
1. 事务
下面是摘自《Principles of Distributed Database Systems, 3rd Edition》中关于事务的一段描述,讲述了事务实现所依赖的组件:
事务是对数据库进行一致、可靠访问的基本单元,作为一个比较大的原子操作,负责将数据库从一个状态转移到另一个状态。为了满足一致性,需要对数据完整性限制进行定义,并且需要并发控制算法来协调多个事务的执行。并发控制也会处理隔离性的问题,事务的持久性和原子性需要可靠性的支持。持久性是由不同的提交协议和提交管理方法实现的;另外为了满足原子性,还需要开发恰当的恢复协议。
事务需要满足ACID属性,即:原子性、一致性、隔离性、持久性。本篇主要分析隔离性的实现,对其他三个属性仅略作说明。
原子性:原子性指一个事务内部对数据的所有操作要么同时生效,要么同时取消,不能存在部分生效的情况。原子性是事务最重要的属性。yugabyte的单行事务的原子性直接交给DocDB来维护,分布式事务的原子性则通过分布式事务管理程序来控制(pggate::PgTxnManager),通过类似两阶段提交(2PC)协议的方式来实现。
一致性:一致性主要是针对数据完整性约束层面的问题,比如一个操作完成之后需要满足外键完整性约束,或者更具体的,银行的两个账号转账需要满足转账前后总金额不变的约束等。目前对该部分内容尚未展开了解。
隔离性:主要是针对多个事务之间并发执行时可能出现的脏读、幻读、不可重复读等问题提出解决。隔离性的解决在一定层面上依赖事务的原子性。本章接下来主要解释yugabyte的隔离性实现。
持久性:主要是数据持久化层面的问题,事务提交后,数据库需要保证数据不能丢失、损坏。
2. 隔离级别
2.1 隔离级别的详细解释
隔离级别的定义是从数据库并发访问所出现问题引起的,下面是来自postgres针对隔离级别的解释说明:
- dirty read:一个事务会读到另外一个事务尚未提交的更新
- nonrepeatable read:一个事务在重新读取上次读的数据时,发现数据发生了变化(被其他commited事务给改了)
- phantom read:一个事务根据相同条件执行两次查询,查出来的数据的条数发生了变化(其他commited事务添加的)
- serialization anomaly:一组事务并发执行和按照不同顺序逐一执行,最终的结果不同。
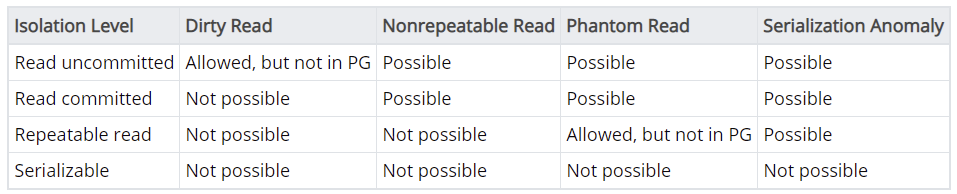
下表列出了每种隔离级别的含义,主要是描述该级别语义下,上述问题是否允许出现:
2.2 yugabyte支持两种隔离级别
下面解释了这两种隔离级别通常的实现手段。
snapshot isolation
- MVCC和锁都是SI的重要实现手段,当然也存在无锁的SI实现。
- mvcc:通过版本号来实现快照。
- 锁:通过锁解决write-write冲突。这里有悲观和乐观两种处理冲突的方式。
- 乐观锁:First-committer-wins,在commit阶段检查冲突。
- 悲观锁:First-write-wins,在write开始前检查冲突。
serializable
- S2PL:Strict Two-Phase Locking可以实现完全的串行化隔离,但是并发事务处理能力有限。
- SSI:Serializable Snapshot Isolation,是基于SI改进达到Serializable级别的隔离性。SSI保留了SI的很多优点,特别是读不阻塞任何操作,写不会阻塞读。事务依然在快照中运行,但增加了对事务间读写冲突的监控用于识别事务图(transaction graph)中的危险结构。当一组并发事务可能产生异常现象(anomaly),系统将通过回滚其中某些事务进行干预以消除anomaly发生的可能。这个过程虽然会导致某些事务的错误回滚(不会导致anomaly的事务被误杀),但可以确保消除anomaly。 从理论模型看,SSI性能接近SI,远远好于S2PL。
2.3 关于 repeatable read和 snapshot isolation
大多数情况下,都将这两种隔离级别归类为同一种隔离级别,但是两种隔离级别还是有细微差别。不过目前主流的数据库都采用SI,下面是两种隔离级别分别存在的问题。
repeatable read
