
系列文章推荐阅读
0. 前言
到目前为止,我们已经讲述了顺序表、链表、栈、队列四种数据结构,它们有一个共同的特点,就是它们都是线性表,换句话来说,它们都是线性结构,像一根绳子一样。
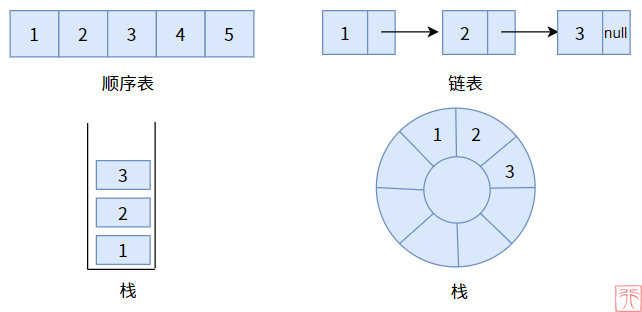
在文章【线性表】已经介绍过线性表的定义了,即由若干元素按照线性结构(一对一的关系)组成的有限序列。
关键词是一对一的关系。
显然,在复杂的现实社会中,这种一对一的关系是不能较好的满足我们的需求的。
比如说,父母和多个孩子之间的关系,一个父亲/母亲对应多个孩子,这显然不是一对一,而是一对多的关系。那么此时我们如何来描述这种一对多的关系呢?
当然是使用具有一对多关系的数据结构啦!有这种数据结构吗?有!本文就来介绍这种数据结构 —— 树及其特殊形式的二叉树。
1. 识树
1.0. 什么是树?
提到树(Tree),大家脑海中首先浮出的画面应该是类似这样的:

之所以我们会用“树”这个名词来命名具有“一对多关系”特性的数据结构,是因为树刚好能够很形象地诠释这种特性。我们来分析一下。
看一下上图中的树(土地以上的部分),它有一个树根,从树根开始往上分叉,主树干分叉成许多次树干,次树干又继续分叉为许多小树枝,小树枝上有许多叶子……
主树干对次树干、次树干对小树枝、小树枝对叶子都是一对多的关系,我们用圆圈代表树干和叶子,把自然界的树倒过来进行一次抽象,得下图(为了方便起见,我们的数据全为字符类型):
可以看到,现实中的树完美契合我们需要的数据结构,所以我们称这种数据结构为树(Tree)。
1.1. 名词与概念
我们按图索骥,来认识树的相关名词。
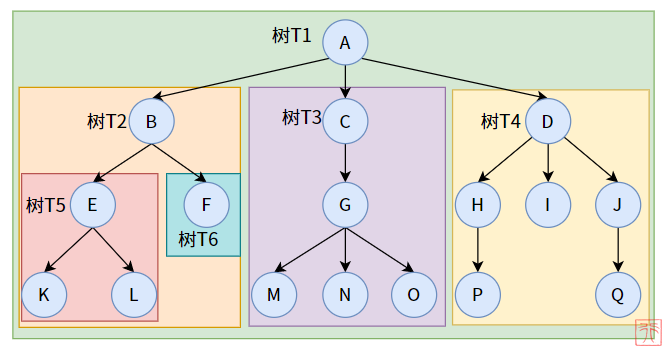
子树:树是一个有限集合,子树则是该集合的子集。就像套娃一样,一棵树下面还包含着其子树。
比如,树T1 的子树为 树T2、T3、T4,树T2的子树为 T5、T6. 上图中还有许多子树没有标记出来。
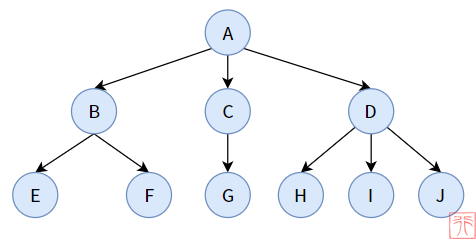
结点(Node):一个结点包括一个数据元素和若干指向其子树分支。
比如,在树T1 中,结点A 包括一个数据元素A 和 三个指向其子树的分支。上图中共有 17 个结点。
根结点(Root):一颗树只有一个树根,这是常识。在数据结构中,“树根”即根节点。
比如,结点A 是树 T1 的根结点;结点C 是树T1 的子结点,是树 T3 的根结点。
度(Degree):一个结点拥有的子树数。
比如,结点A 的度为 3,结点G 的度为 3,结点H 的度为 1.
