过门牌号,确定表元,对比查询的key与被锁定的key是否相同,如果相同,将值返回,如果不同,报错。(这里只是简单的说一下过程,其实还是比较复杂的。),下面我已图形举例:
# 此段解释来源于《流畅的python》.
这一节笼统地描述了 Python 如何用散列表来实现 dict 类型,有些细节只是一笔带过,像
CPython 里的一些优化技巧 就没有提到。但是总体来说描述是准确的。
Python 源码 dictobject.c 模块(http://hg.python.org/cpython/file/tip/Objects/dictobject.c)里有丰富的注释,另外延伸阅
读中有对《代码之美》一书的引用。
为了简单起见,这里先集中讨论 dict 的内部结构,然后再延伸到集合上面。
散列表其实是一个稀疏数组(总是有空白元素的数组称为稀疏数组)。在一般的数据结构
教材中,散列表里的单元通常叫作表元(bucket)。在 dict 的散列表当中,每个键值对
都占用一个表元,每个表元都有两个部分,一个是对键的引用,另一个是对值的引用。因
为所有表元的大小一致,所以可以通过偏移量来读取某个表元。
因为 Python 会设法保证大概还有三分之一的表元是空的,所以在快要达到这个阈值的时
候,原有的散列表会被复制到一个更大的空间里面。
如果要把一个对象放入散列表,那么首先要计算这个元素键的散列值。Python 中可以用
hash() 方法来做这件事情,接下来会介绍这一点。
01. 散列值和相等性
内置的 hash() 方法可以用于所有的内置类型对象。如果是自定义对象调用 hash()
的话,实际上运行的是自定义的 __hash__。如果两个对象在比较的时候是相等的,
那它们的散列值必须相等,否则散列表就不能正常运行了。例如,如果 1 == 1.0 为
8
真,那么 hash(1) == hash(1.0) 也必须为真,但其实这两个数字(整型和浮点)
的内部结构是完全不一样的。
为了让散列值能够胜任散列表索引这一角色,它们必须在索引空间中尽量分散开来。
这意味着在最理想的状况下,越是相似但不相等的对象,它们散列值的差别应该越
大。示例 3-16 是一段代码输出,这段代码被用来比较散列值的二进制表达的不同。
注意其中 1 和 1.0 的散列值是相同的,而 1.0001、1.0002 和 1.0003 的散列值则非常不
同。
示例 3-16 在32 位的 Python 中,1、1.0001、1.0002 和 1.0003 这几个数的散列
值的二进制表达对比(上下两个二进制间不同的位被 ! 高亮出来,表格的最右
列显示了有多少位不相同)
32-bit Python build
00000000000000000000000000000001
!= 0
1.0 00000000000000000000000000000001
------------------------------------------------
1.0 00000000000000000000000000000001
! !!! ! !! ! ! ! ! !! !!! != 16
1.0001 00101110101101010000101011011101
------------------------------------------------
1.0001 00101110101101010000101011011101
!!! !!!! !!!!! !!!!! !! ! != 20
1.0002 01011101011010100001010110111001
------------------------------------------------
1.0002 01011101011010100001010110111001
! ! ! !!! ! ! !! ! ! ! !!!! != 17
1.0003 00001100000111110010000010010110
------------------------------------------------
用来计算示例 3-16 的程序见于附录 A。尽管程序里大部分代码都是用来整理输出格
式的,考虑到完整性,我还是把全部的代码放在示例 A-3 中了。
从 Python 3.3 开始,str、bytes 和 datetime 对象的散列值计算过程中多
了随机的“加盐”这一步。所加盐值是 Python 进程内的一个常量,但是每次启动
Python 解释器都会生成一个不同的盐值。随机盐值的加入是为了防止 DOS 攻击
而采取的一种安全措施。在 __hash__ 特殊方法的文档
(https://docs.python.org/3/reference/datamodel.html#object.\_\_hash\_\_) 里有相关的详
细信息。
了解对象散列值相关的基本概念之后,我们可以深入到散列表工作原理背后的算法
了。
02. 散列表算法
为了获取 my_dict[search_key] 背后的值,Python 首先会调用 hash(search_key)来计算 search_key 的散列值,把这个值最低的几位数字当作偏移量,在散列表里查找表元(具体取几位,得看当前散列表的大小)。若找到的表元是空的,则抛出KeyError 异常。若不是空的,则表元里会有一对 found_key:found_value。这时候 Python 会检验 search_key == found_key 是否为真,如果它们相等的话,就会返回 found_value。如果 search_key 和 found_key 不匹配的话,这种情况称为散列冲突。发生这种情况是因为,散列表所做的其实是把随机的元素映射到只有几位的数字上,而散列表本身的索引又只依赖于这个数字的一部分。为了解决散列冲突,算法会在散列值中另外再取几位,然后用特殊的方法处理一下,把新得到的数字再当作索引来寻找表元。若这次找到的表元是空的,则同样抛出 KeyError;若非空,或者键匹配,则返回这个值;或者又发现了散列冲突,则重复以上的步骤。图 3-3 展示了这个算法的示意
图。图 3-3:从字典中取值的算法流程图;给定一个键,这个算法要么返回一个值,要么抛出 KeyError 异常添加新元素和更新现有键值的操作几乎跟上面一样。只不过对于前者,在发现空表元的时候会放入一个新元素;对于后者,在找到相对应的表元后,原表里的值对象会被替换成新值。
另外在插入新值时,Python 可能会按照散列表的拥挤程度来决定是否要重新分配内存为它扩容。如果增加了散列表的大小,那散列值所占的位数和用作索引的位数都会随之增加,这样做的目的是为了减少发生散列冲突的概率。表面上看,这个算法似乎很费事,而实际上就算 dict 里有数百万个元素,多数的搜索过程中并不会有冲突发生,平均下来每次搜索可能会有一到两次冲突。在正常情况下,就算是最不走运的键所遇到的冲突的次数用一只手也能数过来。了解 dict 的工作原理能让我们知道它的所长和所短,以及从它衍生而来的数据类型
详细解释

