
1. Tensorflow高效流水线Pipeline
2. Tensorflow的数据处理中的Dataset和Iterator
3. Tensorflow生成TFRecord
4. Tensorflow的Estimator实践原理
1. 前言
前面博文介绍了Tensorflow的一大块,数据处理,今天介绍Tensorflow的高级API,模型的建立和简化过程。
2. Estimator优势
本文档介绍了Estimator一种可极大地简化机器学习编程的高阶TensorFlow API。用了Estimator你会得到数不清的好处。
- 您可以在本地主机上或分布式多服务器环境中运行基于 Estimator 的模型,而无需更改模型。此外,您可以在CPU、GPU或TPU上运行基于Estimator 的模型,而无需重新编码模型。
- 使用dataset高效处理数据,搭配上Estimator再GPU或者TPU上高效的运行模型,提高整体的模型运行的时间。
- 使用Estimator编写应用时,您必须将数据输入管道从模型中分离出来。这种分离简化了不同数据集的实验流程。
- Estimator提供安全的分布式训练循环,可以控制如何以及何时:
- 构建图
- 初始化变量
- 开始排队
- 处理异常
- 创建检查点文件并从故障中恢复
- 保存 TensorBoard 的摘要
- Estimator简化了在模型开发者之间共享实现的过程。
- 您可以使用高级直观代码开发先进的模型。简言之,采用Estimator创建模型通常比采用低阶TensorFlow API更简单。
- Estimator本身在tf.layers之上构建而成,可以简化自定义过程。
3. 预创建的Estimator
编写一个或多个数据集导入函数。
- 一个字典,其中键是特征名称,值是包含相应特征数据的张量(或 SparseTensor)
- 一个包含一个或多个标签的张量
def input_fn(dataset):
manipulate dataset, extracting the feature dict and the label
return feature_dict, label
定义特征列。每个tf.feature_column都标识了特征名称、特征类型和任何输入预处理操作。
Define three numeric feature columns.
population = tf.feature_column.numeric_column('population') crime_rate = tf.feature_column.numeric_column('crime_rate') median_education = tf.feature_column.numeric_column('median_education', normalizer_fn=lambda x: x - global_education_mean)
实例化相关的预创建的Estimator。 例如,下面是对名为LinearClassifier的预创建Estimator进行实例化的示例代码:
Instantiate an estimator, passing the feature columns.
estimator = tf.estimator.LinearClassifier( feature_columns=[population, crime_rate, median_education], )
调用训练、评估或推理方法。例如,所有 Estimator 都提供训练模型的 train 方法。
my_training_set is the function created in Step 1
estimator.train(input_fn=my_training_set, steps=2000)
4. 自定义Estimator
4.1 input_fn输入函数
输入函数可以直接返回feature_dict, label,也可以返回的是dataset.make_one_shot_iterator(),这样就和我们高效的数据预处理接上了。
def input_fn(features, labels, batch_size):
"""An input function for training"""
# Convert the inputs to a Dataset.
dataset = tf.data.Dataset.from_tensor_slices((dict(features), labels))
# Shuffle, repeat, and batch the examples.
dataset = dataset.shuffle(1000).repeat().batch(batch_size)
# Return the read end of the pipeline.
return dataset.make_one_shot_iterator().get_next()
4.2 feature_columns创建特征列
您必须定义模型的特征列来指定模型应该如何使用每个特征。无论是使用预创建的Estimator还是自定义Estimator,您都要使用相同的方式定义特征列。
以下代码为每个输入特征创建一个简单的 numeric_column,表示应该将输入特征的值直接用作模型的输入:
# Feature columns describe how to use the input.
my_feature_columns = []
for key in train_x.keys():
my_feature_columns.append(tf.feature_column.numeric_column(key=key))
4.3 model_fn模型函数
def model_fn(
features, # This is batch_features from input_fn
labels, # This is batch_labels from input_fn
mode, # An instance of tf.estimator.ModeKeys
params): # Additional configuration
前两个参数是从输入函数中返回的features和labels,mode参数表示调用程序是请求训练、预测还是评估。所以在model_fn里面需要实现训练、预测、评估3种请求方式。