叶子(Leaf)/ 终端结点:度为 0 的结点被称为叶子结点,很形象吧。
比如,对于树 T1来说,结点F、I、K、L、M、N、O、P、Q 均为叶子。
分支结点 / 非终端结点:和叶子结点相对,即度不为 0 的结点。
内部结点:顾名思义,在树内部的结点,即不是根结点和叶子结点的结点。
孩子(Child)、双亲(Parent)、兄弟(Sibling)、堂兄弟、祖先、子孙这些概念和族谱上的相同。
比如,对于结点B 来说:结点A 是其双亲结点,结点E、F 是其孩子结点,结点C、D 是其兄弟结点,结点K 是其子孙结点。
层次(Level):从根结点开始,根为第一次,根的孩子为第二层,依次往下。
比如,结点K 在树 T1 中的层次为 4.
深度(Depth)/ 高度:指树的最大层次。
比如,树 T1 的深度为 4.
有序树:如果结点的各子树从左到右是有次序的、不能颠倒,则为有序树,否则为无序树。对于有序树的孩子来说,最左边的孩子称为第一个孩子,最右边的孩子称为最后一个孩子。
比如,如果树T1是一个有序树,则其根结点的第一个孩子为结点B,最后一个孩子为结点D.
1.2. 树的递归概念
前面已经介绍了树的轮廓和相关名词概念,为了回答什么是树这个问题,我们这里还需要介绍三种常见的树结构。
【空树】:一颗空树,即没有结点的树。

【只有根结点的树】:只有一个根节点,没有其他结点。
【普通的树】
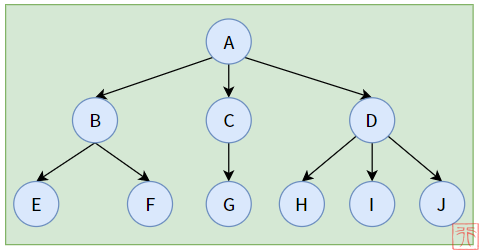
现在我们能来回答什么是树了:
树(Tree)是由 N (N >= 0) 个结点构成的有限集合。
- 当 N = 0 时,树为空树
- 当 N = 1 时,树只有一个根结点
- 当 N > 1 时,树除了一个根结点外,其余结点又可分为若干个不相交的有限集合,我们称之为子树。
非空树有且仅有一个根结点。
树的一对多的关系存在于双亲结点和孩子结点之间。
在树中,因为存在树、子树的概念,所以树的子树仍是一颗树,子树的子树仍是一棵树。
举个例子:人类的孩子仍是人类,人类的孩子的孩子仍是人类。
因为存在双亲、孩子、子孙的概念,所以根结点的孩子结点可以其子树的根结点。
举个例子:一个人,在其孩子看来是父亲,在其父母看来是儿子。
这种概念,就是递归的概念。
即,对于某个“事物”而言,它的“孩子”和它本身并无实质区别,它做的事,它的“孩子”也会做、也要做。一直向下,“孙子”“曾孙”“玄孙”皆是如此。
为了说明递归这个概念,我们将上图的树递归地分解为子树,下图中每个区域都是一颗树(或子树):
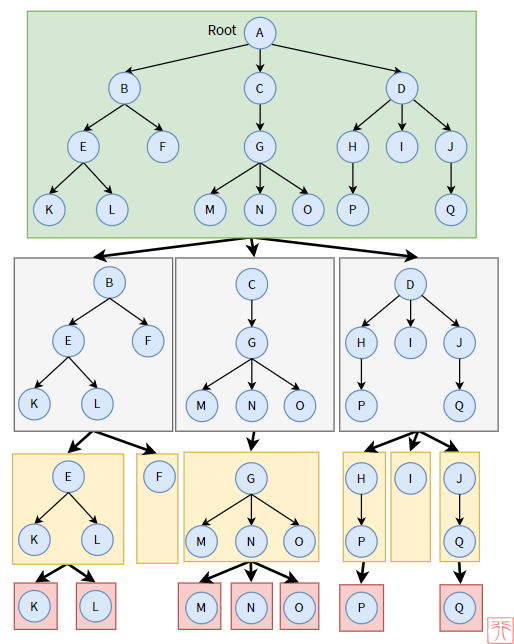
分解到最后,我们最终得到的,可以说是叶子结点,也可以说是只有根结点的树。如结点F、K、L.