# 此段解释来源于《流畅的python》.
这一节笼统地描述了 Python 如何用散列表来实现 dict 类型,有些细节只是一笔带过,像
CPython 里的一些优化技巧 就没有提到。但是总体来说描述是准确的。
Python 源码 dictobject.c 模块(http://hg.python.org/cpython/file/tip/Objects/dictobject.c)里有丰富的注释,另外延伸阅
读中有对《代码之美》一书的引用。
为了简单起见,这里先集中讨论 dict 的内部结构,然后再延伸到集合上面。
散列表其实是一个稀疏数组(总是有空白元素的数组称为稀疏数组)。在一般的数据结构
教材中,散列表里的单元通常叫作表元(bucket)。在 dict 的散列表当中,每个键值对
都占用一个表元,每个表元都有两个部分,一个是对键的引用,另一个是对值的引用。因
为所有表元的大小一致,所以可以通过偏移量来读取某个表元。
因为 Python 会设法保证大概还有三分之一的表元是空的,所以在快要达到这个阈值的时
候,原有的散列表会被复制到一个更大的空间里面。
如果要把一个对象放入散列表,那么首先要计算这个元素键的散列值。Python 中可以用
hash() 方法来做这件事情,接下来会介绍这一点。
01. 散列值和相等性
内置的 hash() 方法可以用于所有的内置类型对象。如果是自定义对象调用 hash()
的话,实际上运行的是自定义的 __hash__。如果两个对象在比较的时候是相等的,
那它们的散列值必须相等,否则散列表就不能正常运行了。例如,如果 1 == 1.0 为
8
8
真,那么 hash(1) == hash(1.0) 也必须为真,但其实这两个数字(整型和浮点)
的内部结构是完全不一样的。
为了让散列值能够胜任散列表索引这一角色,它们必须在索引空间中尽量分散开来。
这意味着在最理想的状况下,越是相似但不相等的对象,它们散列值的差别应该越
大。示例 3-16 是一段代码输出,这段代码被用来比较散列值的二进制表达的不同。
注意其中 1 和 1.0 的散列值是相同的,而 1.0001、1.0002 和 1.0003 的散列值则非常不
同。
示例 3-16 在32 位的 Python 中,1、1.0001、1.0002 和 1.0003 这几个数的散列
值的二进制表达对比(上下两个二进制间不同的位被 ! 高亮出来,表格的最右
列显示了有多少位不相同)
32-bit Python build
1 00000000000000000000000000000001
!= 0
1.0 00000000000000000000000000000001
------------------------------------------------
1.0 00000000000000000000000000000001
! !!! ! !! ! ! ! ! !! !!! != 16
1.0001 00101110101101010000101011011101
------------------------------------------------
1.0001 00101110101101010000101011011101
!!! !!!! !!!!! !!!!! !! ! != 20
1.0002 01011101011010100001010110111001
------------------------------------------------
1.0002 01011101011010100001010110111001
! ! ! !!! ! ! !! ! ! ! !!!! != 17
1.0003 00001100000111110010000010010110
------------------------------------------------
用来计算示例 3-16 的程序见于附录 A。尽管程序里大部分代码都是用来整理输出格
式的,考虑到完整性,我还是把全部的代码放在示例 A-3 中了。
从 Python 3.3 开始,str、bytes 和 datetime 对象的散列值计算过程中多
了随机的“加盐”这一步。所加盐值是 Python 进程内的一个常量,但是每次启动
Python 解释器都会生成一个不同的盐值。随机盐值的加入是为了防止 DOS 攻击
而采取的一种安全措施。在 __hash__ 特殊方法的文档
(https://docs.python.org/3/reference/datamodel.html#object.__hash__) 里有相关的详
细信息。
了解对象散列值相关的基本概念之后,我们可以深入到散列表工作原理背后的算法
了。
02. 散列表算法
为了获取 my_dict[search_key] 背后的值,Python 首先会调用 hash(search_key)来计算 search_key 的散列值,把这个值最低的几位数字当作偏移量,在散列表里查找表元(具体取几位,得看当前散列表的大小)。若找到的表元是空的,则抛出KeyError 异常。若不是空的,则表元里会有一对 found_key:found_value。这时候 Python 会检验 search_key == found_key 是否为真,如果它们相等的话,就会返回 found_value。如果 search_key 和 found_key 不匹配的话,这种情况称为散列冲突。发生这种情况是因为,散列表所做的其实是把随机的元素映射到只有几位的数字上,而散列表本身的索引又只依赖于这个数字的一部分。为了解决散列冲突,算法会在散列值中另外再取几位,然后用特殊的方法处理一下,把新得到的数字再当作索引来寻找表元。若这次找到的表元是空的,则同样抛出 KeyError;若非空,或者键匹配,则返回这个值;或者又发现了散列冲突,则重复以上的步骤。图 3-3 展示了这个算法的示意
图。图 3-3:从字典中取值的算法流程图;给定一个键,这个算法要么返回一个值,要么抛出 KeyError 异常添加新元素和更新现有键值的操作几乎跟上面一样。只不过对于前者,在发现空表元的时候会放入一个新元素;对于后者,在找到相对应的表元后,原表里的值对象会被替换成新值。
另外在插入新值时,Python 可能会按照散列表的拥挤程度来决定是否要重新分配内存为它扩容。如果增加了散列表的大小,那散列值所占的位数和用作索引的位数都会随之增加,这样做的目的是为了减少发生散列冲突的概率。表面上看,这个算法似乎很费事,而实际上就算 dict 里有数百万个元素,多数的搜索过程中并不会有冲突发生,平均下来每次搜索可能会有一到两次冲突。在正常情况下,就算是最不走运的键所遇到的冲突的次数用一只手也能数过来。了解 dict 的工作原理能让我们知道它的所长和所短,以及从它衍生而来的数据类型