这种隔离级别的实现方式是通过锁来实现的。当T1要按照某个条件查询数据时,如果查出了10行,就会对这10行数据加锁。后来的事务如果想改这10行数据,就会申请锁失败,因此T1再次读这10行数据时,内容不会发生变化,这就是repeatable read语义。
但是如果另外一个事务T2插入了一行新的数据,这行数据满足T1的过滤条件,这行数据在T1执行时是无法加锁的(因为还没有这行数据),T2提交之后,T1如果再次执行同样的查询,会查出11行数据,这就是幻读问题。
snapshot isolation
SI没有幻读问题。SI隔离级别通过快照方式进行数据隔离,因此对于上面的例子,T1执行时的快照不会受T2的影响,T2插入的数据在T1的生命周期中是不会被查询到的,因此SI隔离级别没有幻读问题。
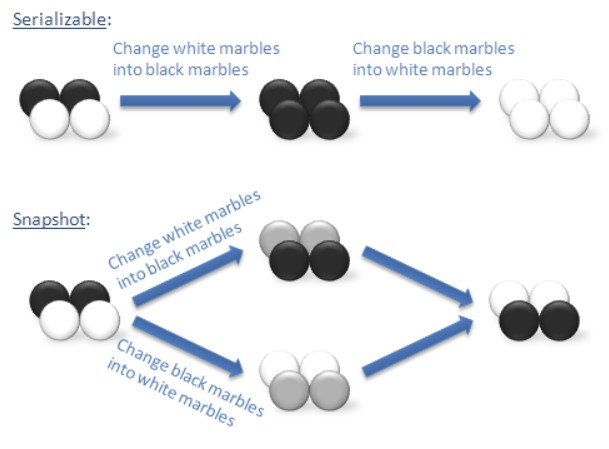
但是SI有Write Skew问题,关于Write Skew问题的例子如下图,两个事务:T1要把所有的白球染成黑色,T2要把所有的黑球染成白色。如果是serializable隔离级别,则要么最终全为白色,要么最终全为黑色,根据事务执行的先后顺序而定;如果是SI隔离级别,T1和T2基于同一个快照来执行自己的事务,由于两个事务修改的数据不同,所以两个事务不会产生冲突,会分别成功,导致最终的结果与期望不同(T1期望全黑,T2期望全白)。也就是说SI隔离级别下,两个快照会产生遮挡效果。
而repeatable read反而没有Write Skew问题,因为T1提交前,为了保证repeatable read的语义,是会通过读锁的约束,不允许T2修改数据库中已有球的颜色的。如果在SI上通过锁来解决Write Skew的问题,会导致纯读事务堵塞写事务,丧失了SI的读不堵塞写的优势。
上述例子转换成一个可验证性较强的SQL示例如下:
T1: blacknum = select count(*) from balls where color=black;
T1: if blacknum > 0 update balls set color=black where color=white;
T2: whitenum = select count(*) from balls where color= white ;
T2: if whitenum > 0 update balls set color=black where color=black;
T1: commit;
T2: commit;另外一个在yugabyte上测试过的例子:
yugabyte=# select * from users;
username | password | age
-----------+----------+-----
zhangsan3 | 111111 | 12
zhangsan1 | 111111 | 11
/* SI 级别测试 */
T1: begin;
T1: select count(*) from users where age = 12;
T1: update users set age=12 where age=11;
T2: begin;
T2: select count(*) from users where age = 11;
T2: update users set age=11 where age =12;
T1: commit;
T2: commit;
yugabyte=# select * from users;
username | password | age
-----------+----------+-----
zhangsan3 | 111111 | 11
zhangsan1 | 111111 | 12
/* serializable 级别测试 */
T1: begin; set transaction isolation level serializable;
T1: select count(*) from users where age = 12;
T1: update users set age=12 where age=11;
T2: begin; set transaction isolation level serializable;
