
因为工作原因,最近看了一下数据库的存储相关代码,并且对《PostgreSQL数据库内核分析》、Bean_lee的帖子进行了学习。现在记录一下,以备后用。其中后半部分基本是Bean_lee原文修改的。
首先要知道的是,数据库存储是以数据文件的方式进行存储,在data/base/子目录内能看到一些以数字命名的文件,诸如:16948、16948_fsm、16948_vm等,其中16948一般是对应表的oid,但当表的数据文件被完全重写等情况时,就不能一一对应了。
同样,还需要知道的便是block,指的是每次加载进内存的基本单位。一般来说,block是8192字节。当数据库需要加载数据到内存时,便是以block为单位将数据加载到内存,而数据文件是以page为单位,同样page也是8192字节。这主要为了提高数据库本身的效率。磁盘的I/O一直是数据库的瓶颈之一,这里正是为了能够更快的实现数据文件和内存的交互。
这里还需要说明的一个概念:元组,我在网上没有发现对他的官方定义,我只能按照我的理解对其说明一下,元组是数据库将每一行数据进行分装后称之为元组。
好了,下面主要对page进行分析了。下面以结构图进行分析。

每一个Page都是由上面这种格式组成的。
其中PageHeaderData的组成是这样的:

* pd_lsn - identifies xlog record for last change to this page.
* pd_checksum - page checksum, if set.
* pd_flags - flag bits.
* pd_lower - offset to start of free space.
* pd_upper - offset to end of free space.
* pd_special - offset to start of special space.
* pd_pagesize_version - size in bytes and page layout version number.
* pd_prune_xid - oldest XID among potentially prunable tuples on page.
* pd_linp[0] - beginning of line pointer array.
其中,项指针Linp的组成是:
typedef struct ItemIdData
{
unsigned lp_off:15, /* offset to tuple (from start of page) */
lp_flags:2, /* state of item pointer, see below */
lp_len:15; /* byte length of tuple */
} ItemIdData; /* 一共32bit,指向元组 */
介绍完Linp,下面便是元组Tuple了,比较难画,我使用的是同事画的结构图:

上面主要是对,Page的具体结构进行了介绍,现在记录的是他的行为。
项指针指向元组。元组则是封装好的数据。每一个Page都是8192字节(这里可以通过conf文件设置,具体设置看用户的需求,进行小数据量的频繁更新、删除和插入则建议用8192,若是需要进行大数据量的插入可以设置大一些),当插入数据时,首先需要进行申请page,然后进行初始化page。
void
PageInit(Page page, Size pageSize, Size specialSize)
{
PageHeader p = (PageHeader) page;
specialSize = MAXALIGN(specialSize);
Assert(pageSize == BLCKSZ);
Assert(pageSize > specialSize + SizeOfPageHeaderData);
/* Make sure all fields of page are zero, as well as unused space */
MemSet(p, 0, pageSize);
p->pd_flags = 0;
p->pd_lower = SizeOfPageHeaderData;
p->pd_upper = pageSize - specialSize;
p->pd_special = pageSize - specialSize;
PageSetPageSizeAndVersion(page, pageSize, PG_PAGE_LAYOUT_VERSION);
/* p->pd_prune_xid = InvalidTransactionId; done by above MemSet */
}
BLCKSZ默认是8192。
1、给special预留空间
specialSize = MAXALIGN(specialSize);
p->pd_special = pageSize - specialSize;
page header的成员变量pd_special相当于画了一条线,从pd_special这个位置到page的结尾,都是special的地盘,普通插入Tuple,都不许进入这个私有地盘。而且这个pd_special一旦初始化之后,这个值就不会动了。
2、设置pd_lower和pg_upper
当初始化的时候,pd_lower设置为SizeOfPageHeaderData,pd_upper设置为和pd_special一样。但是注意,这个lower和upper不是固定的,随着Tuple的不断插入,lower变大,而upper不断变小。当我们每插入一条Tuple,需要在当前的lower位置再分配一个Item,记录Tuple的长度,Tuple的起始位置offset,还有flag信息。这个Page Header中的pd_lower就是记录分配下一个Item的起始位置。所以如果不断插入,lower不断增加,每增加一条Tuple,就要分配一个Item(4个字节)。同样道理,Tuple的存放位置,根据upper提供的信息,可以找到将Tuple分配到何处比较合。分配之后,pd_upper就会减少,减少Tuple的长度(对齐也考虑进去)。
3、设置 page的size 和version
#define PageSetPageSizeAndVersion(page, size, version)
(
AssertMacro(((size) & 0xFF00) == (size)),
AssertMacro(((version) & 0x00FF) == (version)),
((PageHeader) (page))->pd_pagesize_version = (size) | (version)
)
这个不多说,基本就是将版本号和page的长度记录在16bit的结构里面。
下面我们比较刚初始化和插入一条记录之后的情形:


一个记录对应两个部分,就头部附近Item空间和真正记录信息的Tuple。Item记录的是Tuple在Page的offset,size等信息。
PageAddItem增加一个记录:
