
以下内容出自小程序「编程面试题库」

0 遇到过得反爬虫策略以及解决方法?
1.通过headers反爬虫
2.基于用户行为的发爬虫:(同一IP短时间内访问的频率)
3.动态网页反爬虫(通过ajax请求数据,或者通过JavaScript生成)
4.对部分数据进行加密处理的(数据是乱码)
解决方法:
对于基本网页的抓取可以自定义headers,添加headers的数据
使用多个代理ip进行抓取或者设置抓取的频率降低一些,
动态网页的可以使用selenium + phantomjs 进行抓取
对部分数据进行加密的,可以使用selenium进行截图,使用python自带的pytesseract库进行识别,但是比较慢最直接的方法是找到加密的方法进行逆向推理。
1 urllib 和 urllib2 的区别?
urllib 和urllib2都是接受URL请求的相关模块,但是urllib2可以接受一个Request类的实例来设置URL请求的headers,urllib仅可以接受URL。urllib不可以伪装你的User-Agent字符串。
urllib提供urlencode()方法用来GET查询字符串的产生,而urllib2没有。这是为何urllib常和urllib2一起使用的原因。
2 列举网络爬虫所用到的网络数据包,解析包?
网络数据包 urllib、urllib2、requests
解析包 re、xpath、beautiful soup、lxml
3 简述一下爬虫的步骤?
确定需求;
确定资源;
通过url获取网站的返回数据;
定位数据;
存储数据。
4 遇到反爬机制怎么处理?
反爬机制:
headers方向
判断User-Agent、判断Referer、判断Cookie。
将浏览器的headers信息全部添加进去
注意:Accept-Encoding;gzip,deflate需要注释掉
5 常见的HTTP方法有哪些?
GET:请求指定的页面信息,返回实体主体;
HEAD:类似于get请求,只不过返回的响应中没有具体的内容,用于捕获报头;
POST:向指定资源提交数据进行处理请求(比如表单提交或者上传文件),。数据被包含在请求体中。
PUT:从客户端向服务端传送数据取代指定的文档的内容;
DELETE:请求删除指定的页面;
CONNNECT:HTTP1.1协议中预留给能够将连接方式改为管道方式的代理服务器;
OPTIONS:允许客户端查看服务器的性能;
TRACE:回显服务器的请求,主要用于测试或者诊断。
6 说一说redis-scrapy中redis的作用?
它是将scrapy框架中Scheduler替换为redis数据库,实现队列管理共享。
优点:
可以充分利用多台机器的带宽;
可以充分利用多台机器的IP地址。
7 遇到的反爬虫策略以及解决方法?
通过headers反爬虫:自定义headers,添加网页中的headers数据。
基于用户行为的反爬虫(封IP):可以使用多个代理IP爬取或者将爬取的频率降低。
动态网页反爬虫(JS或者Ajax请求数据):动态网页可以使用 selenium + phantomjs 抓取。
对部分数据加密处理(数据乱码):找到加密方法进行逆向推理。
8 如果让你来防范网站爬虫,你应该怎么来提高爬取的难度 ?
判断headers的User-Agent;
检测同一个IP的访问频率;
数据通过Ajax获取;
爬取行为是对页面的源文件爬取,如果要爬取静态网页的html代码,可以使用jquery去模仿写html。
9 scrapy分为几个组成部分?分别有什么作用?
分为5个部分;Spiders(爬虫类),Scrapy Engine(引擎),Scheduler(调度器),Downloader(下载器),Item Pipeline(处理管道)。
Spiders:开发者自定义的一个类,用来解析网页并抓取指定url返回的内容。
Scrapy Engine:控制整个系统的数据处理流程,并进行事务处理的触发。
Scheduler:接收Engine发出的requests,并将这些requests放入到处理列队中,以便之后engine需要时再提供。
Download:抓取网页信息提供给engine,进而转发至Spiders。
Item Pipeline:负责处理Spiders类提取之后的数据。
比如清理HTML数据、验证爬取的数据(检查item包含某些字段)、查重(并丢弃)、将爬取结果保存到数据库中
10 简述一下scrapy的基本流程?
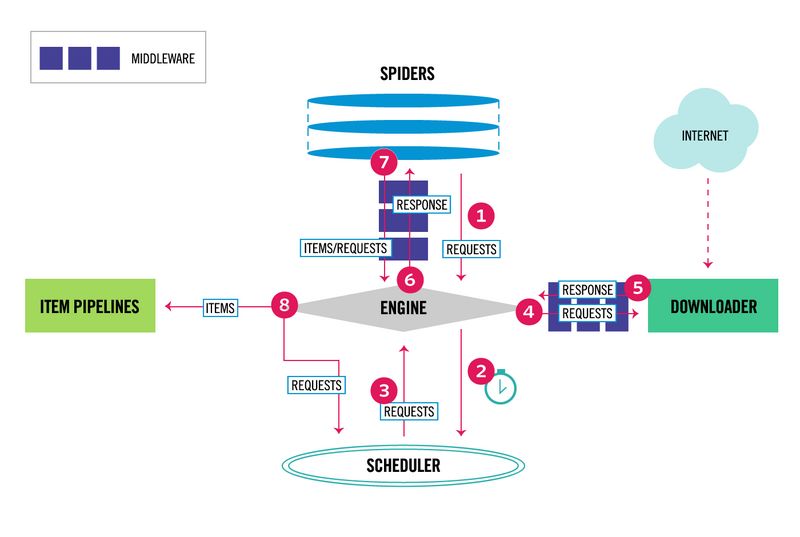
scrapy分为9个步骤:
Spiders需要初始的start_url或则函数stsrt_requests,会在内部生成Requests给Engine;
Engine将requests发送给Scheduler;
Engine从Scheduler那获取requests,交给Download下载;
在交给Dowmload过程中会经过Downloader Middlewares(经过process_request函数);
Dowmloader下载页面后生成一个response,这个response会传给Engine,这个过程中又经过了Downloader Middlerwares(经过process_request函数),在传送中出错的话经过process_exception函数;
Engine将从Downloader那传送过来的response发送给Spiders处理,这个过程经过Spiders Middlerwares(经过process_spider_input函数);
Spiders处理这个response,返回Requests或者Item两个类型,传给Engine,这个过程又经过Spiders Middlewares(经过porcess_spider_output函数);
Engine接收返回的信息,如果使Item,将它传给Items Pipeline中;如果是Requests,将它传给Scheduler,继续爬虫;
重复第三步,直至没有任何需要爬取的数据
11 python3.5语言中enumerate的意思是
对于一个可迭代的(iterable)/可遍历的对象(如列表、字符串),enumerate将其组成一个索引序列,利用它可以同时获得索引和值
enumerate多用于在for循环中得到计数
12 你是否了解谷歌的无头浏览器?
