大家好,我是皮皮。
一、前言
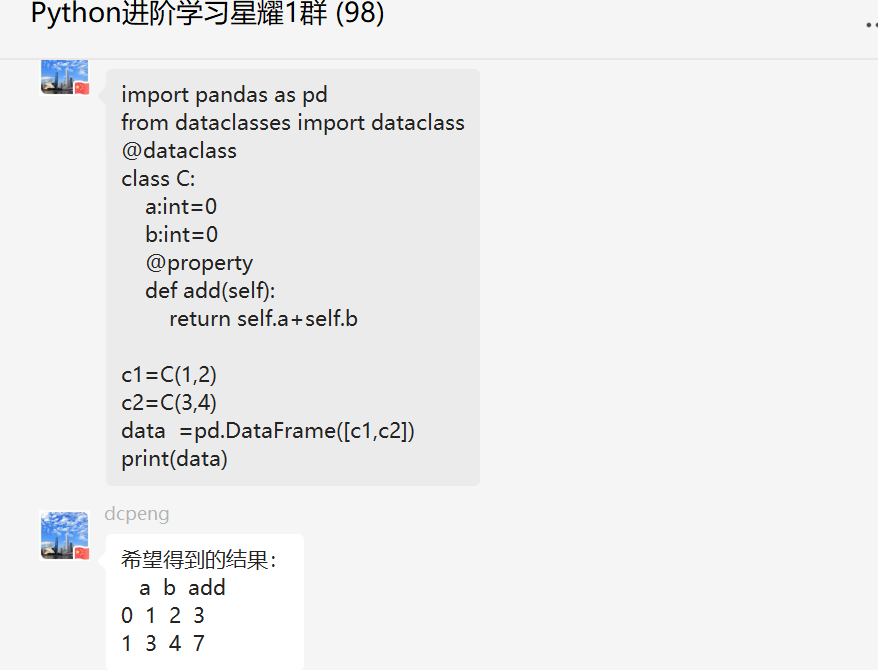
前几天在Python钻石交流群【静惜】问了一个Pandas处理的问题,提问截图如下:

数据截图如下所示:

后面找他拿了源数据,是一个Excel表格文件。
二、实现过程
这里【心田有垢生荒草】给了一个代码,如下所示:
df = pd.read_excel('【例2-1】饮料类型的频数分布表.xlsx')
df1 = df.groupby(['饮料类型','消费者性别'])['消费者性别'].count().rename('消费量').reset_index()
json_columns = df1.to_json(orient = "values",force_ascii=False)
json_columns
json_dict = df1.to_dict(orient = "split")
json_dict
运行之后,结果如下所示:

基本上都做出来了,不过还是不太符合预期。
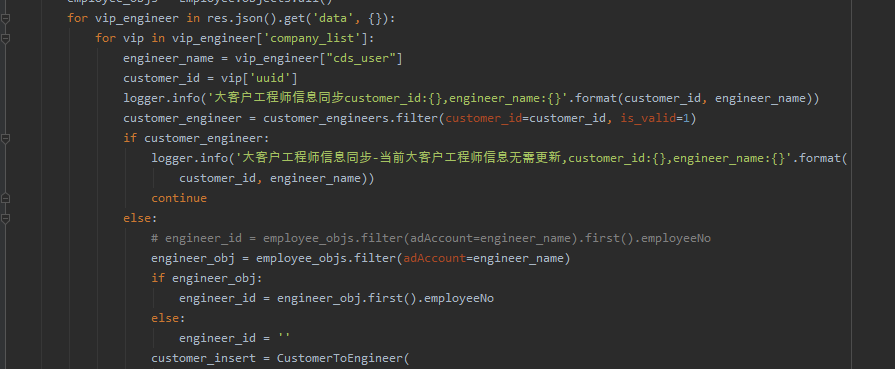
这里【猫药师Kelly】给了一份代码,可以满足粉丝需求,如下图所示:

确实太强了,没想到还可以这么做!

后来【人间欢喜】也提供了一个代码,如下所示:

也可以实现,方法还是很多的。
三、总结
大家好,我是皮皮。这篇文章主要盘点了一个Python自动化处理的问题,文中针对该问题,给出了具体的解析和代码实现,帮助粉丝顺利解决了问题。
最后感谢粉丝【静惜】提问,感谢【心田有垢生荒草】、【猫药师Kelly】、【人间欢喜】给出的思路和代码解析,感谢【dcpeng】等人参与学习交流。