在分解的过程中,我们还可以发现,对于每个结点来说,我们都可以将其看作某棵树(子树)的根结点。比如结点E、I都是某棵子树的根结点。这与树有且只有一个根结点并不矛盾。
这就好比我们说,小明只能有一个亲生父亲,但不影响他成为别人的父亲。
整个过程就像在族谱上从祖宗找到子孙一样。所以如果对树的概念有啥不了解的,可以找个族谱翻翻看。
到此,我们可以说,树的定义是一个递归的定义,树是由根结点和它的若干子树组成的,子树也是由根结点和它的若干子树组成的……即在树的定义中又用到树的定义。
1.3. 树和线性表的比较
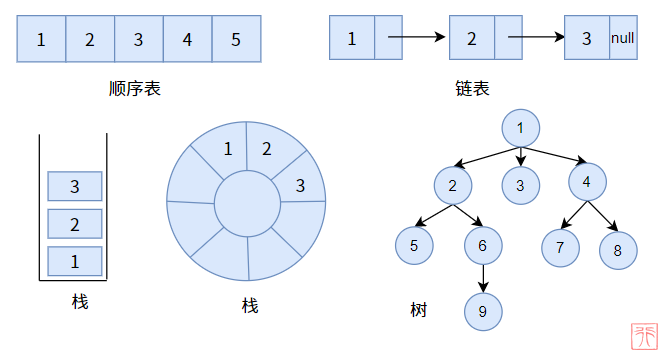
看图直观体验何为(前驱结点和后继结点间)一对一的关系,何为(双亲结点和孩子结点之间)一对多的关系。
2. 识二叉树
2.0. 什么是二叉树?
何为二叉树?首先它得是颗树,其次它得是二叉的。
前面已经初步认识了树,它的结点的孩子数量是没有限制的,即,你想要几个孩子就要几个孩子,想分几个叉就分几个叉。
而二叉树,则是限制了孩子数量,即每个结点最多只能有两个孩子(左孩子和右孩子),打个比方就是“二胎树”。
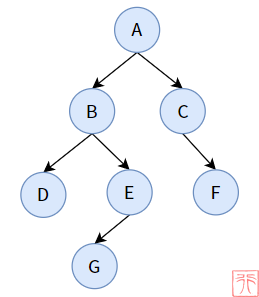
结点A 的左孩子是结点B,右孩子是结点C.
二叉树是一种每个结点至多有两棵子树(即每个结点的度最大为 2 )的有序树。
2.1. 二叉树的几种形态
一、空二叉树

二、仅有根结点的二叉树

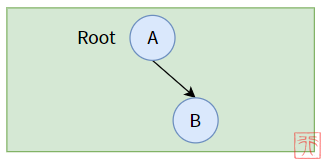
三、左子树为空的二叉树
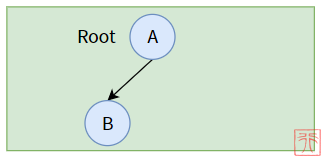
四、右子树为空的二叉树
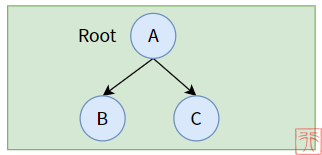
五、左右子树都不为空的二叉树
2.2. 满二叉树和完全二叉树
满二叉树的特点在于“满”,即每层的结点数都是最大结点数。
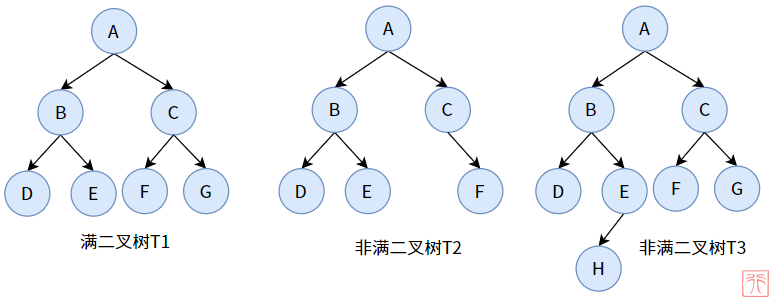
T2 的第 3 层次没有达到最大结点数,缺了 1 个;T3 的第 4 层次没有达到最大结点数,缺了 7 个。
完全二叉树是相对于满二叉树来说的,见下图:
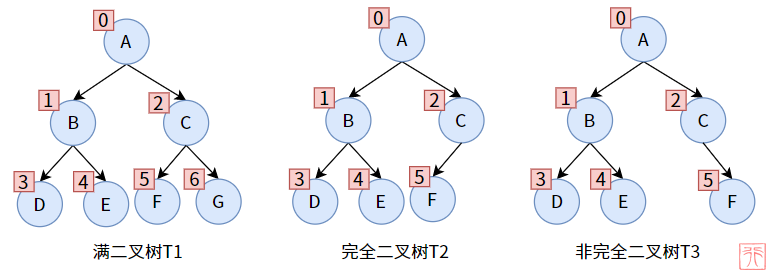
二叉树是有序树,对一颗满二叉树和一颗完全二叉树按「自上向下,自左向右」的顺序进行编号,如上图。
完全二叉树中的所有结点的编号必须和满二叉树的相同编号的结点在位置上完全相同。
换句话说,完全二叉树的结点按「自上向下,自左向右」的顺序不能中断。T3 的结点C 没有左孩子,显然按那个顺序是中断的。