由于字典使用了散列表,而散列表又必须是稀疏的,这导致它在空间上的效率低下。举例而言,如果你需要存放数量巨大的记录,那么放在由元组或是具名元组构成的列表中会是比较好的选择;最好不要根据 JSON 的风格,用由字典组成的列表来存放这些记录。用元组取代字典就能节省空间的原因有两个:其一是避免了散列表所耗费的空间,其二是无需把记录中字段的名字在每个元素里都存一遍。记住我们现在讨论的是空间优化。如果你手头有几百万个对象,而你的机器有几个GB 的内存,那么空间的优化工作可以等到真正需要的时候再开始计划,因为优化往往是可维护性的对立面。
由于字典使用了散列表,而散列表又必须是稀疏的,这导致它在空间上的效率低下。举例而言,如果你需要存放数量巨大的记录,那么放在由元组或是具名元组构成的列表中会是比较好的选择;最好不要根据 JSON 的风格,用由字典组成的列表来存放这些记录。用元组取代字典就能节省空间的原因有两个:其一是避免了散列表所耗费的空间,其二是无需把记录中字段的名字在每个元素里都存一遍。记住我们现在讨论的是空间优化。如果你手头有几百万个对象,而你的机器有几个GB 的内存,那么空间的优化工作可以等到真正需要的时候再开始计划,因为优化往往是可维护性的对立面。
2.6.2 创建字典的几种方式:
# 创建字典的几种方式:
# 方式1:
dic = dict((('one', 1),('two', 2),('three', 3)))
# dic = dict([('one', 1),('two', 2),('three', 3)])
print(dic) # {'one': 1, 'two': 2, 'three': 3}
# 方式2:
dic = dict(one=1,two=2,three=3)
print(dic) # {'one': 1, 'two': 2, 'three': 3}
# 方式3:
dic = dict({'one': 1, 'two': 2, 'three': 3})
print(dic) # {'one': 1, 'two': 2, 'three': 3}
# 方式5: 后面会讲到先了解
dic = dict(zip(['one', 'two', 'three'],[1, 2, 3]))
print(dic)
# 方式6: 字典推导式 后面会讲到
# dic = { k: v for k,v in [('one', 1),('two', 2),('three', 3)]}
# print(dic)
# 方式7:利用fromkey后面会讲到。
# dic = dict.fromkeys('abcd','太白')
# print(dic) # {'a': '太白', 'b': '太白', 'c': '太白', 'd': '太白'}

