
1. 基本概念
jvm 是可运行Java代码的假想计算机,包括一套字节码指令集、一组寄存器、一个栈、一个垃圾回收堆和一个存储方法域。
jvm 是运行在操作系统之上的,屏蔽了与具体操作系统平台相关的信息,使得Java程序只需生成在 jvm 上运行的字节码,就可以在多种平台上不加修改地运行。
Java 语言的一个非常重要的特点就是与平台的无关性(跨平台),其得益于 jvm,不是 Java 实现的跨平台,而是 jvm 的跨平台性,进而描述 Java 是跨平台的。
我们知道,每个平台的 api 肯定是不同的,就好比,android 实现动画绘制肯定跟 ios 实现动画绘制不同。jvm 通过 jit 即时编译器解释执行 Java 代码,最终得到相同的字节码,所以才有了经典的 "writ once,run anywhere"
通俗理解:jvm 运行在操作系统之上,其通过编译器解释执行 Java 代码得到相同的字节码,实现跨平台性,进而描述 Java 语言跨平台。
2. 运行过程
.java 源文件通过编译器(假装javac),能够产生相应的 .class 文件(字节码文件),
而字节码文件又通过 jvm 中的解释器,编译成计算机真正识别的机器码(二进制01)。
- java源文件 > 编译器 > 字节码文件
- 字节码文件 > 解释器 > 机器码
每一种平台的解释器是不同的,但是实现的虚拟机是相同的,这也就是为什么 Java 能够实现跨平台的原因,当一个程序从开始运行时,虚拟机就开始实例化了,多个程序启动,则存在多个虚拟机实例。程序退出或者关闭,则虚拟机实例消亡,多个虚拟机实例之间的数据不能共享。
通俗理解:java源文件通过编译器得到字节码文件,字节码再通过解释器获得计算机真正可识别的机器码。
3. 内存管理
对于 Java 程序员来说,在 jvm 自动内存管理机制帮助下,不需要在为每一个 new 操作去写配对的 delete/free 代码,正常情况下是不容易出现内存泄漏和内存溢出的问题。
jvm 在执行 Java 程序的过程中会把它所管理的内存划分为若干个不同的数据区域,如图所示。
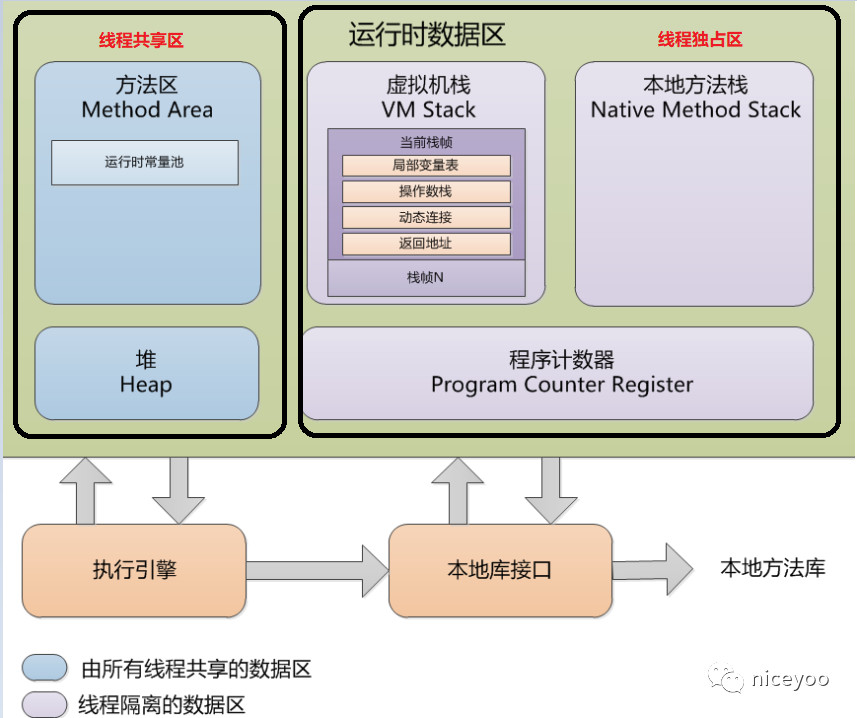
针对上图对运行时数据区域组成部分做简单描述。
1.程序计数器
用于记录当前线程所执行到的字节码的行号。
怎么理解?举个简单的例子:

每一个线程都是顺序执行单元,就如同上图标记的行号一样,是向下顺序指定的,而程序计数器,就是用于标记行号的,遇到 if/else 则跳过不执行的行号,比如第 16 行是跳过的。
2.java虚拟机栈
虚拟机栈是为虚拟机执行 java 方法服务的,在了解虚拟机栈之前我们先了解一下 _栈帧_与_局部变量表_:
栈帧:每个方法执行都会创建一个栈帧,伴随着方法从创建到执行完成。用于存储局部变量表,操作数栈,动态链接,方法出口等。下图为方法执行过程:
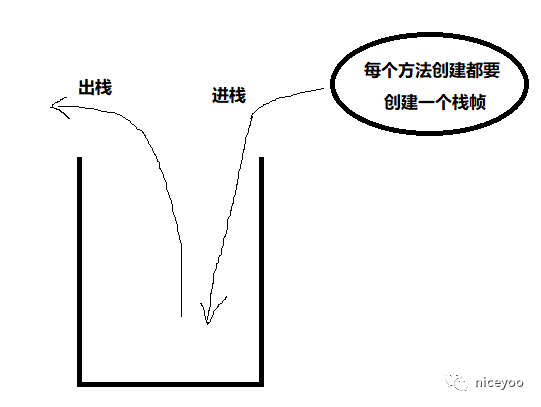