无头浏览器即headless browser,是一种没有界面的浏览器。既然是浏览器那么浏览器该有的东西它都应该有,只是看不到界面而已。
Python中selenium模块中的PhantomJS即为无界面浏览器(无头浏览器):是基于QtWebkit的无头浏览器。
13 scrapy和scrapy-redis的区别?
scrapy是一个爬虫通用框架,但不支持分布式,scrapy-redis是为了更方便的实现scrapy分布式爬虫,而提供了一些以redis为基础的组件
为什么会选择redis数据库?
因为redis支持主从同步,而且数据都是缓存在内存中,所以基于redis的分布式爬虫,对请求和数据的高频读取效率非常高
什么是主从同步?
在Redis中,用户可以通过执行SLAVEOF命令或者设置slaveof选项,让一个服务器去复制(replicate)另一个服务器,我们称呼被复制的服务器为主服务器(master),而对主服务器进行复制的服务器则被称为从服务器(slave),当客户端向从服务器发送SLAVEOF命令,要求从服务器复制主服务器时,从服务器首先需要执行同步操作,也即是,将从服务器的数据库状态更新至主服务器当前所处的数据库状态
14 scrapy的优缺点?为什么要选择scrapy框架?
优点:
采取可读性更强的xpath代替正则 强大的统计和log系统 同时在不同的url上爬行 支持shell方式,方便独立调试 写middleware,方便写一些统一的过滤器 通过管道的方式存入数据库
缺点:
基于python爬虫框架,扩展性比较差,基于twisted框架,运行中exception是不会干掉reactor,并且异步框架出错后是不会停掉其他任务的,数据出错后难以察觉
15 scrapy和requests的使用情况?
requests 是 polling 方式的,会被网络阻塞,不适合爬取大量数据
scapy 底层是异步框架 twisted ,并发是最大优势
16 描述一下scrapy框架的运行机制?
从start_urls里面获取第一批url发送请求,请求由请求引擎给调度器入请求对列,获取完毕后,调度器将请求对列交给下载器去获取请求对应的响应资源,并将响应交给自己编写的解析方法做提取处理,如果提取出需要的数据,则交给管道处理,如果提取出url,则继续执行之前的步骤,直到多列里没有请求,程序结束。
17 写爬虫使用多进程好,还是用多线程好?
IO密集型代码(文件处理、网络爬虫等),多线程能够有效提升效率(单线程下有IO操作会进行IO等待,造成不必要的时间浪费,而开启多线程能在线程A等待时,自动切换到线程B,可以不浪费CPU的资源,从而能提升程序执行效率)。在实际的数据采集过程中,既考虑网速和响应的问题,也需要考虑自身机器的硬件情况,来设置多进程或多线程
18 常见的反爬虫和应对方法?
基于用户行为,同一个ip段时间多次访问同一页面 利用代理ip,构建ip池
请求头里的user-agent 构建user-agent池(操作系统、浏览器不同,模拟不同用户)
动态加载(抓到的数据和浏览器显示的不一样),js渲染 模拟ajax请求,返回json形式的数据
selenium / webdriver 模拟浏览器加载
对抓到的数据进行分析
加密参数字段 会话跟踪【cookie】 防盗链设置【Referer
19 分布式爬虫主要解决什么问题?
面对海量待抓取网页,只有采用分布式架构,才有可能在较短时间内完成一轮抓取工作。
它的开发效率是比较快而且简单的。
20 如何提高爬取效率?
爬虫下载慢主要原因是阻塞等待发往网站的请求和网站返回
1,采用异步与多线程,扩大电脑的cpu利用率; 2,采用消息队列模式 3,提高带宽
21 说说什么是爬虫协议?
Robots协议(也称为爬虫协议、爬虫规则、机器人协议等)也就是robots.txt,网站通过robots协议告诉搜索引擎哪些页面可以抓取,哪些页面不能抓取。
Robots协议是网站国际互联网界通行的道德规范,其目的是保护网站数据和敏感信息、确保用户个人信息和隐私不被侵犯。因其不是命令,故需要搜索引擎自觉遵守。
22 如果对方网站反爬取,封IP了怎么办?