# 创建字典的几种方式:
# 方式1:
dic = dict((('one', 1),('two', 2),('three', 3)))
# dic = dict([('one', 1),('two', 2),('three', 3)])
print(dic) # {'one': 1, 'two': 2, 'three': 3}
# 方式2:
dic = dict(one=1,two=2,three=3)
print(dic) # {'one': 1, 'two': 2, 'three': 3}
# 方式3:
dic = dict({'one': 1, 'two': 2, 'three': 3})
print(dic) # {'one': 1, 'two': 2, 'three': 3}
# 方式5: 后面会讲到先了解
dic = dict(zip(['one', 'two', 'three'],[1, 2, 3]))
print(dic)
# 方式6: 字典推导式 后面会讲到
# dic = { k: v for k,v in [('one', 1),('two', 2),('three', 3)]}
# print(dic)
# 方式7:利用fromkey后面会讲到。
# dic = dict.fromkeys('abcd','太白')
# print(dic) # {'a': '太白', 'b': '太白', 'c': '太白', 'd': '太白'}

2.6.3 验证字典的合法性
# 合法
dic = {123: 456, True: 999, "id": 1, "name": 'sylar', "age": 18, "stu": ['帅
哥', '美⼥'], (1, 2, 3): '麻花藤'}
print(dic[123])
print(dic[True])
print(dic['id'])
print(dic['stu'])
print(dic[(1, 2, 3)])
# 不合法
# dic = {[1, 2, 3]: '周杰伦'} # list是可变的. 不能作为key
# dic = {{1: 2}: "哈哈哈"} # dict是可变的. 不能作为key
dic = {{1, 2, 3}: '呵呵呵'} # set是可变的, 不能作为key

# 合法
dic = {123: 456, True: 999, "id": 1, "name": 'sylar', "age": 18, "stu": ['帅
哥', '美⼥'], (1, 2, 3): '麻花藤'}
print(dic[123])
print(dic[True])
print(dic['id'])
print(dic['stu'])
print(dic[(1, 2, 3)])
# 不合法
# dic = {[1, 2, 3]: '周杰伦'} # list是可变的. 不能作为key
# dic = {{1: 2}: "哈哈哈"} # dict是可变的. 不能作为key
dic = {{1, 2, 3}: '呵呵呵'} # set是可变的, 不能作为key