T2: select count(*) from users where age = 11;
T2: update users set age=11 where age =12;
T1: commit;
T2: commit; ERROR: Error during commit: Operation expired: Transaction expired or aborted by a conflict: 40001
yugabyte=# select * from users;
username | password | age
-----------+----------+-----
zhangsan3 | 111111 | 12
zhangsan1 | 111111 | 123. 并发控制
并发控制是实现隔离级别的手段。比如要实现serializable隔离级别,并发控制算法就需要将所有并发事务严格的排序,然后串行调度执行。
3.1 2PL并发控制算法
两阶段提交并发控制已经在理论上证明是可以实现serializable隔离级别的并发控制算法。但是2PL有2个比较典型的问题:
- 实现困难 2PL的锁管理分两个阶段:申请阶段和释放阶段,因此才称做2PL。2PL要求一个事务的控制流程中,锁的释放必须在所有需要的锁都申请完之后。这对LockManager的实现提出了很高的要求,如何识别出一个事务的锁已经全部申请完了,从而尽早的释放锁。
- 事务的吞吐能力低 锁的方式实现事务并发控制,会导致事务间的冲突增加。只有read-read事务不冲突。
3.2 基于时间排序的并发控制算法(tocc)
这里之所以排序,主要是要实现serializable隔离级别。这种算法处理冲突的方式是给失败的事务分配一个新的时间戳,然后重启该事务,因此TOCC算法不存在死锁场景,代价是事务会重启很多次。
基于时间的并发控制算法中,时间戳的生成是最核心的工作。要实现分布式的全局唯一单调递增的时间戳是非常困难的工作,目前没有这方面的解决方案。因此目前的时间戳生成都是每个节点生成自己的时间戳,这带来的问题是节点间的时间戳可能不一致,某些节点分配的时间戳落后于其他节点,这会导致由该节点生成的事务通常会被拒绝然后重启。
为了尽量让节点间的时间戳保持同步,一个优化方式是节点间通过rpc来互相更新时间戳,两两之间选大的那个时间戳。
改进:TO最大的问题是会导致事务过多的重启,一种改进方式是调度器对要执行的事务进行缓存,而不是立即执行,直到调度器确认不会接受到时间戳更小的请求,此时再对事务进行排序执行。这样会在一定程度上缓解事务冲突的概率(时间戳小的会被先执行),从而减少事务重启的概率。不过缓存的方式可能引入死锁。
3.3 多版本TO并发控制算法(mvtocc)
多版本TO是另外一种用来避免重启事务的算法。基本的思想是:更新操作不修改数据库,而是创建一个新版本;每个版本都标记了与该版本相关的事务的时间戳信息(可能包含事务的start和commit时间戳)。
事务管理程序为每个事务分配一个时间戳,事务的读操作会被转换为对某个版本的读(根据事务的当前时间戳来确定)。对于写操作,只有一种情况会被拒绝:已经存在一个时间戳更大(意味着更晚到来,也就是更新)的事务在目标数据上进行读,这种情况才会拒绝这个时间戳较老的事务的执行。
3.4 多版本并发控制(mvcc)
mvcc不对事务进行严格排序执行,此种并发控制通常用于实现snapshot isolation级别。SI是目前商业数据库采用比较多的隔离级别。SI相对serializable,存在一个问题:Write Skew;在大多数场景下SI已经足够好。
4. 乐观悲观
这是针对并发控制算法所采取的机制的一种表述,主要是从性能角度考虑问题。当我们假设事务之间的冲突时比较频繁的时候,通常会采取悲观算法;反之会采取乐观算法。
悲观算法不允许两个事务对同一个数据项进行冲突访问,因此悲观算法的执行步骤如下:
有效性验证 -> 读 -> 计算 -> 写
乐观算法将有效性验证移到写之前执行:
读 -> 计算 -> 有效性验证 -> 写
乐观算法不会堵塞事务的执行,因此具有更高的并发能力。但是如果并发事务之间冲突比较多,可能会导致事务发生较多的重启,从而影响性能。乐观算法适合冲突较少发生的并发场景。