放慢抓取熟速度,减小对目标网站造成的压力,但是这样会减少单位时间内的数据抓取量
使用代理IP(免费的可能不稳定,收费的可能不划算)
23 有一个jsonline格式的文件file
def get_lines(): with open('file.txt','rb') as f: return f.readlines()if __name__ == '__main__': for e in get_lines(): process(e) # 处理每一行数据
现在要处理一个大小为10G的文件,但是内存只有4G,如果在只修改get_lines 函数而其他代码保持不变的情况下,应该如何实现?需要考虑的问题都有那些?
def get_lines(): with open('file.txt','rb') as f: for i in f: yield i
Pandaaaa906提供的方法
from mmap import mmapdef get_lines(fp): with open(fp,"r+") as f: m = mmap(f.fileno(), 0) tmp = 0 for i, char in enumerate(m): if char==b"\n": yield m[tmp:i+1].decode() tmp = i+1if __name__=="__main__": for i in get_lines("fp_some_huge_file"): print(i)
要考虑的问题有:内存只有4G无法一次性读入10G文件,需要分批读入分批读入数据要记录每次读入数据的位置。分批每次读取数据的大小,太小会在读取操作花费过多时间。
https://stackoverflow.com/questions/30294146/python-fastest-way-to-process-large-file
24 补充缺失的代码
def print_directory_contents(sPath):"""这个函数接收文件夹的名称作为输入参数返回该文件夹中文件的路径以及其包含文件夹中文件的路径"""import osfor s_child in os.listdir(s_path): s_child_path = os.path.join(s_path, s_child) if os.path.isdir(s_child_path): print_directory_contents(s_child_path) else: print(s_child_path)
25 输入日期, 判断这一天是这一年的第几天?
import datetimedef dayofyear(): year = input("请输入年份: ") month = input("请输入月份: ") day = input("请输入天: ") date1 = datetime.date(year=int(year),month=int(month),day=int(day)) date2 = datetime.date(year=int(year),month=1,day=1) return (date1-date2).days+1
26 打乱一个排好序的list对象alist?
import randomalist = [1,2,3,4,5]random.shuffle(alist)print(alist)
27 现有字典 d= {'a':24,'g':52,'i':12,'k':33}请按value值进行排序?
sorted(d.items(),key=lambda x:x[1])
28 字典推导式
d = {key:value for (key,value) in iterable}
29 请反转字符串 "aStr"?
print("aStr"[::-1])
30 将字符串 "k:1 |k1:2|k2:3|k3:4",处理成字典
str1 = "k:1|k1:2|k2:3|k3:4"def str2dict(str1): dict1 = {} for iterms in str1.split('|'): key,value = iterms.split(':') dict1[key] = value return dict1#字典推导式d = {k:int(v) for t in str1.split("|") for k, v in (t.split(":"), )}
31 请按alist中元素的age由大到小排序
alist = [{'name':'a','age':20},{'name':'b','age':30},{'name':'c','age':25}]def sort_by_age(list1): return sorted(alist,key=lambda x:x['age'],reverse=True)
32 下面代码的输出结果将是什么?
list = ['a','b','c','d','e']print(list[10:])
代码将输出[],不会产生IndexError错误,就像所期望的那样,尝试用超出成员的个数的index来获取某个列表的成员。例如,尝试获取list[10]和之后的成员,会导致IndexError。然而,尝试获取列表的切片,开始的index超过了成员个数不会产生IndexError,而是仅仅返回一个空列表。这成为特别让人恶心的疑难杂症,因为运行的时候没有错误产生,导致Bug很难被追踪到。
33 写一个列表生成式,产生一个公差为11的等差数列
print([x*11 for x in range(10)])
34 给定两个列表,怎么找出他们相同的元素和不同的元素?
list1 = [1,2,3]list2 = [3,4,5]set1 = set(list1)set2 = set(list2)print(set1 & set2)print(set1 ^ set2)
35 请写出一段python代码实现删除list里面的重复元素?
l1 = ['b','c','d','c','a','a']l2 = list(set(l1))print(l2)
用list类的sort方法:
l1 = ['b','c','d','c','a','a']l2 = list(set(l1))l2.sort(key=l1.index)print(l2)
也可以这样写:
l1 = ['b','c','d','c','a','a']l2 = sorted(set(l1),key=l1.index)print(l2)
也可以用遍历:
l1 = ['b','c','d','c','a','a']l2 = []for i in l1: if not i in l2: l2.append(i)print(l2)
36 给定两个list A,B ,请用找出A,B中相同与不同的元素
A,B 中相同元素: print(set(A)&set(B))A,B 中不同元素: print(set(A)^set(B))
37 python新式类和经典类的区别?
a. 在python里凡是继承了object的类,都是新式类
b. Python3里只有新式类
c. Python2里面继承object的是新式类,没有写父类的是经典类
d. 经典类目前在Python里基本没有应用
38 python中内置的数据结构有几种?
a. 整型 int、 长整型 long、浮点型 float、 复数 complex
b. 字符串 str、 列表 list、 元祖 tuple
c. 字典 dict 、 集合 set
d. Python3 中没有 long,只有无限精度的 int
39 python如何实现单例模式?请写出两种实现方式?