2.6.4 字典的常用操作方法
接下来咱们就进入字典的学习环节,字典对于咱们小白来说可能相对于列表是不好理解的,因为列表是有序的一个一个排列的,但是字典的键值对对于大家来说是比较陌生的,所以咱们可以把字典比喻成一个公寓,公寓里面有N多个房间,房间号就是键,房间里面具体的东西就值:比如房间001号:对应的房间住着两个人,也就是2person,简称2P,房间99号:3P, 房间78号:有人还有小动物....... 这样,咱们就能通过房间号(也就是键)找到对应的房间,查看里面的内容,也就是值。
那么首先先从字典的增删改查开始学习。
增
# 通过键值对直接增加
dic = {'name': '太白', 'age': 18}
dic['weight'] = 75 # 没有weight这个键,就增加键值对
print(dic) # {'name': '太白', 'age': 18, 'weight': 75}
dic['name'] = 'barry' # 有name这个键,就成了字典的改值
print(dic) # {'name': 'barry', 'age': 18, 'weight': 75}
# setdefault
dic = {'name': '太白', 'age': 18}
dic.setdefault('height',175) # 没有height此键,则添加
print(dic) # {'name': '太白', 'age': 18, 'height': 175}
dic.setdefault('name','barry') # 有此键则不变
print(dic) # {'name': '太白', 'age': 18, 'height': 175}
#它有返回值
dic = {'name': '太白', 'age': 18}
ret = dic.setdefault('name')
print(ret) # 太白
字典的增

# 通过键值对直接增加
dic = {'name': '太白', 'age': 18}
dic['weight'] = 75 # 没有weight这个键,就增加键值对
print(dic) # {'name': '太白', 'age': 18, 'weight': 75}
dic['name'] = 'barry' # 有name这个键,就成了字典的改值
print(dic) # {'name': 'barry', 'age': 18, 'weight': 75}
# setdefault
dic = {'name': '太白', 'age': 18}
dic.setdefault('height',175) # 没有height此键,则添加
print(dic) # {'name': '太白', 'age': 18, 'height': 175}
dic.setdefault('name','barry') # 有此键则不变
print(dic) # {'name': '太白', 'age': 18, 'height': 175}
#它有返回值
dic = {'name': '太白', 'age': 18}
ret = dic.setdefault('name')
print(ret) # 太白

删
# pop 通过key删除字典的键值对,有返回值,可设置返回值。
dic = {'name': '太白', 'age': 18}
# ret = dic.pop('name')
# print(ret,dic) # 太白 {'age': 18}
ret1 = dic.pop('n',None)
print(ret1,dic) # None {'name': '太白', 'age': 18}
#popitem 3.5版本之前,popitem为随机删除,3.6之后为删除最后一个,有返回值
dic = {'name': '太白', 'age': 18}
ret = dic.popitem()
print(ret,dic) # ('age', 18) {'name': '太白'}
#clear 清空字典
dic = {'name': '太白', 'age': 18}
dic.clear()
print(dic) # {}
# del
# 通过键删除键值对
dic = {'name': '太白', 'age': 18}
del dic['name']
print(dic) # {'age': 18}
#删除整个字典
del dic
字典的删

# pop 通过key删除字典的键值对,有返回值,可设置返回值。
dic = {'name': '太白', 'age': 18}
# ret = dic.pop('name')
# print(ret,dic) # 太白 {'age': 18}
ret1 = dic.pop('n',None)
print(ret1,dic) # None {'name': '太白', 'age': 18}
#popitem 3.5版本之前,popitem为随机删除,3.6之后为删除最后一个,有返回值
dic = {'name': '太白', 'age': 18}
ret = dic.popitem()
print(ret,dic) # ('age', 18) {'name': '太白'}
#clear 清空字典
dic = {'name': '太白', 'age': 18}
dic.clear()
print(dic) # {}
# del
# 通过键删除键值对
dic = {'name': '太白', 'age': 18}
del dic['name']
print(dic) # {'age': 18}
#删除整个字典
del dic

改
# 通过键值对直接改
dic = {'name': '太白', 'age': 18}
dic['name'] = 'barry'
print(dic) # {'name': 'barry', 'age': 18}
# update
dic = {'name': '太白', 'age': 18}
dic.update(sex='男', height=175)
print(dic) # {'name': '太白', 'age': 18, 'sex': '男', 'height': 175}
dic = {'name': '太白', 'age': 18}
dic.update([(1, 'a'),(2, 'b'),(3, 'c'),(4, 'd')])
print(dic) # {'name': '太白', 'age': 18, 1: 'a', 2: 'b', 3: 'c', 4: 'd'}
dic1 = {"name":"jin","age":18,"sex":"male"}
dic2 = {"name":"alex","weight":75}
dic1.update(dic2)
print(dic1) # {'name': 'alex', 'age': 18, 'sex': 'male', 'weight': 75}
print(dic2) # {'name': 'alex', 'weight': 75}
字典的改