一种实现乐观锁的方式是在事务有效性验证的时候分配时间戳,这样的分配方式产生的结果就是哪个事务先commit,哪个事务会获得较早的时间戳;对于乐观锁并发控制来说,过早分配时间戳反而会导致不必要的冲突判定发生。
5. 形式化证明
对于并发控制实现的有效性,通常都有比较严格的形式化证明。这里没有深入了解。
6. yugabyte的隔离级别实现机制
yugabyte的隔离级别是基于mvcc+锁类组合实现的(当然从更高的层面来看待这个问题的话,也可以认为锁是实现mvcc的一部分,这里分成两部分来看待有助于更清楚的理解),这里具体解释mvcc和锁在yugabyte的隔离级别实现中分别解决什么问题:
mvcc
mvcc主要是解决并发访问问题。传统的基于锁的并发访问控制性能比较差,原因是传统的读锁会堵塞所有的写操作,只有读-读操作之间不会堵塞。mvcc的提出专门解决这个问题,用户的读操作是对特定版本的数据的访问,写操作不会修改该版本的数据,因此不会堵塞写。另外事务的原子性要求在一个事务内提交的所有数据的版本号必须相同,这保证了读操作不会读取到事务执行一半后的结果。
如果系统能够保证一个事务在开始阶段获取的数据库视图,在整个事务执行过程中保持不变(除了事务自己产生的变更),那么系统就完成了多版本(mv)这一层面的工作。但是只有多版本还不能完全解决问题,原因是当多个用户基于同一个版本的数据进行修改时,还是会有冲突产生的,解决并发写冲突问题还是需要锁的参与(或者其他无锁数据结构)。
锁
当冲突发生时,有很多识别冲突的机制。加锁是用来规避冲突的一种方式,实现起来比较简单直观。比如T1修改row1的column1的值时,会加锁;此时T2如果想做同样的操作通过检查锁的存在与否就可以提前检测到冲突。
另外,yugabyte的不同隔离级别的控制也是通过锁来实现的。yugabyte定义了非常细粒度的锁类型,不同隔离级别根据其语义要求,在数据访问时加不同的锁。比如:两个SI级别的写锁在语义上是冲突的,即:在SI隔离级别下,两个事务对同一个对象申请read-for-update的写锁是不被支持的,从而不允许此类事务并发执行(或者在申请时不做检查,最终提交时检测冲突时让一个失败,根据悲观还是乐观控制方法不同而不同)。而对于serializable隔离级别的写锁,语义上是不冲突的,由于在该隔离级别下事务是串行执行,多个事务同时更新同一个目标数据是被允许并发执行的,最终的结果是latest hybrid timestamp wins。值得指出的是,yugabyte的SI级别的纯写锁(区别于read-for-update锁)与serializable隔离基本的写锁采用的是同一种锁: strong serializable write lock 。关于锁的更具体的定义接下来会详细讲解。
对于冲突事务的处理,如果是在commit阶段检查冲突(乐观锁),通常的处理方式是First-Committer-Wins(FCW),后提交的直接失败,从而规避Lost Update问题;如果是在事务开始阶段检查冲突(悲观锁),则通常采用 First-write-wins(FWW)机制,后启动的事务直接失败。 yugabyte没有采用FWW,而是采用优先级的方式,优先级高的事务可以继续执行,优先级低的直接失败。yugabyte的优先级分配是随机数,两个事务的优先级高低是随机的。不过悲观锁和乐观锁的优先级处于不同的区间,悲观锁的优先级区间的所有值都高于乐观锁。因此一个乐观锁事务如果与一个悲观锁事务冲突,则乐观锁的事务一定会被取消。
总结:以上就是yugabyte隔离级别实现的全部考虑,剩下的就是基于这些考虑的具体实现。
6.1 yugabyte的mvcc实现
数据表示
DocDB的数据在磁盘上是以Tablet为单位管理的,每个Tablet对应一个rocksdb文件数据库实例。 rocksdb是一个kv系统,对于一个特定的Key-Value对,yugabyte通过将事务的时间戳编码到Key中来标记数据的版本号。
版本管理
