
MongoDB oplog (类似于 MySQL binlog) 记录数据库的所有修改操作,除了用于主备同步;oplog 还能玩出很多花样,比如
- 全量备份 + 增量备份所有的 oplog,就能实现 MongoDB 恢复到任意时间点的功能
- 通过 oplog,除了实现到备节点的同步,也可以额外再往单独的集群同步数据(甚至是异构的数据库),实现容灾、多活等场景,比如阿里云开源的 MongoShake 就能实现基于 oplog 的增量同步。
- MongoDB 3.6+ 版本对 oplog 进行了抽象,提供了 Change Stream 的接口,实际上就是能不断订阅数据库的修改,基于这些修改可以触发一些自定义的事件。
- ......
总的来说,MongoDB 可以通过 oplog 来跟生态对接,来实现数据的同步、迁移、恢复等能力。而在构建这些能力的时候,有一个通用的需求,就是工具或者应用需要有不断拉取 oplog 的能力;这个过程通常是
- 根据上次拉取的位点构建一个 cursor
- 不断迭代 cursor 获取新的 oplog
那么问题来了,由于 MongoDB oplog 本身没有索引的,每次定位 oplog 的起点都需要进行全表扫描么?
oplog 的实现细节
{ "ts" : Timestamp(1563950955, 2), "t" : NumberLong(1), "h" : NumberLong("-5936505825938726695"), "v" : 2, "op" : "i", "ns" : "test.coll", "ui" : UUID("020b51b7-15c2-4525-9c35-cd50f4db100d"), "wall" : ISODate("2019-07-24T06:49:15.903Z"), "o" : { "_id" : ObjectId("5d37ff6b204906ac17e28740"), "x" : 0 } }
{ "ts" : Timestamp(1563950955, 3), "t" : NumberLong(1), "h" : NumberLong("-1206874032147642463"), "v" : 2, "op" : "i", "ns" : "test.coll", "ui" : UUID("020b51b7-15c2-4525-9c35-cd50f4db100d"), "wall" : ISODate("2019-07-24T06:49:15.903Z"), "o" : { "_id" : ObjectId("5d37ff6b204906ac17e28741"), "x" : 1 } }
{ "ts" : Timestamp(1563950955, 4), "t" : NumberLong(1), "h" : NumberLong("1059466947856398068"), "v" : 2, "op" : "i", "ns" : "test.coll", "ui" : UUID("020b51b7-15c2-4525-9c35-cd50f4db100d"), "wall" : ISODate("2019-07-24T06:49:15.913Z"), "o" : { "_id" : ObjectId("5d37ff6b204906ac17e28742"), "x" : 2 } }
上面是 MongoDB oplog 的示例,oplog MongoDB 也是一个集合,但与普通集合不一样
- oplog 是一个 capped collection,但超过配置大小后,就会删除最老插入的数据
- oplog 集合没有 id 字段,ts 可以作为 oplog 的唯一标识; oplog 集合的数据本身是按 ts 顺序组织的
- oplog 没有任何索引字段,通常要找到某条 oplog 要走全表扫描
我们在拉取 oplog 时,第一次从头开始拉取,然后每次拉取使用完,会记录最后一条 oplog 的ts字段;如果应用发生重启,这时需要根据上次拉取的 ts 字段,先找到拉取的起点,然后继续遍历。
oplogHack 优化
注:以下实现针对 WiredTiger 存储引擎,需要 MongoDB 3.0+ 版本才能支持