3. 二叉树的遍历
3.0. 如何遍历?
在线性表中,我们的遍历非常简单粗暴,找到线性表头,使用循环直接一股脑的到线性表尾,即完成遍历了。在树中,我们不能在做这么简单粗暴的事了,因为树是一对多的关系,所以从头到尾的遍历是不可能的。
遍历的实质是,将线性排列的元素顺序打印出来。(遍历不止干打印的事,为了方便起见,我们的遍历是打印元素)
而遍历树的矛盾在于,我们的树不是线性的,为了解决这个矛盾,我们可不可以约定好某种顺序,将树的元素按这种顺序线性排列起来,然后遍历就是从头到尾的简单粗暴之事了?答案是可以的。
我们知道树是递归的定义,二叉树是由根结点、左子树、右子树这三部分递归地组合而成的。所以我们要约定的就是这三部分谁先谁后。
按照人们写字先左后右的约定,我们也约定先左子树后右子树的顺序(当然你可以先右后左),那么根结点就只有三个位置可以放了。
- 根结点 >> 左子树 >> 右子树,称为先序(根)遍历
- 左子树 >> 根结点 >> 右子树,称为中序(根)遍历
- 左子树 >> 右子树 >> 根结点,称为后序(根)遍历
约定好之后,只需要按照顺序递归地来就好了,就像找族谱一样。
下面以遍历下图二叉树为例:
为了方便起见,我们将 null 画出来,且将所有子树用颜色标志出来。
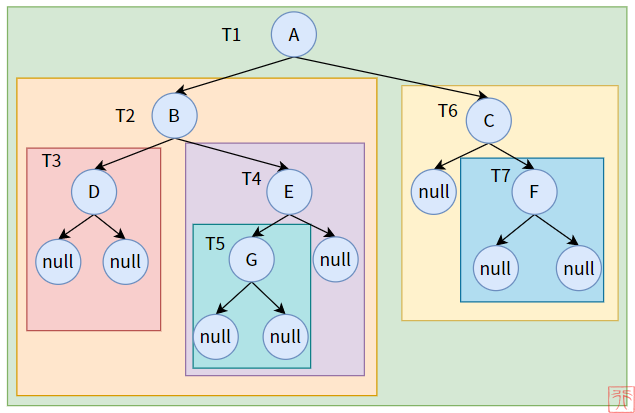
3.1. 先序遍历
先序遍历的递归描述如下:
若二叉树为空,则空操作;否则:
- 访问根结点
- 先序遍历左子树
- 先序遍历右子树
你可能会问,怎么只有访问根结点这一步?左孩子和右孩子结点呢?前面说过一句话:对于每个结点来说,我们都可以将其看作某棵树(子树)的根结点。就像你的儿子会成为别人的父亲一样。所以只要递归地访问根结点,将每个结点递归地变为“根结点”,我们就能完成遍历。
所以与其说是在遍历结点,不如说是在遍历「根结点」,我们只是在递归地把「所有根结点」找出来并输出而已。(因为每个结点都可以看做是根结点)
所以遍历的重点,在于将所有结点转化为根结点看待,又因为每棵树有且仅有一个根结点,所以我们要不断地递归分解子树(先左子树后右子树),直到分解到 NULL 为止。
过程如下:
- T1的根结点为结点A,输出A
- T1的左子树不为空,为T2,进入T2
- T2的根结点为结点B,输出B
- T2的左子树不为空,为T3,进入T3
- T3的根结点为结点D,输出D
- T3的左子树为空,做空操作
- T3的右子树为空,做空操作
- 返回到T2
- T2的右子树不为空,为T4,进入T4
- T4的根结点为结点E,输出E