yugabyte事务中的数据访问操作最终都会转换成对一个或多个Tablet的operation,DocDB接收到的每个请求都是独立到某个Tablet的,不存着一个请求操作多个Tablet的情况,因此一个事务如果需要访问(修改)多个Tablet的数据,在YQL层面会转换成多个DocDB的rpc请求,而多个Tablet是可能分布在不同节点上的,这里就需要YQL通过分布式事务的方式来管理事务,关于分布式事务的实现这里不展开讨论,有专门的一篇文章来说明。这里主要是为了说明一点:到达DocDB的请求一定是具体到某个Tablet了,所以DocDB的版本管理也是在Tablet内部完成的,不是全局管理。
DocDB通过 operation来抽象所有对Tablet的写操作,operation可以看做是DocDB内部的事务。 每个Tablet内部都有一个MvccManager,MvccManager主要负责时间戳管理,他提供如下特性:
- 提供接口(AddPending),为operation分配混合时间戳(LEADER端),并将该时间戳添加到内部的队列中;
- 保证后添加的operation的时间戳一定大于前面所有事务的时间戳;
- 提供接口(SafeTime),获取一个最大的时间戳,并确保读操作使用该时间戳读数据是安全的;(即:该时间戳前的所有数据都已经replicated了)
- 提供接口(Replicated),要求所有完成replicate的operation都需要调用该接口,将入队的时间戳出队。该接口检查replicated operation的顺序,要求operation必须按照添加的顺序被 replicated,但执行顺序的保证不在这里,这里只做事后检查,相当于一个Assert断言;
- 提供接口(Aborted),要求所有aborted的operation要调用该接口,将入队的时间戳出队。
6.2 yugabyte的锁定义和实现
为了支持SNAPSHOT和SERIALIZABLE两种隔离级别,yugabyte对锁进行了如下划分 :
- Snapshot isolation write lock: SI隔离级别的事务会在其要修改的value上加该种锁;
- Serializable read lock:Serializable隔离级别的事务会在执行read-modify-write类型的操作时,对要read的对象加该种锁;
- Serializable write lock: Serializable隔离级别的事务会在其要修改的value上加该种锁;
可以看到SI read并不加锁,因此SI隔离级别的read不会堵塞任何其他事务。 下面是这三种锁的冲突矩阵:

Fine grained locking:
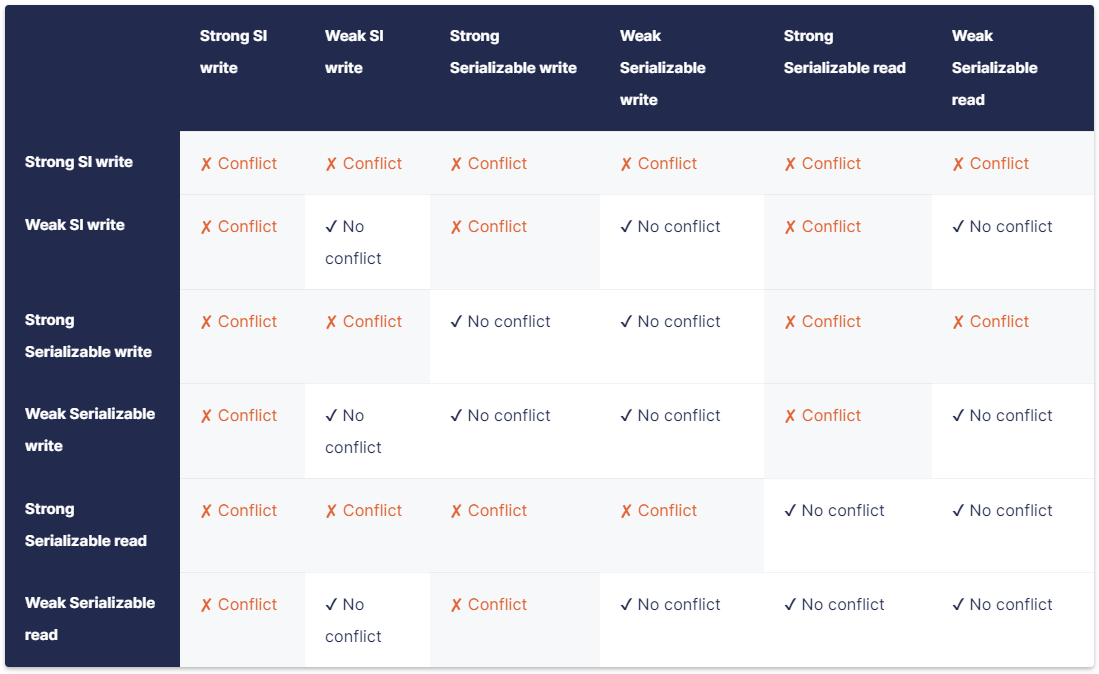
为了在更细粒度上减少锁的冲突,yugabyte按照数据读写的特点对锁进行了更近一步的划分,比如当修改一行中的某个列的value时,在行上加WeakLock,在要修改的列上加StrongLock;这样当另一个事务修改的是同一行的另一个列的value时,WeakLock之间不冲突, StrongLock也不冲突(因为锁的是不同对象), 所以这个事务可以并发执行,下面是更细粒度的锁冲突矩阵:
SharedLockManager
SharedLockManager实现了DocDB的fine-grained locking,每个Tablet维护一个 SharedLockManager实例,负责当前Tablet的锁控制。
yugabyte的锁类型定义:
YB_DEFINE_ENUM(IntentType,
((kWeakRead, kWeakIntentFlag | kReadIntentFlag))
((kWeakWrite, kWeakIntentFlag | kWriteIntentFlag))
((kStrongRead, kStrongIntentFlag | kReadIntentFlag))
((kStrongWrite, kStrongIntentFlag | kWriteIntentFlag))
);7. yugabyte并发控制工作流程
本节将详细分析事务的执行流程中涉及并发控制部分的工作机制,在这个流程分析过程中,我们将重点关注如下一些问题:
- mvcc和锁分别是如何在其中参与工作的
- 分布式事务的时间戳是如何实现单调递增的
- 分布式事务、单行事务在不同隔离级别下是如何实现并发控制的
- 基于锁的冲突检查机制是否需要考虑多版本的问题