第一种方法:使用装饰器
def singleton(cls): instances = {} def wrapper(*args, **kwargs): if cls not in instances: instances[cls] = cls(*args, **kwargs) return instances[cls] return wrapper@singletonclass Foo(object): passfoo1 = Foo()foo2 = Foo()print(foo1 is foo2) # True
第二种方法:使用基类
New 是真正创建实例对象的方法,所以重写基类的new 方法,以此保证创建对象的时候只生成一个实例
class Singleton(object): def __new__(cls, *args, **kwargs): if not hasattr(cls, '_instance'): cls._instance = super(Singleton, cls).__new__(cls, *args, **kwargs) return cls._instanceclass Foo(Singleton): passfoo1 = Foo()foo2 = Foo()print(foo1 is foo2) # True
第三种方法:元类,元类是用于创建类对象的类,类对象创建实例对象时一定要调用call方法,因此在调用call时候保证始终只创建一个实例即可,type是python的元类
class Singleton(type): def __call__(cls, *args, **kwargs): if not hasattr(cls, '_instance'): cls._instance = super(Singleton, cls).__call__(*args, **kwargs) return cls._instance# Python2class Foo(object): __metaclass__ = Singleton# Python3class Foo(metaclass=Singleton): passfoo1 = Foo()foo2 = Foo()print(foo1 is foo2) # True
40 反转一个整数,例如-123 --> -321
class Solution(object): def reverse(self,x): if -10<x<10: return x str_x = str(x) if str_x[0] !="-": str_x = str_x[::-1] x = int(str_x) else: str_x = str_x[1:][::-1] x = int(str_x) x = -x return x if -2147483648<x<2147483647 else 0if __name__ == '__main__': s = Solution() reverse_int = s.reverse(-120) print(reverse_int)
41 设计实现遍历目录与子目录,抓取.pyc文件?
第一种方法:
import osdef get_files(dir,suffix): res = [] for root,dirs,files in os.walk(dir): for filename in files: name,suf = os.path.splitext(filename) if suf == suffix: res.append(os.path.join(root,filename)) print(res)get_files("./",'.pyc')
第二种方法:
import osdef pick(obj): if ob.endswith(".pyc"): print(obj)def scan_path(ph): file_list = os.listdir(ph) for obj in file_list: if os.path.isfile(obj): pick(obj) elif os.path.isdir(obj): scan_path(obj)if __name__=='__main__': path = input('输入目录') scan_path(path)
第三种方法
from glob import iglobdef func(fp, postfix): for i in iglob(f"{fp}/**/*{postfix}", recursive=True): print(i)if __name__ == "__main__": postfix = ".pyc" func("K:\Python_script", postfix)
42 Python-遍历列表时删除元素的正确做法
遍历在新在列表操作,删除时在原来的列表操作
a = [1,2,3,4,5,6,7,8]print(id(a))print(id(a[:]))for i in a[:]: if i>5: pass else: a.remove(i) print(a)print('-----------')print(id(a))
#filtera=[1,2,3,4,5,6,7,8]b = filter(lambda x: x>5,a)print(list(b))
列表解析
a=[1,2,3,4,5,6,7,8]b = [i for i in a if i>5]print(b)
倒序删除
因为列表总是‘向前移’,所以可以倒序遍历,即使后面的元素被修改了,还没有被遍历的元素和其坐标还是保持不变的
a=[1,2,3,4,5,6,7,8]print(id(a))for i in range(len(a)-1,-1,-1): if a[i]>5: pass else: a.remove(a[i])print(id(a))print('-----------')print(a)
43 字符串的操作题目
全字母短句 PANGRAM 是包含所有英文字母的句子,比如:A QUICK BROWN FOX JUMPS OVER THE LAZY DOG. 定义并实现一个方法 get_missing_letter, 传入一个字符串采纳数,返回参数字符串变成一个 PANGRAM 中所缺失的字符。应该忽略传入字符串参数中的大小写,返回应该都是小写字符并按字母顺序排序(请忽略所有非 ACSII 字符)
下面示例是用来解释,双引号不需要考虑:
(0)输入: "A quick brown for jumps over the lazy dog"
返回: ""
(1)输入: "A slow yellow fox crawls under the proactive dog"
返回: "bjkmqz"
(2)输入: "Lions, and tigers, and bears, oh my!"
返回: "cfjkpquvwxz"
(3)输入: ""
返回:"abcdefghijklmnopqrstuvwxyz"
def get_missing_letter(a): s1 = set("abcdefghijklmnopqrstuvwxyz") s2 = set(a) ret = "".join(sorted(s1-s2)) return retprint(get_missing_letter("python"))
44 可变类型和不可变类型
1,可变类型有list,dict.不可变类型有string,number,tuple.
2,当进行修改操作时,可变类型传递的是内存中的地址,也就是说,直接修改内存中的值,并没有开辟新的内存。
3,不可变类型被改变时,并没有改变原内存地址中的值,而是开辟一块新的内存,将原地址中的值复制过去,对这块新开辟的内存中的值进行操作。
45 is和==有什么区别?
is:比较的是两个对象的id值是否相等,也就是比较俩对象是否为同一个实例对象。是否指向同一个内存地址
== : 比较的两个对象的内容/值是否相等,默认会调用对象的eq()方法
46 求出列表所有奇数并构造新列表
a = [1,2,3,4,5,6,7,8,9,10]res = [ i for i in a if i%2==1]print(res)
47 用一行python代码写出1+2+3+10248
from functools import reduce#1.使用sum内置求和函数num = sum([1,2,3,10248])print(num)#2.reduce 函数num1 = reduce(lambda x,y :x+y,[1,2,3,10248])print(num1)
48 Python中变量的作用域?(变量查找顺序)
函数作用域的LEGB顺序
1.什么是LEGB?
