
点击上方蓝色字体,选择“设为星标”
回复”资源“获取更多资源

来源:https://www.jianshu.com/p/ae308e60220b

点击右侧关注,大数据开发领域最强公众号!


点击右侧关注,暴走大数据!

背景
目前阶段,公司主要监控告警系统使用的是 Zabbix,对于基础设施及应用服务状态监控,Zabbix 内建或由社区贡献了诸多模板,可通过在页面上远程配置或将采集脚本下发至 Zabbix Agent 端进行使用。业务发展至今,除遇到一些并发上的性能问题外,基本能满足我们对于基础硬件、服务设施的监控需求。然而,对于业务类数据,如粒度细至客户分频道的带宽数据,使用 Zabbix 进行监控告警则显得力不从心。
在初期,我们通过自研告警程序来满足部分业务上的需求。如流量、带宽突增突降告警,状态码数量阈值告警等,程序足够轻量并且有效,上线后也着实满足了一些基本业务告警需求。但是,随着告警数据维度的增加以及规则复杂度的上升,迭代开发这个告警程序的代价逐渐变大。一方面,每增加一些需要监控的业务数据,就必需要数据中心提供新的数据接口;另一方面,告警需求所涉及的规则都必需转换为程序代码,无法进行类似 SQL 之类的标准化查询。这两方面都导致每添加一个业务数据的监控告警都需要耗费一定的开发资源,同时业务使用方也较难进行自定义的告警配置。
那么,我们理想中的通用业务监控告警引擎是什么样的呢?针对使用、开发以及未来的可拓展性,我们认为它应该具备如下特点:
1.能够与业务数据源紧密结合,能直接或通过最小的代价从数据源中同步到业务数据集。比如每新增一种业务数据,不再需要通过开发额外的接口进行同步,而只需利用 SQL 便能实时同步数据;
2.具备通用的查询语法,能够以规则匹配的形式从数据源中过滤出所需的数据集,然后使用内置的聚合算子对数据集进行运算,并能以插件的形式增加聚合算子;
3.复杂的告警规则能够通过组合查询条件、聚合算子的形式得以实现;
4.触发告警能够以指定的形式发送至各类告警接收通道;
5.告警引擎可横向拓展部署,满足海量监控需求。
技术预研
由于目前我们的业务数据大部分经过结构化处理存储于 Clickhouse 中,而 Clickhouse 又具备了足够强大的查询聚合能力,因此,最初我们设想能够使用类似存储过程的方式,通过在 Clickhouse 中添加持续进行的 SQL 运算,并结合某种回调触发告警。然而,Clickhouse 本身并不支持存储过程。我们所能做的,是开发一个独立的服务,持续不断从 Clickhouse 中查询业务数据并进行规则匹配。这么做,似乎又回到了老路上,不可取。
于是,换一种思路,既然一个独立的监控告警服务不可避免,那么开源世界中有没有这么一种引擎可直接加以应用呢?经过调研,我们发现 Prometheus是一个绝佳的开源解决方案。Prometheus 最初是由 SoundCloud开发,2016年加入云计算基金会(CNCF),成为 Kubernetes 之后的第二个托管项目。Prometheus 本身被设计为一个高性能的时序数据库,可拉取以标准化形式呈现的数据并进行存储,同时实现了一种称为 PromQL的查询范式,内置数十种聚合算子。此外,Prometheus 还有一个伴生的告警管理组件 AlertManager,可用于管理 Prometheus 发出的告警,并将告警信息分发至相应的接收通道。于是乎,最初需求的第 2~5 点似乎都能立马得到满足,一切看上去都很完美。那么,接下来我们只需实现第1点,即数据源的互通,就能打造我们想要的业务监控告警引擎了。下图为Prometheus 的整体架构。
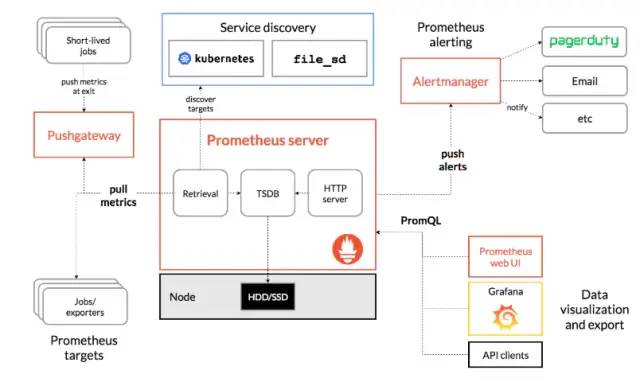
一开始,我们以 Prometheus 标准化导入数据的方式,开发Exporter从 Clickhouse 向 Prometheus 同步数据。由于 Prometheus 本身接收数据采用的是拉取的模式,因此这期间涉及到拉取频率、拉取时效等问题,并且不同的数据集照样需要通过在 Exporter 中添加代码才能进行导出。这种数据同步算不上非常完美。有没有更好的选择呢?进一步探索,我们发现 Prometheus 有个很强大的功能,叫Remote Storage,即只要以特定的协议进行通讯,Prometheus 不一定要将数据存放在自身的数据库中,可也存放在远端的其他数据源中,其工作原理如下图所示。这意味着 Prometheus 可以作为一个纯粹的告警计算引擎使用。于是接下来要做的,是实现将 Clickhouse 作为Prometheus 的 Remote Storage。正当想实现协议时,发现强大的开源世界里已经有人贡献了一波,Prom2Click(https://github.com/mindis/prom2click)