方法不停地调用,不停地进栈,如果栈内存满了,就会 Stack Overflow Error 或者 Out of Memory
局部变量表:
- 存放编译器可知的各种基本数据类型、引用类型。
- 局部变量表的内存空间在编译器完成分配,当进入一个方法时,这个方法需要帧分配多少内存是固定的,在方法运行期间是不会改变局部表量表的大小,局部变量表存放的是对象的引用。
在网上我们经常看到有人把 java 内存分为 堆内存 和 _栈内存_,这种分法是比较广义的,内存的实际划分是比较复杂的。这种划分方式的流行只能说大多数人关注的是:与对象内存分配关系最亲密的两块内存区域(栈堆)。其中 栈内存 就是上方的虚拟机栈,或者说是虚拟机栈中局部变量表部分。
3.本地方法栈
本地方法栈是为 native 方法服务的。
native方法:
- 简单地讲,一个 native 方法就是一个 Java 调用非 Java 代码的接口。
- 一个 native 方法是这样一个 Java 的方法:该方法的实现由非 Java 语言实现,比如 C。
这个特征并非 Java 所特有,很多其它的编程语言都有这一机制,比如在 C++ 中,你可以用extern "C"告知C++编译器去调用一个 C 的函数。
4.java堆
Java 堆是 jvm 所管理的内存中最大的一块,所有的对象实例以及数组都要在堆上分配。
因为分的蛋糕比较大,固然成为 gc(垃圾回收器)经常光顾的主要区域。
由于现在的收集器基本都采用分代收集算法,所以 Java 堆可以细分为:新生代、老年代、永久代(java8中移除了永久代),这一块后面会单独写一篇关于垃圾回收器的文章,暂时有个印象即可。
5.方法区
方法区与 java 堆一样,是各个线程共享的内存区域,用于存储已被虚拟机加载的类信息、常量、静态变量、即时编译器编译后的代码等数据。
尽管 jvm 规范把方法区描述为堆的一个逻辑部分,但是它却有一个别名叫非堆,目的区分堆。
4. 对象的创建
对象的创建过程:
- 给对象分配内存
- 线程安全性问题
- 初始化对象
- 执行构造方法
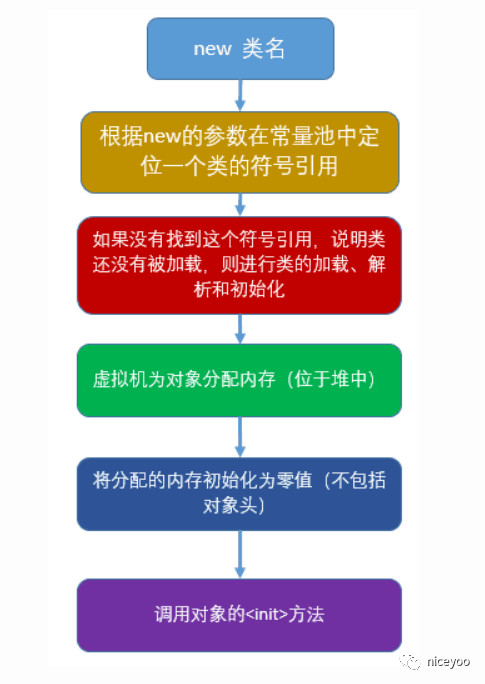
1.给对象分配内存[位于栈中]
对象的创建一般从 new 指令开始的,jvm 首先对符号引用进行解析,如果找不到对应的符号引用,那么这个类还没有被加载,因此jvm便会进行类加载过程(关于类加载后面单独文章讲解),符号引用解析完毕之后,jvm 会为对象在堆中分配内存。
2.线程安全性问题
描述一种场景:正在给 A 对象分配内存,指针还没来得及修改,对象 B 又同时使用了原来的指针来分配内存的情况。
两种解决方案:
- 对内存分配内存空间的动作进行同步处理。
- 把内存分配动作按照线程划分在不同的空间之中进行。
3.初始化对象
对象创建后通常有个默认值。
jvm 为对象分配完堆内存之后,jvm 会将该内存进行零值初始化,这也就解释了为什么 Java 的属性字段无需显示初始化就可以被使用,而方法的局部变量却必须要显示初始化后才可以访问。