# 通过键值对直接改
dic = {'name': '太白', 'age': 18}
dic['name'] = 'barry'
print(dic) # {'name': 'barry', 'age': 18}
# update
dic = {'name': '太白', 'age': 18}
dic.update(sex='男', height=175)
print(dic) # {'name': '太白', 'age': 18, 'sex': '男', 'height': 175}
dic = {'name': '太白', 'age': 18}
dic.update([(1, 'a'),(2, 'b'),(3, 'c'),(4, 'd')])
print(dic) # {'name': '太白', 'age': 18, 1: 'a', 2: 'b', 3: 'c', 4: 'd'}
dic1 = {"name":"jin","age":18,"sex":"male"}
dic2 = {"name":"alex","weight":75}
dic1.update(dic2)
print(dic1) # {'name': 'alex', 'age': 18, 'sex': 'male', 'weight': 75}
print(dic2) # {'name': 'alex', 'weight': 75}

查
# 通过键查询
# 直接dic[key](没有此键会报错)
dic = {'name': '太白', 'age': 18}
print(dic['name']) # 太白
# get
dic = {'name': '太白', 'age': 18}
v = dic.get('name')
print(v) # '太白'
v = dic.get('name1')
print(v) # None
v = dic.get('name2','没有此键')
print(v) # 没有此键
keys()
dic = {'name': '太白', 'age': 18}
print(dic.keys()) # dict_keys(['name', 'age'])
values()
dic = {'name': '太白', 'age': 18}
print(dic.values()) # dict_values(['太白', 18])
items()
dic = {'name': '太白', 'age': 18}
print(dic.items()) # dict_items([('name', '太白'), ('age', 18)])
字典的查

# 通过键查询
# 直接dic[key](没有此键会报错)
dic = {'name': '太白', 'age': 18}
print(dic['name']) # 太白
# get
dic = {'name': '太白', 'age': 18}
v = dic.get('name')
print(v) # '太白'
v = dic.get('name1')
print(v) # None
v = dic.get('name2','没有此键')
print(v) # 没有此键
keys()
dic = {'name': '太白', 'age': 18}
print(dic.keys()) # dict_keys(['name', 'age'])
values()
dic = {'name': '太白', 'age': 18}
print(dic.values()) # dict_values(['太白', 18])
items()
dic = {'name': '太白', 'age': 18}
print(dic.items()) # dict_items([('name', '太白'), ('age', 18)])

dic = {'k1': "v1", "k2": "v2", "k3": [11,22,33]}
请在字典中添加一个键值对,"k4": "v4",输出添加后的字典
请在修改字典中 "k1" 对应的值为 "alex",输出修改后的字典
请在k3对应的值中追加一个元素 44,输出修改后的字典
请在k3对应的值的第 1 个位置插入个元素 18,输出修改后的字典
dic = {'k1': "v1", "k2": "v2", "k3": [11,22,33]}
请在字典中添加一个键值对,"k4": "v4",输出添加后的字典
请在修改字典中 "k1" 对应的值为 "alex",输出修改后的字典
请在k3对应的值中追加一个元素 44,输出修改后的字典
请在k3对应的值的第 1 个位置插入个元素 18,输出修改后的字典
fromkeys 数据类型的补充时会给大家讲到~
dic = dict.fromkeys('abcd','太白')
print(dic) # {'a': '太白', 'b': '太白', 'c': '太白', 'd': '太白'}
dic = dict.fromkeys([1, 2, 3],'太白')
print(dic) # {1: '太白', 2: '太白', 3: '太白'}
dic = dict.fromkeys('abcd','太白')
print(dic) # {'a': '太白', 'b': '太白', 'c': '太白', 'd': '太白'}
dic = dict.fromkeys([1, 2, 3],'太白')
print(dic) # {1: '太白', 2: '太白', 3: '太白'}
其他操作
key_list = dic.keys()
print(key_list)
结果:
dict_keys(['剑圣', '哈啥给', '大宝剑'])
# 一个高仿列表,存放的都是字典中的key
# 并且这个高仿的列表可以转化成列表
print(list(key_list))
# 它还可以循环打印
dic = {'剑圣':'易','哈啥给':'剑豪','大宝剑':'盖伦'}
for i in dic:
print(i)
value_list = dic.values()
print(value_list)
结果:
dict_values(['易', '剑豪', '盖伦'])
#一个高仿列表,存放都是字典中的value
# 并且这个高仿的列表可以转化成列表
print(list(value_list))
# 它还可以循环打印
for i in dic.values():
print(i)
key_value_list = dic.items()
print(key_value_list)
结果:
dict_items([('剑圣', '易'), ('哈啥给', '剑豪'), ('大宝剑', '盖伦')])
# 一个高仿列表,存放是多个元祖,元祖中第一个是字典中的键,第二个是字典中的值
# 并且这个高仿的列表可以转化成列表
print(list(key_value_list ))
# 它还可以循环打印
dic = {'剑圣':'易','哈啥给':'剑豪','大宝剑':'盖伦'}
for i in dic.items():
print(i)
结果:
('剑圣', '易')
('哈啥给', '剑豪')
('大宝剑', '盖伦')