L: local 函数内部作用域
E: enclosing 函数内部与内嵌函数之间
G: global 全局作用域
B: build-in 内置作用
python在函数里面的查找分为4种,称之为LEGB,也正是按照这是顺序来查找的
49 字符串 `"123"` 转换成 `123`,不使用内置api,例如 `int()`
方法一: 利用 str 函数
def atoi(s): num = 0 for v in s: for j in range(10): if v == str(j): num = num * 10 + j return num
方法二: 利用 ord 函数
def atoi(s): num = 0 for v in s: num = num * 10 + ord(v) - ord('0') return num
方法三: 利用 eval 函数
def atoi(s): num = 0 for v in s: t = "%s * 1" % v n = eval(t) num = num * 10 + n return num
方法四: 结合方法二,使用 reduce,一行解决
from functools import reducedef atoi(s): return reduce(lambda num, v: num * 10 + ord(v) - ord('0'), s, 0)
50 Given an array of integers
给定一个整数数组和一个目标值,找出数组中和为目标值的两个数。你可以假设每个输入只对应一种答案,且同样的元素不能被重复利用。示例:给定nums = [2,7,11,15],target=9 因为 nums[0]+nums[1] = 2+7 =9,所以返回[0,1]
class Solution: def twoSum(self,nums,target): """ :type nums: List[int] :type target: int :rtype: List[int] """ d = {} size = 0 while size < len(nums): if target-nums[size] in d: if d[target-nums[size]] <size: return [d[target-nums[size]],size] else: d[nums[size]] = size size = size +1solution = Solution()list = [2,7,11,15]target = 9nums = solution.twoSum(list,target)print(nums)
给列表中的字典排序:假设有如下list对象,alist=[{"name":"a","age":20},{"name":"b","age":30},{"name":"c","age":25}],将alist中的元素按照age从大到小排序 alist=[{"name":"a","age":20},{"name":"b","age":30},{"name":"c","age":25}]
alist_sort = sorted(alist,key=lambda e: e.__getitem__('age'),reverse=True)
51 python代码实现删除一个list里面的重复元素
def distFunc1(a): """使用集合去重""" a = list(set(a)) print(a)def distFunc2(a): """将一个列表的数据取出放到另一个列表中,中间作判断""" list = [] for i in a: if i not in list: list.append(i) #如果需要排序的话用sort list.sort() print(list)def distFunc3(a): """使用字典""" b = {} b = b.fromkeys(a) c = list(b.keys()) print(c)if __name__ == "__main__": a = [1,2,4,2,4,5,7,10,5,5,7,8,9,0,3] distFunc1(a) distFunc2(a) distFunc3(a)
52 统计一个文本中单词频次最高的10个单词?
import re# 方法一def test(filepath): distone = {} with open(filepath) as f: for line in f: line = re.sub("\W+", " ", line) lineone = line.split() for keyone in lineone: if not distone.get(keyone): distone[keyone] = 1 else: distone[keyone] += 1 num_ten = sorted(distone.items(), key=lambda x:x[1], reverse=True)[:10] num_ten =[x[0] for x in num_ten] return num_ten# 方法二 # 使用 built-in 的 Counter 里面的 most_commonimport refrom collections import Counterdef test2(filepath): with open(filepath) as f: return list(map(lambda c: c[0], Counter(re.sub("\W+", " ", f.read()).split()).most_common(10)))
53 请写出一个函数满足以下条件
该函数的输入是一个仅包含数字的list,输出一个新的list,其中每一个元素要满足以下条件:
1、该元素是偶数
2、该元素在原list中是在偶数的位置(index是偶数)
def num_list(num): return [i for i in num if i %2 ==0 and num.index(i)%2==0]num = [0,1,2,3,4,5,6,7,8,9,10]result = num_list(num)print(result)
54 使用单一的列表生成式来产生一个新的列表
该列表只包含满足以下条件的值,元素为原始列表中偶数切片
list_data = [1,2,5,8,10,3,18,6,20]res = [x for x in list_data[::2] if x %2 ==0]print(res)
55 用一行代码生成[1,4,9,16,25,36,49,64,81,100]
[x * x for x in range(1,11)]
56 输入某年某月某日,判断这一天是这一年的第几天?
import datetimey = int(input("请输入4位数字的年份:"))m = int(input("请输入月份:"))d = int(input("请输入是哪一天"))targetDay = datetime.date(y,m,d)dayCount = targetDay - datetime.date(targetDay.year -1,12,31)print("%s是 %s年的第%s天。"%(targetDay,y,dayCount.days))
57 两个有序列表,l1,l2,对这两个列表进行合并不可使用extend
def loop_merge_sort(l1,l2): tmp = [] while len(l1)>0 and len(l2)>0: if l1[0] <l2[0]: tmp.append(l1[0]) del l1[0] else: tmp.append(l2[0]) del l2[0] while len(l1)>0: tmp.append(l1[0]) del l1[0] while len(l2)>0: tmp.append(l2[0]) del l2[0] return tmp
58 给定一个任意长度数组,实现一个函数
让所有奇数都在偶数前面,而且奇数升序排列,偶数降序排序,如字符串'1982376455',变成'1355798642'
# 方法一def func1(l): if isinstance(l, str): l = [int(i) for i in l] l.sort(reverse=True) for i in range(len(l)): if l[i] % 2 > 0: l.insert(0, l.pop(i)) print(''.join(str(e) for e in l))# 方法二def func2(l): print("".join(sorted(l, key=lambda x: int(x) % 2 == 0 and 20 - int(x) or int(x))))
59 写一个函数找出一个整数数组中,第二大的数
def find_second_large_num(num_list): """ 找出数组第2大的数字 """ # 方法一 # 直接排序,输出倒数第二个数即可 tmp_list = sorted(num_list) print("方法一\nSecond_large_num is :", tmp_list[-2]) # 方法二 # 设置两个标志位一个存储最大数一个存储次大数 # two 存储次大值,one 存储最大值,遍历一次数组即可,先判断是否大于 one,若大于将 one 的值给 two,将 num_list[i] 的值给 one,否则比较是否大于two,若大于直接将 num_list[i] 的值给two,否则pass one = num_list[0] two = num_list[0] for i in range(1, len(num_list)): if num_list[i] > one: two = one one = num_list[i] elif num_list[i] > two: two = num_list[i] print("方法二\nSecond_large_num is :", two) # 方法三 # 用 reduce 与逻辑符号 (and, or) # 基本思路与方法二一样,但是不需要用 if 进行判断。 from functools import reduce num = reduce(lambda ot, x: ot[1] < x and (ot[1], x) or ot[0] < x and (x, ot[1]) or ot, num_list, (0, 0))[0] print("方法三\nSecond_large_num is :", num)if __name__ == '__main___': num_list = [34, 11, 23, 56, 78, 0, 9, 12, 3, 7, 5] find_second_large_num(num_list)
60 阅读一下代码他们的输出结果是什么?
