
OCR是什么?
假设你想要数字化一本杂志的文章或印刷合同。你可能需要花时间重新输入,然后纠正错字。或者,你可以使用扫描仪(或数码相机)和光学字符识别软件只需要花费几分钟转换成数字格式的所有材料。

到底什么是OCR呢?
光学字符识别,简称OCR,是一种可以使你转换不同文档的技术,比如将扫描纸质文档,PDF文件或者数码相机拍摄的图片转换成可以编辑的文档。
假设你获得了一个纸质文件-比如,杂志、彩页或者你合作伙伴发给你的PDF合同。很明显,光是一台扫描仪是不足以让这些文档转变成可以编辑的文档,也就是Microsoft Word。扫描仪可以做的只是创建图片或者一张黑白或者彩色的图像文档。为了从扫描文档、PDF或者数码图片中提取文字和数据,你需要OCR软件识别图片上的信息,从单词到句子,然后变成整个可以编辑的文档。
OCR背后是什么技术?
人类识别物体的机制还需要继续探索,但是3个基本的原则已经被科学家所掌握,集成性(integrity), 有明确目的性(purposefulness)和适应性(adaptability)统称为 (IPA*)。这也是ABBYY FineReader 实现的技术核心所模仿和遵循的原则。

让我们来看一下FineReader OCR是如何识别一个文档的。首先,这个程序分析文档图片的结构。它将文档分成一些基本元素,比如文档块,表格,图片等。这些线分割成单词,再分割成字母。一旦这个字母已经被识别出来,这个程序将和一些模板图片进行对比。他将进行大量的逻辑分析这个字母是什么。基于这些逻辑,程序将分析单词和字母。进行完大量的可能性分析后,这个程序最后将判断并呈现出识别的文档。
另外,ABBYY FineReader 提供支持36种语言的字典。这将有助于在第二个层面分析文档的元素。在字典的支持下,可以进行更加精确分析和文档识别,降低将来识别结果的校验。
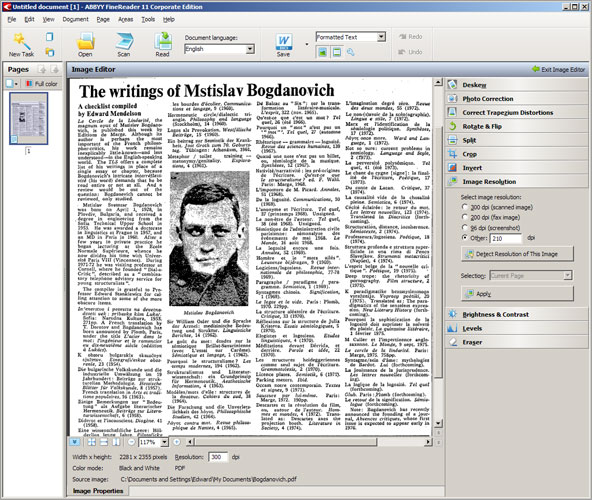
FineReader OCR的基本原理
最先进的识别系统,比如ABBYY FineReader OCR, 是模仿人工识别。在核心,这些系统遵循3个基本的原则:集成性(integrity), 有明确目的性(purposefulness)和适应性(adaptability)。实际的意思是说观察物体必须考虑到这个物体的内部相关性。目的性是指数据的表达都有一定目标性。适应性是指程序必须具有自学习能力。
每个人不需要成为OCR专家,并了解OCR内部的IPA。这些规则只是提供类最大的灵活性和智能性,并最大可能模板人工识别。

经过多年的研究,ABBYY可以将IPA原则运用到OCR产品中。
识别数码相片
数码相机拍摄的图片和扫描文档和PDF文档有所不同。他们常常有所扭曲,昏暗,不利于OCR正确识别文档。ABBYY FineReader 最新版本支持适应性识别,特别为处理数码图片而设计。它提供了一系列功能特性来提高图片质量,使你可以充分使用您的数码设备。
OCR将为你带来什么好处。
使用ABBYY FineReader,识别出来的文档就像是原始文档一样。先进的、强大的OCR软件将帮助你节省大量的时间和精力,使你免于创建、处理不同的文档。使用ABBYY FineReader,你可以扫描文档以备将来编辑、并与你的同事共享。你可以从书籍、杂志中抽取信息,并为你自己的研究提供资料和素材,而不需要重新打字输入。利用数码相机和OCR,你可以捕捉公告栏、海报和时间表上捕捉信息,满足你使用的需要。同时,你可以捕捉报纸和书籍信息,甚至在手边没有扫描仪的时候也可以完成捕捉。另外,你还可以使用OCR软件创建可搜索式的PDF文档。
从初始纸质文档、图片和PDF文件和数据转换的整个过程只需要一分钟,识别完的结果几乎和原始的几乎一样。
如何使用OCR软件?
使用ABBYY FineReader OCR非常容易,过程由3个步骤组成:打开或者扫描文档,识别,然后保存成你需要的格式(DOC, RTF, XLS, PDF, HTML, TXT 等等.) 或者直接输出数据到office应用,比如Microsoft Word, Excel or Adobe Acrobat。
另外,最新版本ABBYY FineReader支持自动任务模式,这将对您日常工作大有帮助。有了这个功能,识别任务将自动运行,而不需要人工干预。更有ABBYY FineReader mac版供免费下载!