- Lost Update、Ditry Read、Unrepeatable Read、Phantom Read等问题是如何解决的
7.1 相关类及扮演的角色
Operation
Operation是对写操作的事务具体操作的抽象,根据操作类型不同又派生出具体的Operation对象,如:
- WriteOperation:所有的写操作都在这里封装。
- UpdateTxnOperation:所有对status tablet的写操作都在这里封装。
Operation主要封装了如下接口:
- Prepare():operation的prepare阶段,与2PC的prepare不同,这里不进行任何数据操作,只做一些不涉及状态修改的准备工作。
- Start():tablet LEADER 作为事务的最开始的启动者,会在Start阶段为事务申请hybrid_time. FOLLOWER则是从LEADER的commit消息中获取该时间戳,因此Start阶段不会重新获取。
- Replicated():raft执行完数据复制后,会通过OperationDriver调用该接口,执行数据落盘操作。
- Aborted():事务失败会调用该接口。
OperationDriver
OperationDriver是对一个事务执行流程的抽象,所有事务的执行都由OperationDriver来管理,事务的执行流程抽象步骤:
- Init() :事务开始前会先创建一个OperationDriver对象来管理该事务的执行流程。
- ExecuteAsync():将OperationDriver提交到Preparer线程并立即返回,后续的执行由Preparer线程控制。
- PrepareAndStartTask():调用Prepare() and Start()。
- ReplicationFinished():raft完成复制后调用改回调函数,该回调函数是在Init阶段赋值给raft的。
- ApplyOperation => op->Replicated() => op->DoReplicated():将数据写到rocksdb中。
HybridTime
用来多版本控制的混合时间戳实现。
MvccManager
MvccManager负责维护每个tablet的mvcc控制流程。MvccManager维护了一个deque队列,用来跟踪所有operation的时间戳, MvccManager要求所有operation的 replicated顺序必须与该operation的时间戳的入队顺序保持一致。也就是对同一个tablet上的所有的operation必须按照时间戳申请的先后顺序完成。
Tablet
用户的一个表中的数据会按partition进行分区管理,每个分区在yugabyte中称作一个Tablet,raft复制是以tablet为单位管理的。 每个tablet维护自己的MvccManager实例,用以管理当前tablet的混合时间戳分配。
SharedLockManager
并发控制的锁实现。
TransactionCoordinator
负责分布式事务状态管理,即:status tablet的读写。同时协调TransactionParticipant完成数据最终写入到normal_db
TransactionParticipant
负责处理APPLYING和CLEANUP请求,这两个请求一个是commit成功后将数据从intent_db写入到normal_db,完成最终的数据提交;另一个是对abort的事务进行rollback操作,清理垃圾数据(从intent_db中删除)。
7.2 并发控制执行流程
7.2.1 TakeTransaction
该阶段是申请事务,会分别在client端和server端创建YBTransaction实例(metadata相同)。
7.2.2 TransactionStatus::CREATED
心跳信息,TakeTransaction之后会立即执行。通知status tablet更新状态,并维护心跳。
7.2.3 doc-op执行(通过PgDml为pg封装接口)
这一步骤是进行数据的读写,client端构造doc operation,通过rpc发送给DocDB(TabletService)。事务的隔离级别和锁的控制都在这里处理。