Page是用来存放Tuple的,增加一个Tuple删除一个Tuple都是Page份内的事情,我们首先看下Page如何增加一个Tuple:
function PageAddItem是完成这件事情。
OffsetNumber
PageAddItem(Page page,
Item item,
Size size,
OffsetNumber offsetNumber,
bool overwrite,
bool is_heap)
item是我的当前记录的指针,size记录记录的长度,(item,item+size)这部分地址是Tuple的信息。 Page表示从这个page中查找空间保存当前的Tuple。这我们很好理解,因为这是基本的要求:在当前页随便找个空间保存我的item。咱的要求比较简单,可是有些客户要求可就不简单了,比如客户要求,就要将我的记录拜放到page的第三个item,这就是比较坑爹的客户了。就像去饭馆吃饭,我到了饭馆,喊了一嗓子,小二,给哥随便找个8人桌,小二很happy,因为我的要求低。也有客官直接喊了一嗓子,小二,我要去三楼最好的那个雅间,如果有客人,让他给我腾地方,我们有8个人。得,小二就傻了眼,但是还得办不是。PageAddItem也是一样,offsetNumber这个如参表示,大爷我就要将记录存放在这个位置。overwrite则这个参数就更拽了,如果有记录放在我要的位置,让原来那条记录给大爷滚蛋,。如果overwrite =0 表示,大爷要的位置如果有人,原来位置的记录换个地方,给大爷我腾地方。OK,这几个参数是干啥的,我基本交代清楚了(Bean_lee这么写的很有意思,就拿过来用了)
因为Page Header的长度是固定,而紧跟其后的Item的长度也是固定的,而每增加一个Item,pd_lower就增加一个Item的长度,这样,根据pd_lower就可以算出当前的页面已经有几个Tuple了。
#define PageGetMaxOffsetNumber(page)
(((PageHeader) (page))->pd_lower <= SizeOfPageHeaderData ? 0 :
((((PageHeader) (page))->pd_lower - SizeOfPageHeaderData)
/ sizeof(ItemIdData)))
limit = OffsetNumberNext(PageGetMaxOffsetNumber(page));
这个limit记录的是当前记录数+1 ,用这个来判段新来的AddItem请求有没有指定既有的位置
if (OffsetNumberIsValid(offsetNumber)) //值定了记录的存储位置
{
if (overwrite) //原有的记录删除,属于要求改写
{
if (offsetNumber < limit)
{
itemId = PageGetItemId(phdr, offsetNumber);
if (ItemIdIsUsed(itemId) || ItemIdHasStorage(itemId))
{
elog(WARNING, "will not overwrite a used ItemId");
return InvalidOffsetNumber;
}
}
}
else //新增加的客户要求这个位置,需要将原来位于这个位置的记录迁移到其他位置。
{
if (offsetNumber < limit)
needshuffle = true; /* need to move existing linp's */
}
}
else //普通客户
{
}
上面分析了文艺青年式的AddItem,下面我们分析下普通青年的AddItem,普通青年要求低,随便找个地儿存放当年记录:
if (OffsetNumberIsValid(offsetNumber))
{
...
}
else
{
/* offsetNumber was not passed in, so find a free slot */
/* if no free slot, we'll put it at limit (1st open slot) */
if (PageHasFreeLinePointers(phdr))
{
/*
* Look for "recyclable" (unused) ItemId. We check for no storage
* as well, just to be paranoid --- unused items should never have
* storage.
*/
for (offsetNumber = 1; offsetNumber < limit; offsetNumber++)
{
itemId = PageGetItemId(phdr, offsetNumber);
if (!ItemIdIsUsed(itemId) && !ItemIdHasStorage(itemId))
break;
}
if (offsetNumber >= limit)
{
/* the hint is wrong, so reset it */
PageClearHasFreeLinePointers(phdr);
}
}
else
{
/* don't bother searching if hint says there's no free slot */
offsetNumber = limit;
}
}
比较容易想到的是offsetNumber = limit = 当前记录数 + 1,这个太顺理成章了,那个PageHasFreeLinePointers是搞什么飞机?我们看下:
#define PageHasFreeLinePointers(page)
(((PageHeader) (page))->pd_flags & PD_HAS_FREE_LINES)
这个标志是啥意思?看名字的意思是 表征是否有free line。我们会把一些Item状态置为LP_UNUSED,这时候,Item和它原来的Tuple就没有映射关系。这样原来对应Tuple,就成了垃圾。后面会有会PageRepairFragmentation清理这些空间,但是仍然不会删除这个LP_UNUSED状态的Item,只是打上一个标志,表示存在无主的Item,可以被复用。
if (offsetNumber == limit || needshuffle)
lower = phdr->pd_lower + sizeof(ItemIdData); //新增一个Item
else
lower = phdr->pd_lower;
alignedSize = MAXALIGN(size);
upper = (int) phdr->pd_upper - (int) alignedSize;
if (lower > upper)
return InvalidOffsetNumber;
/*
* OK to insert the item. First, shuffle the existing pointers if needed.
