
(摘自:http://www.open-open.com/lib/view/open1400126457817.html)
单点的ActiveMQ作为企业应用无法满足高可用和集群的需求,所以ActiveMQ提供了master-slave、broker cluster等多种部署方式,但通过分析多种部署方式之后我认为需要将两种部署方式相结合才能满足我们公司分布式和高可用的需求,所以后面就重点将解如何将两种部署方式相结合。
1、Master-Slave部署方式
1)shared filesystem Master-Slave部署方式
主要是通过共享存储目录来实现master和slave的热备,所有的ActiveMQ应用都在不断地获取共享目录的控制权,哪个应用抢到了控制权,它就成为master。
多个共享存储目录的应用,谁先启动,谁就可以最早取得共享目录的控制权成为master,其他的应用就只能作为slave。

2)shared database Master-Slave方式
与shared filesystem方式类似,只是共享的存储介质由文件系统改成了数据库而已。
3)Replicated LevelDB Store方式
这种主备方式是ActiveMQ5.9以后才新增的特性,使用ZooKeeper协调选择一个node作为master。被选择的master broker node开启并接受客户端连接。
其他node转入slave模式,连接master并同步他们的存储状态。slave不接受客户端连接。所有的存储操作都将被复制到连接至Master的slaves。
如果master死了,得到了最新更新的slave被允许成为master。fialed node能够重新加入到网络中并连接master进入slave mode。所有需要同步的disk的消息操作都将等待存储状态被复制到其他法定节点的操作完成才能完成。所以,如果你配置了replicas=3,那么法定大小是(3/2)+1=2. Master将会存储并更新然后等待 (2-1)=1个slave存储和更新完成,才汇报success。至于为什么是2-1,熟悉Zookeeper的应该知道,有一个node要作为观擦者存在。
单一个新的master被选中,你需要至少保障一个法定node在线以能够找到拥有最新状态的node。这个node将会成为新的master。因此,推荐运行至少3个replica nodes,以防止一个node失败了,服务中断。

2、Broker-Cluster部署方式
前面的Master-Slave的方式虽然能解决多服务热备的高可用问题,但无法解决负载均衡和分布式的问题。Broker-Cluster的部署方式就可以解决负载均衡的问题。
Broker-Cluster部署方式中,各个broker通过网络互相连接,并共享queue。当broker-A上面指定的queue-A中接收到一个message处于pending状态,而此时没有consumer连接broker-A时。如果cluster中的broker-B上面由一个consumer在消费queue-A的消息,那么broker-B会先通过内部网络获取到broker-A上面的message,并通知自己的consumer来消费。
1)static Broker-Cluster部署
在activemq.xml文件中静态指定Broker需要建立桥连接的其他Broker:
1、 首先在Broker-A节点中添加networkConnector节点:
<networkConnector uri="static:(tcp:// 0.0.0.0:61617)"duplex="false"/>
2、 修改Broker-A节点中的服务提供端口为61616:
<transportConnectorname="openwire"uri="tcp://0.0.0.0:61616?maximumConnections=1000&wireFormat.maxFrameSize=104857600"/>
3、 在Broker-B节点中添加networkConnector节点:
<networkConnector uri="static:(tcp:// 0.0.0.0:61616)"duplex="false"/>
4、 修改Broker-A节点中的服务提供端口为61617:
<transportConnectorname="openwire"uri="tcp://0.0.0.0:61617?maximumConnections=1000&wireFormat.maxFrameSize=104857600"/>
5、分别启动Broker-A和Broker-B。