申请内存锁阶段(内存锁只在tablet leader上持有)
这里针对要修改的目标对象申请锁的类型进行总结(其父路径全部申请相应的weak锁): 1)如果是Serializable,读操作走写流程,会申请StrongRead锁 2)如果是snapshot isolation,读操作不申请任何锁。 3)如果是Serializable,UpSert操作申请StrongWrite锁,其他写操 作 (insert/update/delete)申请StrongRead + StrongWrite锁 4)如果是snapshot isolation,申请 StrongRead + StrongWrite锁 5)所有父路径都申请对应的weak锁。 目前看来,yugabyte把不同隔离级别的事务冲突语义全部在该阶段完成,保证只要这里放行的事务,后续的并发执行不会出现问题,所有可能引起数据正确性不符合隔离级别的事务要么在该阶段被取消,要么把其他正在执行的事务取消,让自己得以执行。
数据复制阶段
这一阶段通过raft将对数据库的修改操作复制到所有副本所在节点上,当得到大多数节点完成复制的响应后,Leader会将数据写入到rocksdb(对于分布式事务,写intent_db,记录中包含锁),然后leader会释放内存锁。
7.2.4 TransactionStatus::COMMITTED
// 收到commit消息后,会检查事务是否被其他事务给取消了
// raft将TransactionStatus::COMMITTED消息复制到所有副本,复制完成后,更新 commit_time_
commit_time_ = data.hybrid_time; // 这个时间戳是 COMMITTED这rpc请求对应的operation在start阶段从MvccManager申请的
// 然后调用StartApply将 APPLYING请求入队,该请求的参数如下:
void StartApply() {
if (context_.leader()) {
for (const auto& tablet : involved_tablets_) { // 通知当前事务的所有涉及到的tablet,执行APPLY操作
context_.NotifyApplying({
.tablet = tablet.first,
.transaction = id_,
.commit_time = commit_time_, // commit_time就是 COMMITTED消息被raft复制完成后的时间戳
.sealed = status_ == TransactionStatus::SEALED});
}
}
}7.2.5 TransactionStatus::APPLYING
// COMMITTED 消息处理完后,对发起事务的客户端来说,事务的流程已经走完了,数据已经可见了。而对yugabyte来说,
// 数据还停留在intent_db中,需要移动到normal_db,并设置LocalCommitedTime,供其他并发事务检测冲突使用。
// 该消息是由TransactionParticipant处理的,同样的会先将该消息通过raft复制到tablet的所有副本,raft复制完该消息后,
// 执行ProcessApply,将数据从intent_db 迁移到 normal_db,然后注册异步任务删除intent_db中的数据
HybridTime commit_time(data.state.commit_hybrid_time()); // 这是 COMMITTED的时间戳
TransactionApplyData apply_data = {
data.leader_term,
id, // 事务ID
data.op_id, // operation id
commit_time, // COMMITTED的时间戳
data.hybrid_time, // APPLYING的时间戳
data.sealed,
data.state.tablets(0) };
ProcessApply(apply_data);
// 每个tablet上的 ProcessApply 工作流程(目前只有局部tablet视角)