def multi(): return [lambda x : i*x for i in range(4)]print([m(3) for m in multi()])
正确答案是[9,9,9,9],而不是[0,3,6,9]产生的原因是Python的闭包的后期绑定导致的,这意味着在闭包中的变量是在内部函数被调用的时候被查找的,因为,最后函数被调用的时候,for循环已经完成, i 的值最后是3,因此每一个返回值的i都是3,所以最后的结果是[9,9,9,9]
61 统计一段字符串中字符出现的次数
# 方法一def count_str(str_data): """定义一个字符出现次数的函数""" dict_str = {} for i in str_data: dict_str[i] = dict_str.get(i, 0) + 1 return dict_strdict_str = count_str("AAABBCCAC")str_count_data = ""for k, v in dict_str.items(): str_count_data += k + str(v)print(str_count_data)# 方法二from collections import Counterprint("".join(map(lambda x: x[0] + str(x[1]), Counter("AAABBCCAC").most_common())))
62 Python中类方法、类实例方法、静态方法有何区别?
类方法: 是类对象的方法,在定义时需要在上方使用 @classmethod 进行装饰,形参为cls,表示类对象,类对象和实例对象都可调用
类实例方法: 是类实例化对象的方法,只有实例对象可以调用,形参为self,指代对象本身;
静态方法: 是一个任意函数,在其上方使用 @staticmethod 进行装饰,可以用对象直接调用,静态方法实际上跟该类没有太大关系
63 遍历一个object的所有属性,并print每一个属性名?
class Car: def __init__(self,name,loss): # loss [价格,油耗,公里数] self.name = name self.loss = loss def getName(self): return self.name def getPrice(self): # 获取汽车价格 return self.loss[0] def getLoss(self): # 获取汽车损耗值 return self.loss[1] * self.loss[2]Bmw = Car("宝马",[60,9,500]) # 实例化一个宝马车对象print(getattr(Bmw,"name")) # 使用getattr()传入对象名字,属性值。print(dir(Bmw)) # 获Bmw所有的属性和方法
64 写一个类,并让它尽可能多的支持操作符?
class Array: __list = [] def __init__(self): print "constructor" def __del__(self): print "destruct" def __str__(self): return "this self-defined array class" def __getitem__(self,key): return self.__list[key] def __len__(self): return len(self.__list) def Add(self,value): self.__list.append(value) def Remove(self,index): del self.__list[index] def DisplayItems(self): print "show all items---" for item in self.__list: print item
65 关于Python内存管理,下列说法错误的是 B
A,变量不必事先声明 B,变量无须先创建和赋值而直接使用
C,变量无须指定类型 D,可以使用del释放资源
66 Python的内存管理机制及调优手段?
内存管理机制: 引用计数、垃圾回收、内存池
引用计数:引用计数是一种非常高效的内存管理手段,当一个Python对象被引用时其引用计数增加1,
当其不再被一个变量引用时则计数减1,当引用计数等于0时对象被删除。弱引用不会增加引用计数
垃圾回收:
1.引用计数
引用计数也是一种垃圾收集机制,而且也是一种最直观、最简单的垃圾收集技术。当Python的某个对象的引用计数降为0时,说明没有任何引用指向该对象,该对象就成为要被回收的垃圾了。比如某个新建对象,它被分配给某个引用,对象的引用计数变为1,如果引用被删除,对象的引用计数为0,那么该对象就可以被垃圾回收。不过如果出现循环引用的话,引用计数机制就不再起有效的作用了。
2.标记清除
调优手段
1.手动垃圾回收
2.调高垃圾回收阈值
3.避免循环引用
67 内存泄露是什么?如何避免?
内存泄漏指由于疏忽或错误造成程序未能释放已经不再使用的内存。内存泄漏并非指内存在物理上的消失,而是应用程序分配某段内存后,由于设计错误,导致在释放该段内存之前就失去了对该段内存的控制,从而造成了内存的浪费。
有__del__()函数的对象间的循环引用是导致内存泄露的主凶。不使用一个对象时使用: del object 来删除一个对象的引用计数就可以有效防止内存泄露问题。
通过Python扩展模块gc 来查看不能回收的对象的详细信息。
可以通过 sys.getrefcount(obj) 来获取对象的引用计数,并根据返回值是否为0来判断是否内存泄露
68 python常见的列表推导式?
[表达式 for 变量 in 列表] 或者 [表达式 for 变量 in 列表 if 条件]
69 简述read、readline、readlines的区别?
read 读取整个文件
readline 读取下一行
readlines 读取整个文件到一个迭代器以供我们遍历
70 什么是Hash(散列函数)?