key_list = dic.keys()
print(key_list)
结果:
dict_keys(['剑圣', '哈啥给', '大宝剑'])
# 一个高仿列表,存放的都是字典中的key
# 并且这个高仿的列表可以转化成列表
print(list(key_list))
# 它还可以循环打印
dic = {'剑圣':'易','哈啥给':'剑豪','大宝剑':'盖伦'}
for i in dic:
print(i)
value_list = dic.values()
print(value_list)
结果:
dict_values(['易', '剑豪', '盖伦'])
#一个高仿列表,存放都是字典中的value
# 并且这个高仿的列表可以转化成列表
print(list(value_list))
# 它还可以循环打印
for i in dic.values():
print(i)
key_value_list = dic.items()
print(key_value_list)
结果:
dict_items([('剑圣', '易'), ('哈啥给', '剑豪'), ('大宝剑', '盖伦')])
# 一个高仿列表,存放是多个元祖,元祖中第一个是字典中的键,第二个是字典中的值
# 并且这个高仿的列表可以转化成列表
print(list(key_value_list ))
# 它还可以循环打印
dic = {'剑圣':'易','哈啥给':'剑豪','大宝剑':'盖伦'}
for i in dic.items():
print(i)
结果:
('剑圣', '易')
('哈啥给', '剑豪')
('大宝剑', '盖伦')

这里补充一个知识点:分别赋值,也叫拆包。
a,b = 1,2
print(a,b)
结果:
2
a,b = ('你好','世界') # 这个用专业名词就叫做元组的拆包
print(a,b)
结果:
你好 世界
a,b = ['你好','大飞哥']
print(a,b)
结果:
你好 世界
a,b = {'汪峰':'北京北京','王菲':'天后'}
print(a,b)
结果:
汪峰 王菲

a,b = 1,2
print(a,b)
结果:
1 2
a,b = ('你好','世界') # 这个用专业名词就叫做元组的拆包
print(a,b)
结果:
你好 世界
a,b = ['你好','大飞哥']
print(a,b)
结果:
你好 世界
a,b = {'汪峰':'北京北京','王菲':'天后'}
print(a,b)
结果:
汪峰 王菲

所以利用上面刚学的拆包的概念,我们循环字典时还可以这样获取字典的键,以及值:
for k,v in dic.items():
print('这是键',k)
print('这是值',v)
结果:
这是键 剑圣
这是值 易
这是键 哈啥给
这是值 剑豪
这是键 大宝剑
这是值 盖伦

for k,v in dic.items():
print('这是键',k)
print('这是值',v)
结果:
这是键 剑圣
这是值 易
这是键 哈啥给
这是值 剑豪
这是键 大宝剑
这是值 盖伦