2)Dynamic Broker-Cluster部署
在activemq.xml文件中不直接指定Broker需要建立桥连接的其他Broker,由activemq在启动后动态查找:
1、 首先在Broker-A节点中添加networkConnector节点:
<networkConnectoruri="multicast://default"
dynamicOnly="true"
networkTTL="3"
prefetchSize="1"
decreaseNetworkConsumerPriority="true" />
2、修改Broker-A节点中的服务提供端口为61616:
<transportConnectorname="openwire"uri="tcp://0.0.0.0:61616? " discoveryUri="multicast://default"/>
3、在Broker-B节点中添加networkConnector节点:
<networkConnectoruri="multicast://default"
dynamicOnly="true"
networkTTL="3"
prefetchSize="1"
decreaseNetworkConsumerPriority="true" />
4、修改Broker-B节点中的服务提供端口为61617:
<transportConnectorname="openwire"uri="tcp://0.0.0.0:61617" discoveryUri="multicast://default"/>
5、启动Broker-A和Broker-B
2、Master-Slave与Broker-Cluster相结合的部署方式
可以看到Master-Slave的部署方式虽然解决了高可用的问题,但不支持负载均衡,Broker-Cluster解决了负载均衡,但当其中一个Broker突然宕掉的话,那么存在于该Broker上处于Pending状态的message将会丢失,无法达到高可用的目的。
由于目前ActiveMQ官网上并没有一个明确的将两种部署方式相结合的部署方案,所以我尝试者把两者结合起来部署:
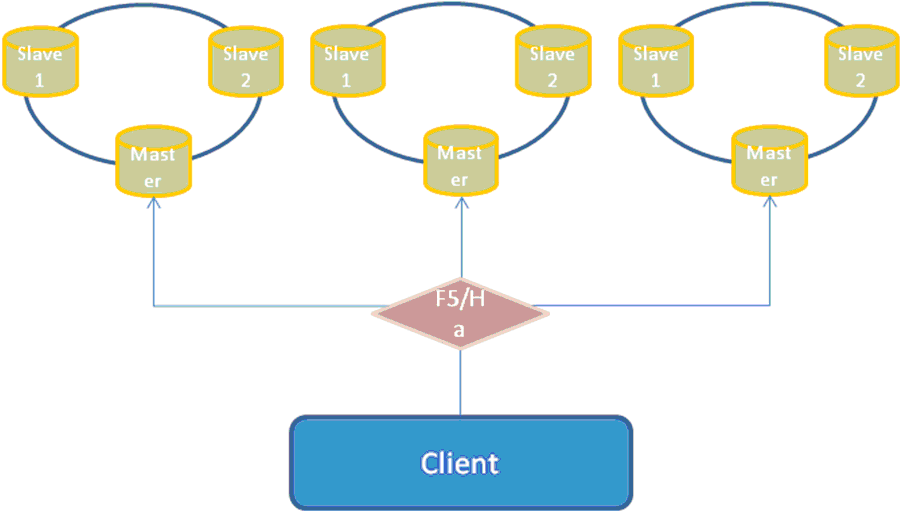
1、部署的配置修改
这里以Broker-A + Broker-B建立cluster,Broker-C作为Broker-B的slave为例:
1)首先在Broker-A节点中添加networkConnector节点:
2)修改Broker-A节点中的服务提供端口为61616:
<transportConnectorname="openwire"uri="tcp://0.0.0.0:61616?maximumConnections=1000&wireFormat.maxFrameSize=104857600"/>
3)在Broker-B节点中添加networkConnector节点:
<networkConnector uri="static:(tcp:// 0.0.0.0:61616)"duplex="false"/>
4)修改Broker-B节点中的服务提供端口为61617:
<transportConnectorname="openwire"uri="tcp://0.0.0.0:61617?maximumConnections=1000&wireFormat.maxFrameSize=104857600"/>
5)修改Broker-B节点中的持久化方式:
6)在Broker-C节点中添加networkConnector节点:
<networkConnector uri="static:(tcp:// 0.0.0.0:61616)"duplex="false"/>
7)修改Broker-C节点中的服务提供端口为61618:
<transportConnectorname="openwire"uri="tcp://0.0.0.0:61618?maximumConnections=1000&wireFormat.maxFrameSize=104857600"/>
8)修改Broker-B节点中的持久化方式:
9)分别启动broker-A、broker-B、broker-C,因为是broker-B先启动,所以“/localhost/kahadb”目录被lock住,broker-C将一直处于挂起状态,当人为停掉broker-B之后,broker-C将获取目录“/localhost/kahadb”的控制权,重新与broker-A组成cluster提供服务。