如果 MongoDB 底层使用的是 WiredTiger 存储引擎,在存储 oplog 时,实际上做过优化。MongoDB 会将 ts 字段作为 key,oplog 的内容作为 value,将key-value 存储到 WiredTiger 引擎里,WiredTiger 默认配置使用 btree 存储,所以 oplog 的数据在 WT 里实际上也是按 ts 字段顺序存储的,既然是顺序存储,那就有二分查找优化的空间。
MongoDB find 命令提供了一个选项,专门用于优化 oplog 定位。
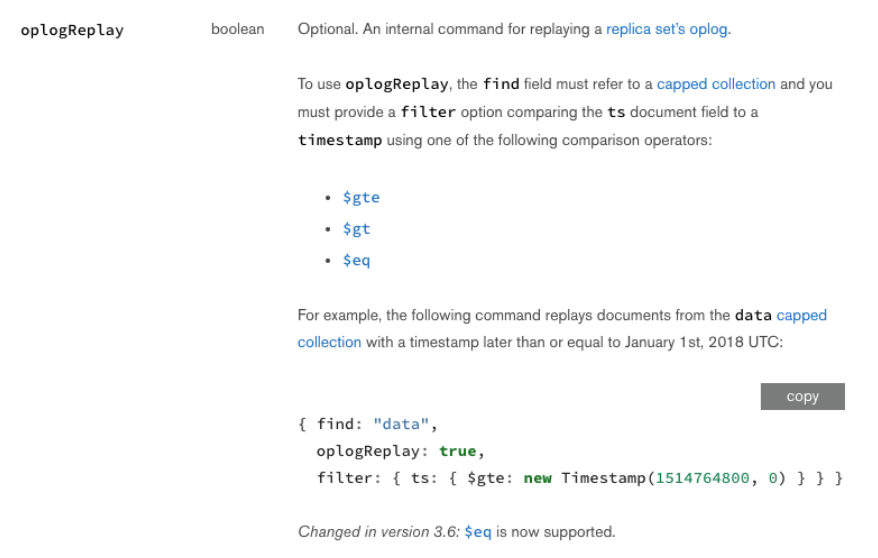
大致意思是,如果你find的集合是oplog,查找条件是针对 ts 字段的 gte、gt、eq ,那么 MongoDB 字段会进行优化,通过二分查找快速定位到起点; 备节点同步拉取oplog时,实际上就带了这个选项,这样备节点每次重启,都能根据上次同步的位点,快速找到同步起点,然后持续保持同步。
oplogHack 实现
由于咨询问题的同学对内部实现感兴趣,这里简单的把重点列出来,要深刻理解,还是得深入撸细节。
// src/monogo/db/query/get_executor.cpp
StatusWith<unique_ptr<PlanExecutor>> getExecutorFind(OperationContext* txn,
Collection* collection,
const NamespaceString& nss,
unique_ptr<CanonicalQuery> canonicalQuery,
PlanExecutor::YieldPolicy yieldPolicy) {
// 构建 find 执行计划时,如果发现有 oplogReplay 选项,则走优化路径
if (NULL != collection && canonicalQuery->getQueryRequest().isOplogReplay()) {
return getOplogStartHack(txn, collection, std::move(canonicalQuery));
}
...
return getExecutor(
txn, collection, std::move(canonicalQuery), PlanExecutor::YIELD_AUTO, options);
}
StatusWith<unique_ptr<PlanExecutor>> getOplogStartHack(OperationContext* txn,
Collection* collection,
unique_ptr<CanonicalQuery> cq) {
// See if the RecordStore supports the oplogStartHack
// 如果底层引擎支持(WT支持,mmapv1不支持),根据查询的ts,找到 startLoc
const BSONElement tsElem = extractOplogTsOptime(tsExpr);
if (tsElem.type() == bsonTimestamp) {
StatusWith<RecordId> goal = oploghack::keyForOptime(tsElem.timestamp());
if (goal.isOK()) {
// 最终调用 src/mongo/db/storage/wiredtiger/wiredtiger_record_store.cpp::oplogStartHack
startLoc = collection->getRecordStore()->oplogStartHack(txn, goal.getValue());
}
}
// Build our collection scan...
// 构建全表扫描参数时,带上 startLoc,真正执行是会快速定位到这个点
CollectionScanParams params;
params.collection = collection;
params.start = *startLoc;
params.direction = CollectionScanParams::FORWARD;
params.tailable = cq->getQueryRequest().isTailable();
}
原文链接
本文为云栖社区原创内容,未经允许不得转载。










