
作者 | 孙健波(天元) 阿里巴巴技术专家
2011 年,Heroku 的联合创始人 Adam Wiggins 根据针对上百万应用托管和运维的经验,发布了著名的 “十二要素应用宣言(The Twelve-Factor App)”。不知那时候他们有没有想到,这份宣言会在今后数年时间里,成为 SaaS 应用开发的启蒙书。同时也奠定了 Heroku 在 PaaS 领域的地位,成为了云上应用开发规范化的基石。
Heroku 无疑是一家伟大的公司,它关注应用与开发者,“以应用为中心”的理念让我们至今受益。然而在过去这一两年里,我们看到许多 Heroku 的用户开始寻找别的选择。这不禁让我们好奇,站在“云原生”如火如荼的今天回望过去,Heroku 的“得”与“失”究竟在哪里?
“以应用为中心”的先进理念
Heroku 创办于 2007 年,是最早成熟的 PaaS 产品之一。Heroku 也是最早喊出“以应用为中心”,大规模帮助应用上云的产品。正是围绕“以应用为中心”这样先进的理念,使得 Heroku 从一开始便拥有了至今看来都非常诱人的功能:
用户可以直接从开发语言出发,选择对应的技术栈,通过 heroku create 这样简单的命令,将应用托管到云上。主流的开发语言,均能在 Heroku 中找到对应的选择。从代码的变动自动触发软件的部署交付,清晰的工作流、多样的发布策略,直到后来的很多年都是 DevOps 们梦寐以求的功能;
**用户无需关心应用背后的基础设施是什么,Heroku 负责维护背后的一切。**这句看似简单的话背后隐藏了巨大的复杂性,试想下某个软件或系统爆出安全漏洞后给你带来的窘境,又或者你想使用一个数据库服务时却不得不维护一个数据库实例。而在 Heroku, 这一切麻烦你都无需关心;
**高可用与弹性作为附加能力。**Heroku 平台托管的服务具备高可用等附加能力,更让人惊喜的是,满足 12-factor 的应用还天然具备了扩缩容的能力,可以很轻松的抗住突发流量,这在当时无异于黑科技般的存在。
**正是这样强大的能力,使得 Heroku 成为了 PaaS 领域事实上的标准,**无论是后续的 Cloud Foundry 还是 OpenShift,似乎都没有对 Heroku 有实质性的超越。
Heroku 不再物超所值
众所周知,相对于只是提供纯粹计算能力的 IaaS 而言,以服务能力著称、提供众多开箱即用附加功能的 PaaS,价格上素来都是普遍偏贵的。毕竟 PaaS 可以使你专注于业务本身,贵一点自然也无可厚非。更何况 PaaS 通常根据开通附加能力的数量收费,刚开始甚至更便宜,Heroku 亦是如此。
一开始,用户可能感觉只是比自己在 IaaS 上搭建服务贵一点点。当你发现应用可以便捷绑定 Heroku 提供的高可用 PostgresSQL 数据库时,甚至会觉得它贵的物超所值。不过,随着业务逻辑逐渐复杂、部署规模越来越大,需求自然而然就变了。比如为了让用户的数据更安全,你可能需要一个只能私有网络访问的 PostgresSQL 实例,而 Heroku 默认不具备这样的功能,你必须要配置一个 VPC 才能做到,你自然要为这个 VPC 额外付费。这类需求逐渐覆盖了你每一个实例,增加的费用直接变成了增长的单价,成本快速上升。与此同时,IaaS 厂商的能力也正在爆炸式的增长。今天,几乎所有的云服务商都开始提供数据库服务,并且这些数据库实例的 VPC 通常是免费的。