4.执行构造方法
执行完上方三步,jvm 会调用对象的构造函数。
至此,一个对象就被创建完毕。
5. 最后总结
jvm 的学习是比较枯燥乏味的,基本都是一些概念性问题,上文对 jvm 的基本概念以及内存区域做了简单的介绍。
工欲善其事,必先利其器。尽管 jvm 的学习非常无聊,但是却非常重要,下面我用白话文根据自己的理解针对本文做一个总结。
上边有提到 "jvm 的跨平台性,实现了java语言的跨平台" ,何为跨平台?通俗理解就是: 一个操作系统下开发的应用,放到另一个操作系统下依然可以运行。举一个生动一点的例子,用 eclipse/idea 开发的 Java 程序,可以同时运行在 Linux、Windows 等操作系统上,即所谓的 "Write once, run anywhere(一次编写,到处运行)" 。
从广义的层次理解了 jvm 的跨平台性,接着是上文提到的 jvm 内存管理,jvm 有一套 自动内存管理机制,在该机制的帮助下,通常我们是不需要去关注对象的 内存分配以及释放的,然后这套内存管理机制,会把他所管理的内存划分为不同的运行时数据区域,而运行时数据区域由线程独立以及线程共享两部分组成。
说到线程,何为线程呢?说到线程又不得不提进程….(果然坑越描越大)
这里所说的线程是指程序执行过程中的一个线程实体,在讲程序计数器时有提到,每一个线程都是顺序执行单元,就好比一个简单的main方法,是按照从上到下的顺序执行的。线程之间又是有所区分的,比如虚拟机线程、gc线程、编译器线程等,jvm 允许一个应用并发执行多个线程,就是所谓的多线程。
关于线程、进程、多线程的关系。
我们将王小工作的车间理解为进程,而线程则理解为车间里的工人,一个车间里肯定有很多工人 ,他们协同完成一个任务,也就是多线程完成一个进程。
我们结合车间与工人,再来看看上边提到的 "线程独立" 与 "线程共享"。
线程共享:车间的空间是工人们共享的,比如许多房间是每个工人都可以进出的。这表示一个进程的内存空间是共享的,每个线程都可以使用这些共享内存。
线程独立:王小所在的车间,只有一个厕所,而厕所的空间最多只能容纳一个人,进入厕所后,是需要上锁的,这样别人才不能进来。里面有人的时候,其他人就不能进去,这代表一个线程使用某些共享内存时,其他线程必须等它结束,才能使用这一块内存。
了解了运行时数据区域划分的线程概念,接着就是内存的各个组成区域,主要了解到 java堆,堆是用来存放对象实例以及数组的。每当你 new 一个对象,都是要在堆上拉取一块内存区域的,通常一个程序要 new(实例化)很多对象,无形中带来了内存负担,所以就引出了 gc 垃圾回收的概念,我们可以将堆中的对象理解为 gc 的猎物,很显然,对于富的流油的堆来说,自然成了 gc 主要的光顾对象。在这个地方我们提到了 新生代、老年代、永久代的概念,下一篇单独讲解。
如果文章有错的地方欢迎指正,大家互相交流。习惯在微信看技术文章,想要获取更多的Java资源的同学,可以关注微信公众号:niceyoo