*/
itemId = PageGetItemId(phdr, offsetNumber);
if (needshuffle)
memmove(itemId + 1, itemId,
(limit - offsetNumber) * sizeof(ItemIdData));
/* set the item pointer */
ItemIdSetNormal(itemId, upper, size);
/* copy the item's data onto the page */
memcpy((char *) page + upper, item, size);
/* adjust page header */
phdr->pd_lower = (LocationIndex) lower;
phdr->pd_upper = (LocationIndex) upper;
return offsetNumber;
因为新增个Tuple,需要alignedSize存储这记录的Tuple部分,所以pd_upper - alignedSize作为新的pd_upper.
ItemIdSetNormal把Tuple的size,offset信息记录在Item中:
#define ItemIdSetNormal(itemId, off, len)
(
(itemId)->lp_flags = LP_NORMAL,
(itemId)->lp_off = (off), //记录offset, page + off = Tuple的起始位置
(itemId)->lp_len = (len) //记录Tuple的size 。 (page + off ,page + off + len)记录的是Tuple的信息
)
PageIndexTupleDelete-page删除一条记录
我们下面讲述删除一条记录:
void
PageIndexTupleDelete(Page page, OffsetNumber offnum)
offnum指示第几个记录,offnum是从1开始计数的,查找对应item 是offnum-1.
我们找到Item,就可以找到Tuple对应的offset和size:
tup = PageGetItemId(page, offnum);
Assert(ItemIdHasStorage(tup));
size = ItemIdGetLength(tup);
offset = ItemIdGetOffset(tup);
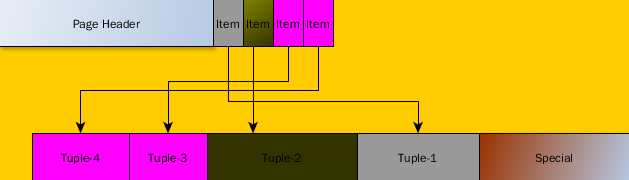
删除第二个记录之后,我们得到的Page布局如下:
我们可以看到,至少发生两次memmove
1 删除记录的Item后面的item都要往迁移,防止出现一个空洞
nbytes = phdr->pd_lower -
((char *) &phdr->pd_linp[offidx + 1] - (char *) phdr);
if (nbytes > 0)
memmove((char *) &(phdr->pd_linp[offidx]),
(char *) &(phdr->pd_linp[offidx + 1]),
nbytes);
2 删除记录的Tuple后面的Tuple,也要移动,否则,会出现Tuple-2对应的空洞。
addr = (char *) page + phdr->pd_upper;
if (offset > phdr->pd_upper)
memmove(addr + size, addr, (int) (offset - phdr->pd_upper));
除了移动内存,item对应的指针也要发生相应的改变:比如洋红色的两个item需要修改offset
if (!PageIsEmpty(page))
{
int i;
nline--; /* there's one less than when we started */
for (i = 1; i <= nline; i++)
{
ItemId ii = PageGetItemId(phdr, i);
Assert(ItemIdHasStorage(ii));
if (ItemIdGetOffset(ii) <= offset) //在前面Tuple2 前面的Tuple,发生了移位,所以对应Item的lp_off要修改。
ii->lp_off += size;
}
}
Page还剩多少剩余空间这是很重要的,这决定我们能否插入一条记录到当前Page。 原理就非常简单了,pd_upper - pd_lower ,就是剩余空间,但是,还需要存放Item,所以还需要减Item占据的空间,剩下的才能存放Tuple的空间:
Size
PageGetFreeSpace(Page page)
{
int space;
/*
* Use signed arithmetic here so that we behave sensibly if pd_lower >
* pd_upper.
*/
space = (int) ((PageHeader) page)->pd_upper -
(int) ((PageHeader) page)->pd_lower;
if (space < (int) sizeof(ItemIdData))
return 0;
space -= sizeof(ItemIdData);
return (Size) space;
}