另一方面,**Heroku 从 13 年前诞生至今,一直是闭源的商业平台,关于 Heroku 的一切你都只能在其本身的平台上玩。**这无疑给新人学习、上手造成了很高的门槛,甚至许多人因此不愿意体验该产品。这也导致周边生态的配套工具相当匮乏,只要官方不提供的能力,用户就得自己开发。然而无论是招聘 Heroku 熟练工,还是从零开始培养,这无疑都带来了不小的人力成本。
反观如今的云原生社区,任何人都可以通过几条简单的命令在自己的开发环境中运行 Kubernetes,开发者可以很轻易的体验和学习,积累经验。基础设施主动对接 Kubernetes 生态。周边的各类工具也在不断的繁荣演进。
黑盒化的运行时体验
提到 Heroku,另一个代表性的技术无疑就是 Buildpack。在 Docker 镜像机制出现之前,使用 Buildpack 管理用户应用的运行时构建,使得 PaaS 的运行时最终与语言无关,这无疑是非常聪明的做法。然而十多年过去,Buildpack 的模式早已暴露出许多问题。
一方面是官方支持的 Buildpack 数量少,限制多,比如运行系统仅支持 Linux 的 Ubuntu 发行版;某些 Ubuntu 安装包在 Buildpack 中没有安装你便无法使用;相对小众的开发语言(如 Elixir)均不支持;又或者是你的应用包含多种语言,使用起来就变得复杂;
另一方面,你也许能自定义或者找到第三方的 Buildpack 满足需求,但是没有人来保证它的稳定。一旦出了问题,你很难在本地运行 Buildpack 排查问题,而 Heroku 平台的错误信息透出方式并不直接,日志排查更是不便。
2017 年 9 月份,Heroku 最终还是支持了基于 Docker 镜像的运行时部署,然而至今为止依旧有不少限制,其中最大的限制是存储,只能使用 Heroku 的临时存储,这几乎就决定了你不可能自己编写像 etcd、TiDB 这类复杂的有状态应用。
一切的本质,都在于 Heroku 给用户提供的体验是黑盒化的,为用户屏蔽基础设施的同时,也使得用户失去了改造的自由。这也是为什么即便像 Cloudfoundry 这样理念极其类似的 PaaS 平台,即便是开源的,依旧存在同样的弊病。
**事实上用户喜欢的是“白盒”,他们希望能够自定义基础设施,可以平行的替换或改造平台的已有功能,而非只能局限在平台提供的能力之上构建。**就像我们买了一辆车,在雨雪的极端天气下,我们希望可以换雪地胎,而不是只能加装防滑链。

Kubernetes 的出现