散列函数(英语:Hash function)又称散列算法、哈希函数,是一种从任何一种数据中创建小的数字“指纹”的方法。散列函数把消息或数据压缩成摘要,使得数据量变小,将数据的格式固定下来。该函数将数据打乱混合,重新创建一个叫做散列值(hash values,hash codes,hash sums,或hashes)的指纹。散列值通常用一个短的随机字母和数字组成的字符串来代表
71 python函数重载机制?
函数重载主要是为了解决两个问题。
1。可变参数类型。
2。可变参数个数。
另外,一个基本的设计原则是,仅仅当两个函数除了参数类型和参数个数不同以外,其功能是完全相同的,此时才使用函数重载,如果两个函数的功能其实不同,那么不应当使用重载,而应当使用一个名字不同的函数。
好吧,那么对于情况 1 ,函数功能相同,但是参数类型不同,python 如何处理?答案是根本不需要处理,因为 python 可以接受任何类型的参数,如果函数的功能相同,那么不同的参数类型在 python 中很可能是相同的代码,没有必要做成两个不同函数。
那么对于情况 2 ,函数功能相同,但参数个数不同,python 如何处理?大家知道,答案就是缺省参数。对那些缺少的参数设定为缺省参数即可解决问题。因为你假设函数功能相同,那么那些缺少的参数终归是需要用的。
好了,鉴于情况 1 跟 情况 2 都有了解决方案,python 自然就不需要函数重载了。
72 手写一个判断时间的装饰器
import datetimeclass TimeException(Exception): def __init__(self, exception_info): super().__init__() self.info = exception_info def __str__(self): return self.infodef timecheck(func): def wrapper(*args, **kwargs): if datetime.datetime.now().year == 2019: func(*args, **kwargs) else: raise TimeException("函数已过时") return wrapper@timecheckdef test(name): print("Hello {}, 2019 Happy".format(name))if __name__ == "__main__": test("backbp")
73 使用Python内置的filter()方法来过滤?
list(filter(lambda x: x % 2 == 0, range(10)))
74 编写函数的4个原则
1.函数设计要尽量短小
2.函数声明要做到合理、简单、易于使用
3.函数参数设计应该考虑向下兼容
4.一个函数只做一件事情,尽量保证函数语句粒度的一致性
75 函数调用参数的传递方式是值传递还是引用传递?
Python的参数传递有:位置参数、默认参数、可变参数、关键字参数。
函数的传值到底是值传递还是引用传递、要分情况:
不可变参数用值传递:像整数和字符串这样的不可变对象,是通过拷贝进行传递的,因为你无论如何都不可能在原处改变不可变对象。
可变参数是引用传递:比如像列表,字典这样的对象是通过引用传递、和C语言里面的用指针传递数组很相似,可变对象能在函数内部改变。
76 如何在function里面设置一个全局变量
globals() # 返回包含当前作用余全局变量的字典。global 变量 设置使用全局变量
77 对缺省参数的理解 ?
缺省参数指在调用函数的时候没有传入参数的情况下,调用默认的参数,在调用函数的同时赋值时,所传入的参数会替代默认参数。
*args是不定长参数,它可以表示输入参数是不确定的,可以是任意多个。
**kwargs是关键字参数,赋值的时候是以键值对的方式,参数可以是任意多对在定义函数的时候
不确定会有多少参数会传入时,就可以使用两个参数
78 带参数的装饰器?
带定长参数的装饰器
def new_func(func): def wrappedfun(username, passwd): if username == 'root' and passwd == '123456789': print('通过认证') print('开始执行附加功能') return func() else: print('用户名或密码错误') return return wrappedfun@new_funcdef origin(): print('开始执行函数')origin('root','123456789')
带不定长参数的装饰器
def new_func(func): def wrappedfun(*parts): if parts: counts = len(parts) print('本系统包含 ', end='') for part in parts: print(part, ' ',end='') print('等', counts, '部分') return func() else: print('用户名或密码错误') return func() return wrappedfun
79 为什么函数名字可以当做参数用?
Python中一切皆对象,函数名是函数在内存中的空间,也是一个对象
80 Python中pass语句的作用是什么?
在编写代码时只写框架思路,具体实现还未编写就可以用pass进行占位,是程序不报错,不会进行任何操作。
81 有这样一段代码,print c会输出什么,为什么?
a = 10b = 20c = [a]a = 15
答:10对于字符串,数字,传递是相应的值
82 交换两个变量的值?
a, b = b, a
83 map函数和reduce函数?
map(lambda x: x * x, [1, 2, 3, 4]) # 使用 lambda# [1, 4, 9, 16]reduce(lambda x, y: x * y, [1, 2, 3, 4]) # 相当于 ((1 * 2) * 3) * 4# 24
84 回调函数,如何通信的?
回调函数是把函数的指针(地址)作为参数传递给另一个函数,将整个函数当作一个对象,赋值给调用的函数。
85 Python主要的内置数据类型都有哪些? print dir( ‘a ’) 的输出?
内建类型:布尔类型,数字,字符串,列表,元组,字典,集合
输出字符串'a'的内建方法
86 map(lambda x:xx,[y for y in range(3)])的输出?