CHECKED_STATUS ProcessApply(const TransactionApplyData& data) {
{ // 一顿操作,主要是设置 Local Commit Time
// It is our last chance to load transaction metadata, if missing.
// Because it will be deleted when intents are applied.
// We are not trying to cleanup intents here because we don't know whether this transaction
// has intents of not.
auto lock_and_iterator = LockAndFind(
data.transaction_id, "pre apply"s, TransactionLoadFlags{TransactionLoadFlag::kMustExist});
if (!lock_and_iterator.found()) {
// This situation is normal and could be caused by 2 scenarios:
// 1) Write batch failed, but originator doesn't know that.
// 2) Failed to notify status tablet that we applied transaction.
LOG_WITH_PREFIX(WARNING) << Format("Apply of unknown transaction: $0", data);
NotifyApplied(data);
CHECK(!FLAGS_fail_in_apply_if_no_metadata);
return Status::OK();
}
lock_and_iterator.transaction().SetLocalCommitTime(data.commit_ht);
LOG_IF_WITH_PREFIX(DFATAL, data.log_ht < last_safe_time_)
<< "Apply transaction before last safe time " << data.transaction_id
<< ": " << data.log_ht << " vs " << last_safe_time_;
}
// 通过事务反向索引,找到所有的intent,然后apply到normal_db
CHECK_OK(applier_.ApplyIntents(data));
{// 这里发起异步删除 intent 任务(删除intent_db中的数据)
MinRunningNotifier min_running_notifier(&applier_);
// We are not trying to cleanup intents here because we don't know whether this transaction
// has intents or not.
auto lock_and_iterator = LockAndFind(
data.transaction_id, "apply"s, TransactionLoadFlags{TransactionLoadFlag::kMustExist});
if (lock_and_iterator.found()) {
RemoveUnlocked(lock_and_iterator.iterator, "applied"s, &min_running_notifier);
}
}
NotifyApplied(data);
return Status::OK();
}7.2.6 TransactionStatus::ABORTED and TransactionStatus::CLEANUP
事务因为某些原因(发生错误或用户主动abort)走到abort流程后,需要分别由coordinator变更status tablet状态,由participate清理垃圾数据。