而 Kubernetes 正是这样一个白盒化体验,它从未尝试去屏蔽基础设施,而是作为一个标准化接入层,把基础设施层的能力通过声明式 API 暴露出来,将选择权留给了用户。正是在这样一个开放世界里,复杂有状态应用的管理也终于得以在云上落地了。另一方面, Kubernetes 并不是 PaaS。相比于 Heroku 官方提供了将近两百个 add-ons(插件)) 用于增强包括数据库、监控、日志、缓存、搜索、分析、权限等能力,而 Kubernetes 则强调强可扩展能力,希望用户自己可以通过编写 CRD Operator 新增任意能力。
那么,这两种做法的区别是什么呢?
封闭、限制 vs 开放、自由
众所周知,Heroku 一直是一个“主观”的 PaaS 平台,12-factor 代表了应用必须云原生化的强硬观点,这一点毋庸置疑是正确的,而且非常了不起。但如果观念不能与时俱进,那么“主观”就会变得危险。就比如容器和虚拟机都已经相当普及的今天,Heroku 依旧坚持应用只能运行在 Heroku Dynos 上面。虽然这种统一很大程度上为管理提供了便利,但是这也使得用户丢掉了很多灵活性,更重要的是,运行时的巨大差异,开始让很多用户觉得自己与更广泛的社区“格格不入”。
不过,Heroku 有属于自己的封闭生态,除了上文提到官方维护的 Add-ons 以外,还有方便用户一键部署到 Heroku 平台的 4700 多个 Buttons 应用 和 用于自定义运行时和构建流程的 6300 多个 Buildpacks,这两大功能都允许用户自定义并可以申请注册到官方的应用市场中,数量着实惊人。这样繁荣的社区怎会被人诟病?出于好奇,笔者整体分析了一下这些项目。
下面两张图分别是 Heroku Buildpack 和 Buttons 的项目统计:
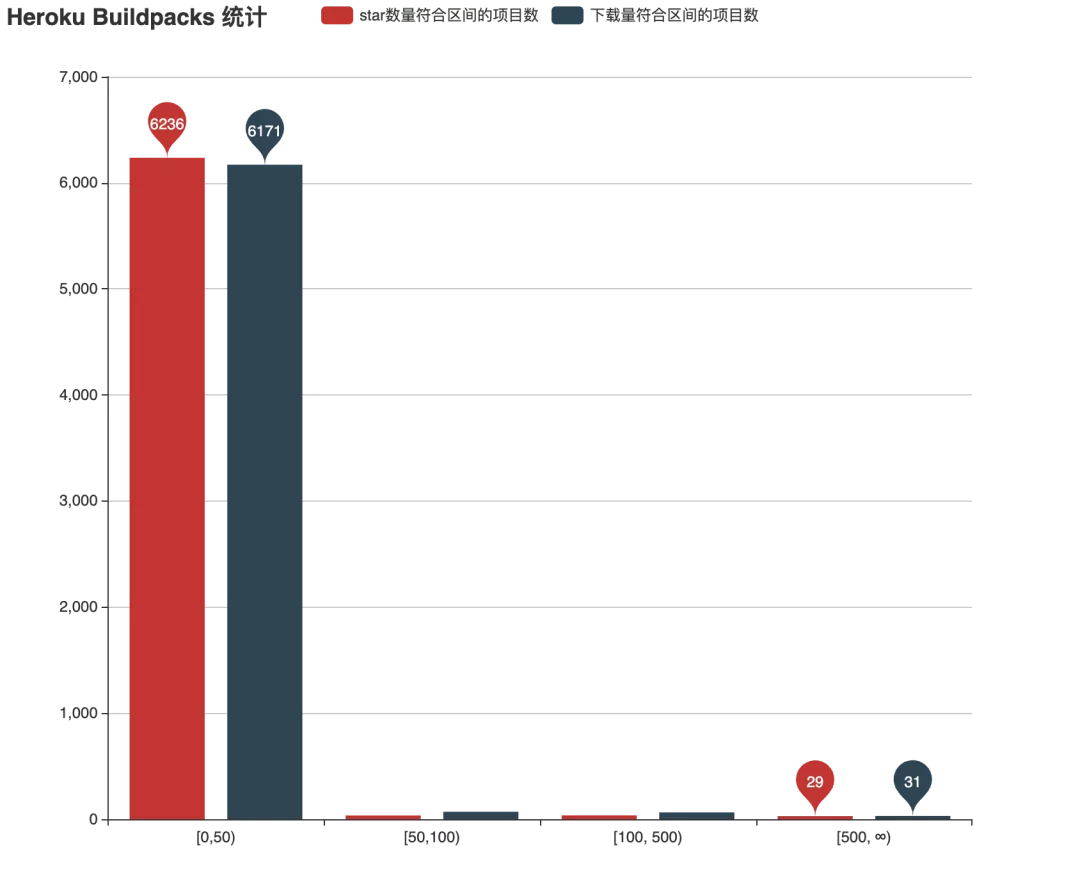
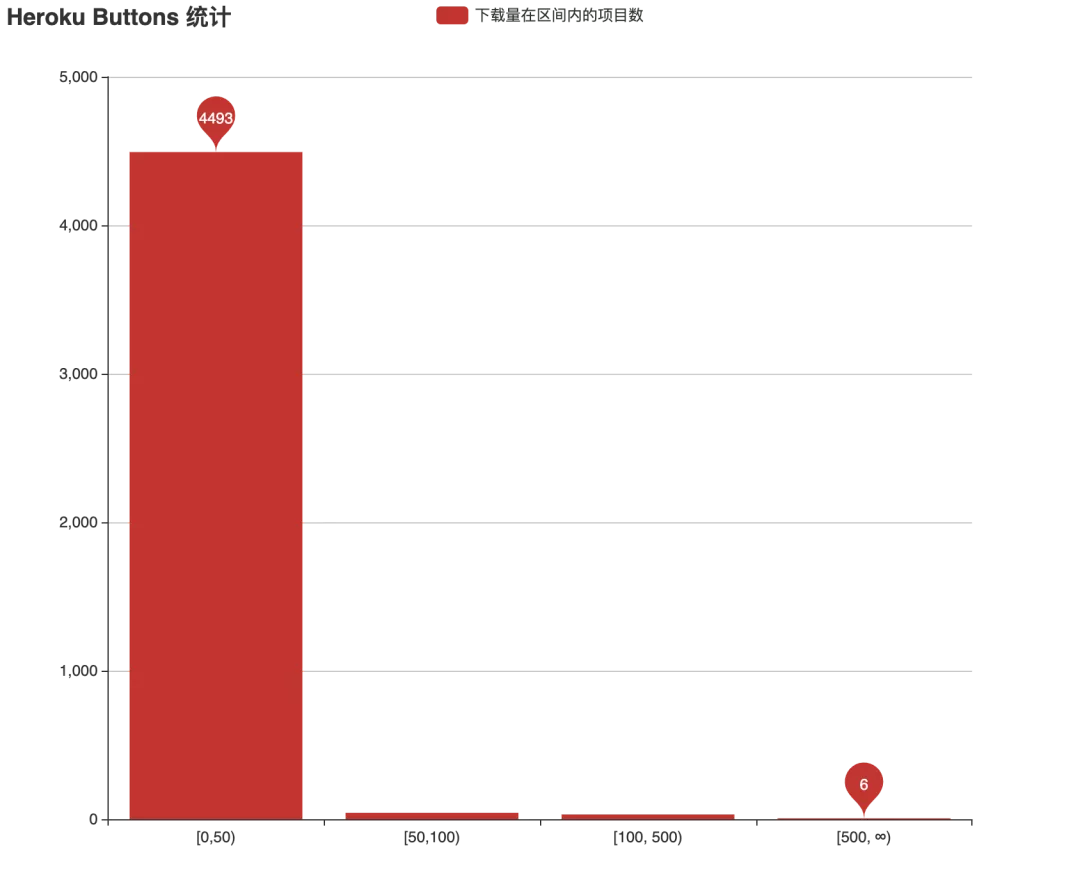
我们可以看到,Buildpack 只能在 Heroku 平台使用,所以 star 数量代表了大家对项目的关心,而下载量则代表了用户的使用频度。图中,6000 多个 Buildpack 的 star 数和下载安装量均在 50 以内,而超过 500 个 star 和 500 次下载部署的项目均只有 30 个左右。再来看 Buttons 中的项目,由于这些项目本身还可以部署到 Heroku 以外的其他平台,所以就只看在 Heroku 的部署下载量反映大家的使用频度,而图中超过 500 次部署的 Buttons 项目只有 6 个。原来这一切竟只是表面繁荣。
面对这样一个统计数据,我们很难说 Heroku 的封闭生态是成功的。
Buildpack 本质上是对进程的构建和打包,同样的工作业界几乎都已经统一通过 Dockerfile 构建镜像解决。与 Buildpack 只能在 Heroku 平台上使用的封闭生态不同,Docker 镜像以及 OCI 容器和镜像规范的出现,大大推动了基于容器镜像的应用打包方式走向了全面繁荣。而用于存储镜像的 Docker Registry 也是人人都可以搭建的镜像仓库。从数字上看,仅官方镜像仓库上的镜像数量就超过了 300 万,更有数千镜像下载量超过了 100 万,这才是成功生态应该有的力量。
