

描述性统计分析(Description Statistics)是通过图表或数学方法,对数据资料进行整理、分析,并对数据的分布状态、数字特征和随机变量之间的关系进行估计和描述的方法。描述性统计分析分为集中趋势分析和离中趋势分析。
提到用python来进行描述性统计分析,第一反应就是用:dataframe.describe(), 我们不妨用一组数据来展示:
# 读取数据
df = pd.read\_csv('sanguo\_data.csv',header = 0,encoding="utf-8")
df.head()
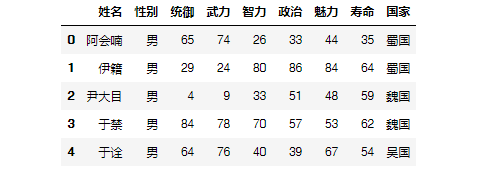
这是一组三国人物的数据,有姓名、性别、统御、武力等字段(数据下载地址见文末)。
下面我们用python当中的dataframe.describe()来进行描述性统计分析:
#描述性分析
df.describe()
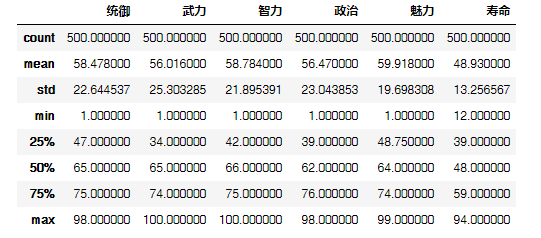
运行可得到上图,可以看到最大值、最小值、平均数、标准差、中位数等基本的描述性统计指标都有,但是为了更好深地掌握知识,下面还是继续用python挨个指标复习一下。
集中趋势分析
- 平均数
简单算数平均数,这里没什么好说的
加权平均数,应用最广泛。这里举个栗子:武力值高不代表带领军队时的战力,不然关羽岂不是无敌,所以这时候用统御能力加权平均更合适。
几何平均数,多用于流程转化中的平均,比如多步骤的转化率求平均值
data = df\['武力'\]
#简单算数平均数
np.average(data)
#加权平均数
np.average(data,weights=df\['统御'\])
#几何平均数
pow(np.prod(data),1/len(data))
- 众数
是一组数据中出现次数最多的数值,可能没有,也有可能有多个。
counts = np.bincount(data)
np.argmax(counts)
- 分位数
分位数是指用分割点将一个随机变量的概率分布范围分为几个具有相同概率的连续区间。
# 中位数
np.median(data)
# 四分位数
np.percentile(data, (25, 50, 75), interpolation='midpoint')
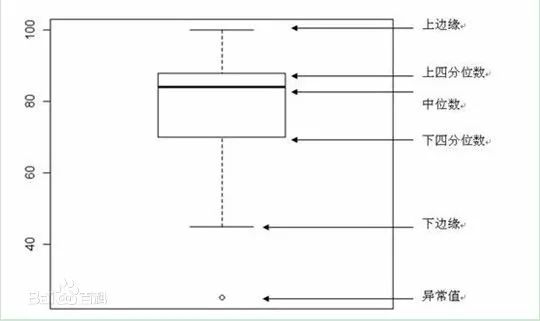
箱线图是分位数的直接应用:主要包含六个数据节点,将一组数据从大到小排列,分别计算出他的上边缘,上四分位数Q3,中位数,下四分位数Q1,下边缘,还有一个异常值。
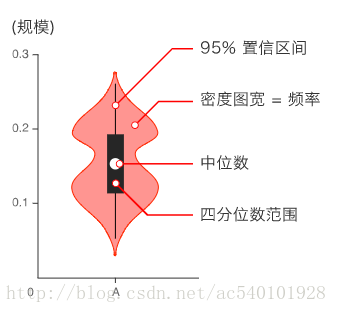
我平时喜欢用的小提琴图(violin plot)用于显示数据分布及其概率密度。它结合了箱形图和密度图的特征,主要用来显示数据的分布形状。中间的黑色粗条表示四分位数范围,从其延伸的幼细黑线代表 95% 置信区间,而白点则为中位数。
离中趋势分析
- 极差
极差又被称为全距,是指数据集合中最大值与最小值的差值
# 极差
np.max(df\['武力'\])-np.min(df\['武力'\])
- 方差、标准差
方差是度量随机变量和其数学期望(即均值)之间的偏离程度。
标准差:方差的开方
# 方差
np.var(df\['武力'\])
# 标准差
np.std(df\['武力'\])
- 平均差
各个变量值同平均数的离差绝对值的算术平均数。
- 异众比率
是总体中非众数次数与总体全部次数之比。
- 偏态系数
以平均值与中位数之差对标准差之比率来衡量偏斜的程度。偏态系数小于 0,因为平均数在众数之左,是一种左偏的分布,又称为负偏。偏态系数大于 0,因为均值在众数之右,是一种右偏的分布,又称为正偏。
- 峰态系数
是对数据分布平峰或尖峰程度的测度:峰态系数与众数概率的高低有直接关系,众数概率越高,峰态系数越大。
正态分布的峰态系数是 3,常常计算出来的峰态系数会跟 3 作比较,如果小于 3 则具有不足的峰度,如果大于 3 则具有过度的峰度。
#偏度、峰度
from scipy import stats
x = df\_wu\['武力'\]
skew = stats.skew(x)
kurtosis = stats.kurtosis(x)
实战演练
现在我们再将这组数据按国家区分,来看看描述性统计分析能得出什么样的结论?
df\_wei = df.loc\[(df\['国家'\] == '魏国')\]
df\_shu = df.loc\[(df\['国家'\] == '蜀国')\]
df\_wu = df.loc\[(df\['国家'\] == '吴国')\]
data = df\_wu\['武力'\]
plt.hist(data,20,normed=True,facecolor='g',alpha=0.9)
plt.show()
做出三国人物的武力值分布图,以及利用前文的python代码计算各种描述性统计分析指标,如下图所示:

从平均值看,蜀国武将的平均武力在三个国家之上
从标准差看,吴>蜀>魏,这说明吴国人物间武力差距更大一些,而魏国人物武力分布较为均匀。
从偏度上看:三国偏态系数均小于0,平均数在众数之左,是一种左偏的分布,又称为负偏。 从上面三个图中也可以看出:其中蜀国的武力分布众数偏在右侧更明显一点,长尾拖在左边。 从峰度上看:三国偏态系数均小于0,均是低峰态,相对来说蜀国人物武力分布较另外两国人物武将武力分布更窄一些。
PS:大家可能注意到求出的偏态系数为负数,这是因为在实际应用中,通常将峰度值做减3处理。
数据代码分享:
[1]点击左下角原文链接,直接进入知识星球(免费)原贴获取文中涉及的三国数据和ipynb格式的python代码。
[2]或者微信后台回复“统计分析”,也可同样获取。
参考资料:
[1]《数据茶水间》-木东居士
[2]《从零进阶!数据分析的统计基础》
[3]《深入浅出统计学》
本文转自 https://mp.weixin.qq.com/s/TGoL3ZNDlIMLxRWwf9ch3A,如有侵权,请联系删除。
本文转转自微信公众号凹凸数据原创https://mp.weixin.qq.com/s/TGoL3ZNDlIMLxRWwf9ch3A,可扫描二维码进行关注:
 如有侵权,请联系删除。
如有侵权,请联系删除。