- T4的左子树不为空,为T5,进入T5
- T5的根结点为结点G,输出G
- T5的左子树为空,做空操作
- T5的右子树为空,做空操作
- 返回到T4
- T4的右子树为空,做空操作
- 返回到T2
- 返回到T1
- T1的右子树不为空,为T6,进入T6
- T6的根结点为结点C,输出C
- T6的左子树为空,做空操作
- T6的右子树不为空,为T7,进入T7
- T7的根结点为结点F,输出F
- T7的左子树为空,做空操作
- T7的右子树为空,做空操作
- 返回到T6
- 返回到T1
- 遍历完成
先序遍历的顺序为:A B D E G C F
如果你感觉文字描述不直观,可以在我以前写过的文章中找到二叉树遍历过程的动态图。
3.2. 中序遍历
中序遍历的递归描述如下:
若二叉树为空,则空操作;否则:
- 中序遍历左子树
- 访问根结点
- 中序遍历右子树
过程如下:
- T1的左子树不为空,为T2,进入T2
- T2的左子树不为空,为T3,进入T3
- T3的左子树为空,做空操作
- T3的根结点为结点D,输出D
- T3的右子树为空,做空操作
- 返回到T2
- T2的根结点为结点B,输出B
- T2的右子树不为空,为T4,进入T4
- T4的左子树不为空,为T5,进入T5
- T5的左子树为空,做空操作
- T5的根结点为结点G,输出G
- T5的右子树为空,做空操作
- 返回到T4
- T4的根结点为结点E,输出E
- T4的右子树为空,做空操作
- 返回到T2
- T4的左子树不为空,为T5,进入T5
- 返回到T1
- T2的左子树不为空,为T3,进入T3
- T1的根结点为结点A,输出A
- T1的右子树不为空,为T6,进入T6
- T6的左子树为空,做空操作
- T6的根结点为结点C,输出C
- T6的右子树不为空,为T7,进入T7
- T7的左子树为空,做空操作
- T7的根结点为结点F,输出F
- T7的右子树为空,做空操作
- 返回到T6
- 返回到T1
- 遍历完成
中序遍历的顺序为:D B G E A C F
3.3. 后序遍历
后序遍历的递归描述如下:
若二叉树为空,则空操作;否则:
- 后序遍历左子树
- 后序遍历右子树
- 访问根结点
过程不再描述,后序遍历的顺序为:D G E B F C A
4. 总结
概念和原理是进行实践的基础,如果这些不了解,那么代码实现就无从下手。
二叉树的概念和原理先介绍到这里。
但是树的相关内容绝不止这一篇文章,后续还会有相关内容。
如有错误,还请指正。
如果觉得写的不错,可以点个赞和关注。后续会有更多数据结构和算法相关文章。