而在 Kubernetes 生态中帮助应用打包并可以一键部署 CRD Operator 的 Helm Chats 也与 Heroku 的 Buttons 类似。同样, Helm Charts 的托管平台是可以自由搭建的,而 Chart 本身则在任何一个开源或者商业版本的 Kubernetes 上均能运行。虽然没有明确的统计数据,但是像 Helm Hub、Kubeapps Hub、CloudNative App Hub 等 Charts 托管网站里的内容看起来也已经取得了不小的成功。
Heroku 们的未来?
从上述观察来看,Heroku 过去最重要的教训,在于不够开放而错失了原本属于自己的云原生应用生态。而在 Kubernetes 项目成为基础设施主流之后,Heroku 以及它的开源继任者 Cloud Foundry 还是很难走出“被故意忽视”的困境。这个困境的关键并不在于它们是不是基于 K8s 构建的,而是它们能不能带来像 K8s 一样的开放与自由。
可是,另一方面,Kubernetes 本身从始至终都不是一个面向最终用户的体验,也不是最终用户想要的东西。Kubernetes 自身“白盒化”的体验正在为越来越多的业务研发和运维带来“太复杂”的困扰。而这个社区里大量的 CRD Operator 则像一个个烟囱,彼此孤立,不能联动,而且有大量的冗余(比如:Kubernetes 中永无止尽的 Ingress 实现 )。这一切都说明,纯粹使用 Kubernetes 并非托管云原生应用的“标准答案”。而那些试图“给 K8s 写个界面”的 PaaS 构建者们,似乎又陷入了 Heroku 的困境。这种变化,也让 PaaS 与 Kubernetes 之间的关系越来越复杂和不清晰。
从 Kubernetes 到“以应用为中心”的美好未来之间,全世界的 PaaS 工程师其实都在期待一项全新的技术能够弥补这之间的鸿沟。阿里云原生应用平台团队的做法是,通过为应用“建模”的方式来解决这个问题,这也正是 Open Application Model (OAM) 开源项目得以创建的重要目的。
最后
OAM(Open Application Model)开放应用模型是阿里联合微软针对云原生应用的模型,第一次对“以应用为中心”的基础设施和构建规范进行了完整的阐述。应用管理者只要遵守这个规范,就可以编写出一个自包含、自描述的“应用定义文件”。
OAM 相关内容在 github 上完全开源,同时我们也为 Go 生态编写了 oam-go-sdk 方便快速实现 OAM。
目前,阿里巴巴团队正在上游贡献和维护这套技术,如果大家有什么问题或者反馈,也非常欢迎与我们在上游或者钉钉联系。
参与方式:
- 钉钉扫码进入 OAM 项目中文讨论群

(钉钉扫码加入交流群)

“阿里巴巴云原生关注微服务、Serverless、容器、Service Mesh 等技术领域、聚焦云原生流行技术趋势、云原生大规模的落地实践,做最懂云原生开发者的技术圈。”