于是,所有的拼图都齐全了,结合现有的数据中心架构,我们想要的通用业务告警引擎的框架如下:
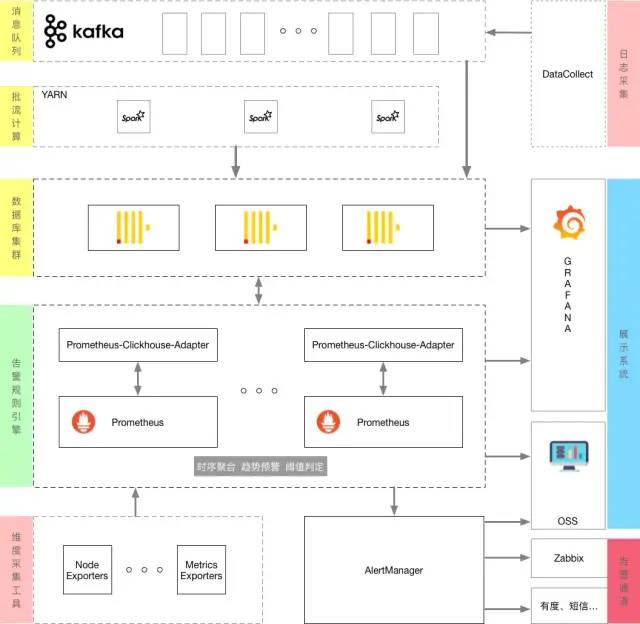
系统构建
Clickhouse 配置
由于 Clickhouse 本身支持类 Graphite 数据表,可定期通过减少时间精度的方式压缩旧数据。我们就以这种数据表类型来存储 Prometheus 的数据。需要在 Clickhouse 集群每个实例的配置文件 config.xml 中最后部分添加如下内容:
<!-- Settings for the ReplicatedGraphiteMergeTree engine. Adjust the retention and rollup entries as needed. --><graphite_rollup> <path_column_name>tags</path_column_name> <time_column_name>ts</time_column_name> <value_column_name>val</value_column_name> <version_column_name>updated</version_column_name> <default> <function>avg</function> <retention> <age>0</age> <precision>10</precision> </retention> <retention> <age>86400</age> <precision>30</precision> </retention> <retention> <age>172800</age> <precision>300</precision> </retention> </default> </graphite_rollup>
数据中间件部署配置
原始版本的 Prom2Click 存在无法支持配置文件、缺少 log 等问题,我们将其定制添加相应功能后已打成 rpm 包放入内部 YUM 源中。执行如下命令进行安装:
1yum install prom2click
修改 Prom2Click 配置 /usr/local/prom2click/etc/config.yml,填写正确的数据库连接信息。然后启动服务
1systemctl start prom2click
Prometheus 部署配置
目前 Prometheus 已下载至内部 YUM 源中,只需执行如下指令安装
1yum install prometheus2 alertmanager
AlertManager 是 Prometheus 用于告警管理的子模块。其本身并不产生告警,而是接收 Prometheus 根据业务规则持续计算产生的告警数据,并对其进行管理和分发至各种通知通道。
完成安装后,在默认情况下启动,Prometheus 会持续采集自身性能数据,并将采集的数据保存在内置的时序数据库中。为了让 Prometheus 能够将数据保存于 Clickhouse 中并加以使用,我们需在 Prometheus 配置文件(默认位于 /etc/prometheus/prometheus.yml)中添加如下配置项。
read_recent: true # 这个参数很重要,不设置会导致 Prometheus 读取 Remote storage 数据有各种异常,之后重载服务
1systemctl reload prometheus
系统运营