4.1.5字典的嵌套
字典的嵌套是非常重要的知识点,这个必须要建立在熟练使用字典的增删改查的基础上,而且字典的嵌套才是咱们在工作中经常会遇到的字典,工作中遇到的字典不是简简单单一层,而就像是葱头一样,一层接一层,但一般都是很有规律的嵌套,那么接下来我们就学习一下字典的嵌套:
现在有如下字典,完成一下需求:
dic = {
'name':'汪峰',
'age':48,
'wife':[{'name':'国际章','age':38}],
'children':{'girl_first':'小苹果','girl_second':'小怡','girl_three':'顶顶'}
}
1. 获取汪峰的名字。
2.获取这个字典:{'name':'国际章','age':38}。
3. 获取汪峰妻子的名字。
4. 获取汪峰的第三个孩子名字。

dic = {
'name':'汪峰',
'age':48,
'wife':[{'name':'国际章','age':38}],
'children':{'girl_first':'小苹果','girl_second':'小怡','girl_three':'顶顶'}
}
1. 获取汪峰的名字。
2.获取这个字典:{'name':'国际章','age':38}。
3. 获取汪峰妻子的名字。
4. 获取汪峰的第三个孩子名字。

解题思路:
1.获取汪峰的名字。: 这个比较简单,汪峰就是dic的一个键对应的值,我们通过这个key就可以获取到汪峰这个值。
name = dic['name']
print(name)
name = dic['name']
print(name)
2. 获取这个字典{'name':'国际章','age':38}: 想要获取这个字典,先要看字典从属于谁?这个字典从属于一个列表,而这个列表是字典wife对应的键,所以咱们应该先通过wife获取到对应的这个列表,然后通过这个列表按照所以取值取到对应的这个字典。
l1 = dic['wife'] # 先获取到这个列表
di = l1[0] # 列表按照索引取值,这个字典是列表的第一个元素,所以通过索引获取到这个字典
print(di)
# 当然上面是分布获取的,我们还可以合并去写:
di = dic['wife'][0]
print(di)

l1 = dic['wife'] # 先获取到这个列表
di = l1[0] # 列表按照索引取值,这个字典是列表的第一个元素,所以通过索引获取到这个字典
print(di)
# 当然上面是分布获取的,我们还可以合并去写:
di = dic['wife'][0]
print(di)

3. 获取汪峰的妻子名字: 还是按照上一题的思路:想要获取汪峰妻子的名字:国际章,那么他是一个字典的键对应的值,所以我们通过'name'这个键就可以获取到对应的值,这个题的难点是获取到这个小字典,而上一个题我们已经获取了这个小字典,所以在上面的基础上再执行就可以了。
di = dic['wife'][0] # 这个是上一次题获取的小字典的代码
wife_name= di['name'] # 通过小字典然后再通过键就能获取到对应的值
print(wife_name)
# 当然咱们可以简化:
wife_name = dic['wife'][0]['name]
print(wife_name)

di = dic['wife'][0] # 这个是上一次题获取的小字典的代码
wife_name= di['name'] # 通过小字典然后再通过键就能获取到对应的值
print(wife_name)
# 当然咱们可以简化:
wife_name = dic['wife'][0]['name]
print(wife_name)

4. 获取汪峰的第三个孩子名字: 汪峰的孩子们是在一个字典中的,你要想获取汪峰的第三个孩子,你应该先获取到它从属于的这个字典,然后再通过这个字典获取第三个孩子的名字。
dic2 = dic['children'] # 先获取这个字典
name = dic2['girl_three'] # 在通过这个字典获取第三个孩子的名字
print(name)
# 当然你可以简化:
name = dic['children']['girl_three']
print(name)

dic2 = dic['children'] # 先获取这个字典
name = dic2['girl_three'] # 在通过这个字典获取第三个孩子的名字
print(name)
# 当然你可以简化:
name = dic['children']['girl_three']
print(name)

dic1 = {
'name':['alex',2,3,5],
'job':'teacher',
'oldboy':{'alex':['python1','python2',100]}
}
1,将name对应的列表追加⼀个元素’wusir’。
2,将name对应的列表中的alex⾸字⺟⼤写。
3,oldboy对应的字典加⼀个键值对’⽼男孩’,’linux’。
4,将oldboy对应的字典中的alex对应的列表中的python2删除
相关练习题

dic1 = {
'name':['alex',2,3,5],
'job':'teacher',
'oldboy':{'alex':['python1','python2',100]}
}
1,将name对应的列表追加⼀个元素’wusir’。
2,将name对应的列表中的alex⾸字⺟⼤写。
3,oldboy对应的字典加⼀个键值对’⽼男孩’,’linux’。
4,将oldboy对应的字典中的alex对应的列表中的python2删除