调用程序可以将params传递给Estimator的构造函数。传递给构造函数的所有params 转而又传递给model_fn。
classifier = tf.estimator.Estimator(
model_fn=my_model,
params={
'feature_columns': my_feature_columns,
# Two hidden layers of 10 nodes each.
'hidden_units': [10, 10],
# The model must choose between 3 classes.
'n_classes': 3,
})
5. 定义模型
5.1 定义输入层
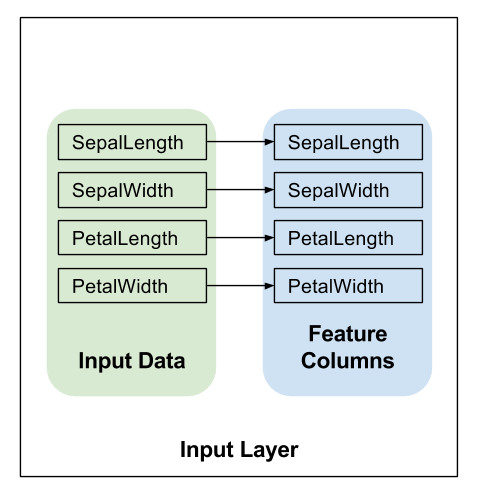
在 model_fn 的第一行调用 tf.feature_column.input_layer,以将特征字典和 feature_columns 转换为模型的输入,会应用特征列定义的转换,从而创建模型的输入层。如下所示:
# Use `input_layer` to apply the feature columns.
net = tf.feature_column.input_layer(features, params['feature_columns'])
5.2 隐藏层
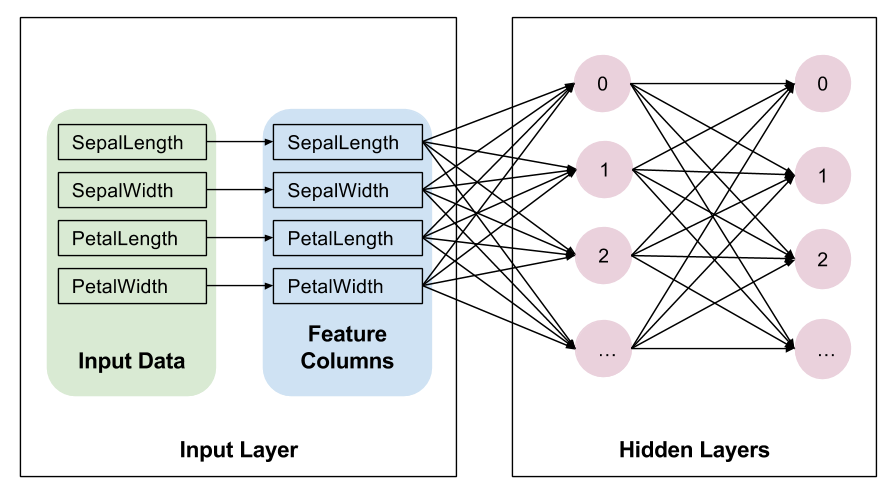
如果您要创建深度神经网络,则必须定义一个或多个隐藏层。Layers API 提供一组丰富的函数来定义所有类型的隐藏层,包括卷积层、池化层和丢弃层。
隐藏层是用户自己发挥想象力,定义的可以很复杂的地方。
# Build the hidden layers, sized according to the 'hidden_units' param.
for units in params['hidden_units']:
net = tf.layers.dense(net, units=units, activation=tf.nn.relu)