回到最初的业务监控需求,当需要配置某种数据源特定维度上的监控规则时,应该怎么做?摒弃先前的开发数据接口以及开发告警规则,我们现在只要在数据源进行简单配置,然后在 Prometheus 端编写规则配置。
数据转换视图
虽然现在业务数据和 Prometheus 所需的数据都在同一数据源内,但其存储的库、表以及结构都不一致,因此我们需要将待监控的业务数据集从各自的库表中导入到 Prometheus 的库表中。Clickhouse 支持 materialized view,以下简称 MV,它能将一张表中的数据执行特定的查询语句后转存至另一张表。以客户、分频道流量表(存放于xcloud 库的 cdn_nginx_log_flow 表中)为例,我们通过建立如下的 MV,将其导入到 metrics 库的 samples 表中。需要注意的是,这个 MV 只会影响到它建立后新插入到 xcloud.cdn_nginx_log_flow 的数据,如需转换先前的数据,需建立一张临时表,然后在这张临时表上建立同样内容不同名称的临时 MV,将旧数据 select 到临时表中进行转换。最后再删除临时 MV 和临时表。
此外有个风险点是,一旦 MV 的执行逻辑有问题,则会使数据插入到原始表中出错。因此新建 MV 前必须确保逻辑的正确性,可现在内网环境中以测试表进行验证。后续将通过工具进行校验 MV 的合法性。
以上 MV 将会产生一个名称为 cdn_customer_flow 的关于客户、分频道流量的度量指标(metric),其数据维度有 customer, channel, view 和 serverType 这四个。在 Prometheus 的查询页面,我们可通过 PromQL 来对这个度量指标进行查询,如以下语句
1sum by (channel) (sum_over_time(cdn_customer_flow{serverType='0'}[5m]))
可查询最近 5m 各分频道流量的加总。
告警规则配置
在建立数据转换视图后,一旦有新数据插入到原始表,MV 便会持续不断将其变换为 Prometheus 数据表所需格式。此时我们可在 Prometheus 中以标准的规则配置方法对该度量指标进行监控。以下是简要的 Prometheus 配置
则通过 expr 内的计算公式,我们定义了一条告警规则,其内容为:无论哪个客户,只要最近5分钟带宽超过150Mbps,且最近5分钟与上一个5分钟带宽均值变化率超过 10%,则触发告警。Promethues 的告警会由 Alertmanager 进行接收,通过匹配告警名称、标签等,可将告警路由分发至不同的告警通道,比如我们可以定义一个CDN 告警的邮件组专门用于接收以上的告警邮件。
Prometheus 的告警规则很强大,更多的资料可参考官方文档,或是一些不错的第三方文档。
后记
通过以上步骤,我们可以配置绝大多数业务数据的监控规则,利用 Prometheus 的算子,我们甚至可以对某些维度的数据进行预测型监控。但不可否认的是,目前 Prometheus 无论是查询语言或是告警规则的配置,都有一定的学习门槛。我们后续需要做的事,是将整个流程尽可能地界面化,通过在网页页面上选定数据维度、聚合公式、触发阈值、告警通道,来生成相应的告警规则,从而减轻运营人员的操作门槛,让整个系统更易运营。
欢迎点赞+收藏+转发朋友圈素质三连

文章不错?点个【在看】吧!** 👇**
本文分享自微信公众号 - 大数据技术与架构(import_bigdata)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。