5.3 输出层
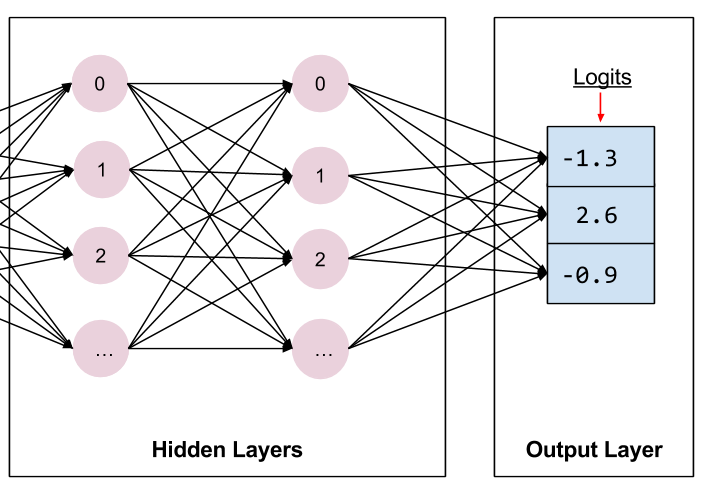
# Compute logits (1 per class).
logits = tf.layers.dense(net, params['n_classes'], activation=None)
tf.nn.softmax 函数会将这些对数转换为概率。
5.4 实现训练、评估和预测
创建模型函数的最后一步是编写实现预测、评估和训练的分支代码。
重点关注第三个参数 mode。如下表所示,当有人调用train、evaluate或predict时,Estimator框架会调用模型函数并将mode参数设置为ModeKeys.TRAIN,ModeKeys.EVAL,ModeKeys.PREDICT。
模型函数必须提供代码来处理全部三个mode值。对于每个mode值,您的代码都必须返回 tf.estimator.EstimatorSpec的一个实例,其中包含调用程序所需的信息。我们来详细了解各个mode。
- 训练 ModeKeys.TRAIN
构建训练操作需要优化器。我们将使用 tf.train.AdagradOptimizer。 我们使用优化器的 minimize 方法根据我们之前计算的损失构建训练操作。 minimize 方法还具有 global_step 参数。
optimizer = tf.train.AdagradOptimizer(learning_rate=0.1)
train_op = optimizer.minimize(loss, global_step=tf.train.get_global_step())
if mode == tf.estimator.ModeKeys.TRAIN:
return tf.estimator.EstimatorSpec(mode, loss=loss, train_op=train_op)
- 评估 ModeKeys.EVAL
虽然返回指标是可选的。TensorFlow 提供一个指标模块 tf.metrics 来计算常用指标。为简单起见,我们将只返回准确率。
# Compute evaluation metrics.
accuracy = tf.metrics.accuracy(labels=labels,
predictions=predicted_classes,
name='acc_op')
metrics = {'accuracy': accuracy}
tf.summary.scalar('accuracy', accuracy[1])
if mode == tf.estimator.ModeKeys.EVAL:
return tf.estimator.EstimatorSpec(
mode, loss=loss, eval_metric_ops=metrics)
- 预测 ModeKeys.PREDICT
该模型必须经过训练才能进行预测。经过训练的模型存储在磁盘上,位于您实例化 Estimator 时建立的 model_dir 目录中。
此模型用于生成预测的代码如下所示:
# Compute predictions.
predicted_classes = tf.argmax(logits, 1)
if mode == tf.estimator.ModeKeys.PREDICT:
predictions = {
'class_ids': predicted_classes[:, tf.newaxis],
'probabilities': tf.nn.softmax(logits),
'logits': logits,
}
return tf.estimator.EstimatorSpec(mode, predictions=predictions)
predictions 存储的是下列三个键值对:
- class_ids 存储的是类别 ID(0、1 或 2),表示模型对此样本最有可能归属的品种做出的预测。
- probabilities 存储的是三个概率(在本例中,分别是 0.02、0.95 和 0.03)
- logit 存储的是原始对数值(在本例中,分别是 -1.3、2.6 和 -0.9)
我们通过 predictions 参数(属于 tf.estimator.EstimatorSpec)将该字典返回到调用程序。Estimator 的 predict 方法会生成这些字典。
6. 实例化Estimator
通过 Estimator 基类实例化自定义 Estimator,如下所示:
# Build 2 hidden layer DNN with 10, 10 units respectively.
classifier = tf.estimator.Estimator(
model_fn=my_model,
params={
'feature_columns': my_feature_columns,
# Two hidden layers of 10 nodes each.
'hidden_units': [10, 10],
# The model must choose between 3 classes.
'n_classes': 3,
})
在这里,params 字典与 DNNClassifier 的关键字参数用途相同;即借助 params 字典,您无需修改 model_fn 中的代码即可配置 Estimator。
使用 Estimator 训练、评估和生成预测要用的其余代码与预创建的 Estimator 一章中的相同。例如,以下行将训练模型:
# Train the Model.
classifier.train(
input_fn=lambda:iris_data.train_input_fn(train_x, train_y, args.batch_size),
steps=args.train_steps)
7. 工作流程
- 假设存在合适的预创建的Estimator,使用它构建第一个模型并使用其结果确定基准。
- 使用此预创建的Estimator构建和测试整体管道,包括数据的完整性和可靠性。
- 如果存在其他合适的预创建的Estimator,则运行实验来确定哪个预创建的Estimator效果最好。
- 可以通过构建自定义Estimator进一步改进模型。