[0, 1, 4]
87 hasattr() getattr() setattr() 函数使用详解?
hasattr(object,name)函数:
判断一个对象里面是否有name属性或者name方法,返回bool值,有name属性(方法)返回True,否则返回False。
class function_demo(object): name = 'demo' def run(self): return "hello function"functiondemo = function_demo()res = hasattr(functiondemo, "name") # 判断对象是否有name属性,Trueres = hasattr(functiondemo, "run") # 判断对象是否有run方法,Trueres = hasattr(functiondemo, "age") # 判断对象是否有age属性,Falseprint(res)
getattr(object, name[,default])函数:
获取对象object的属性或者方法,如果存在则打印出来,如果不存在,打印默认值,默认值可选。注意:如果返回的是对象的方法,则打印结果是:方法的内存地址,如果需要运行这个方法,可以在后面添加括号().
functiondemo = function_demo()getattr(functiondemo, "name")# 获取name属性,存在就打印出来 --- demogetattr(functiondemo, "run") # 获取run 方法,存在打印出方法的内存地址getattr(functiondemo, "age") # 获取不存在的属性,报错getattr(functiondemo, "age", 18)# 获取不存在的属性,返回一个默认值
setattr(object, name, values)函数:
给对象的属性赋值,若属性不存在,先创建再赋值
class function_demo(object): name = "demo" def run(self): return "hello function"functiondemo = function_demo()res = hasattr(functiondemo, "age") # 判断age属性是否存在,Falseprint(res)setattr(functiondemo, "age", 18) # 对age属性进行赋值,无返回值res1 = hasattr(functiondemo, "age") # 再次判断属性是否存在,True
综合使用
class function_demo(object): name = "demo" def run(self): return "hello function"functiondemo = function_demo()res = hasattr(functiondemo, "addr") # 先判断是否存在if res: addr = getattr(functiondemo, "addr") print(addr)else: addr = getattr(functiondemo, "addr", setattr(functiondemo, "addr", "北京首都")) print(addr)
88 一句话解决阶乘函数?
reduce(lambda x,y : x*y,range(1,n+1))
89 对设计模式的理解,简述你了解的设计模式?
设计模式是经过总结,优化的,对我们经常会碰到的一些编程问题的可重用解决方案。一个设计模式并不像一个类或一个库那样能够直接作用于我们的代码,反之,设计模式更为高级,它是一种必须在特定情形下实现的一种方法模板。
常见的是工厂模式和单例模式
90 请手写一个单例
#python2class A(object): __instance = None def __new__(cls,*args,**kwargs): if cls.__instance is None: cls.__instance = objecet.__new__(cls) return cls.__instance else: return cls.__instance
91 单例模式的应用场景有那些?
单例模式应用的场景一般发现在以下条件下:
资源共享的情况下,避免由于资源操作时导致的性能或损耗等,如日志文件,应用配置。
控制资源的情况下,方便资源之间的互相通信。如线程池等,1,网站的计数器 2,应用配置 3.多线程池 4数据库配置 数据库连接池 5.应用程序的日志应用…
92 用一行代码生成[1,4,9,16,25,36,49,64,81,100]
print([x*x for x in range(1, 11)])
93 对装饰器的理解,并写出一个计时器记录方法执行性能的装饰器?
装饰器本质上是一个callable object ,它可以让其他函数在不需要做任何代码变动的前提下增加额外功能,装饰器的返回值也是一个函数对象。
import timefrom functools import wrapsdef timeit(func): @wraps(func) def wrapper(*args, **kwargs): start = time.clock() ret = func(*args, **kwargs) end = time.clock() print('used:',end-start) return ret return wrapper@timeitdef foo(): print('in foo()'foo())
94 解释以下什么是闭包?
在函数内部再定义一个函数,并且这个函数用到了外边函数的变量,那么将这个函数以及用到的一些变量称之为闭包。
95 函数装饰器有什么作用?
装饰器本质上是一个callable object,它可以在让其他函数在不需要做任何代码的变动的前提下增加额外的功能。装饰器的返回值也是一个函数的对象,它经常用于有切面需求的场景。比如:插入日志,性能测试,事务处理,缓存。权限的校验等场景,有了装饰器就可以抽离出大量的与函数功能本身无关的雷同代码并发并继续使用。
详细参考:https://manjusaka.itscoder.com/2018/02/23/something-about-decorator/
96 生成器,迭代器的区别?
迭代器是遵循迭代协议的对象。用户可以使用 iter() 以从任何序列得到迭代器(如 list, tuple, dictionary, set 等)。另一个方法则是创建一个另一种形式的迭代器 —— generator 。要获取下一个元素,则使用成员函数 next()(Python 2)或函数 next() function (Python 3) 。当没有元素时,则引发 StopIteration 此例外。若要实现自己的迭代器,则只要实现 next()(Python 2)或 __next__()( Python 3)
生成器(Generator),只是在需要返回数据的时候使用yield语句。每次next()被调用时,生成器会返回它脱离的位置(它记忆语句最后一次执行的位置和所有的数据值)
区别: 生成器能做到迭代器能做的所有事,而且因为自动创建iter()和next()方法,生成器显得特别简洁,而且生成器也是高效的,使用生成器表达式取代列表解析可以同时节省内存。除了创建和保存程序状态的自动方法,当发生器终结时,还会自动抛出StopIteration异常。
97 X是什么类型?
X= (i for i in range(10))
X是 generator类型
98 请用一行代码 实现将1-N 的整数列表以3为单位分组
N =100print ([[x for x in range(1,100)] [i:i+3] for i in range(0,100,3)])
99 Python中yield的用法?
yield就是保存当前程序执行状态。你用for循环的时候,每次取一个元素的时候就会计算一次。用yield的函数叫generator,和iterator一样,它的好处是不用一次计算所有元素,而是用一次算一次,可以节省很多空间,generator每次计算需要上一次计算结果,所以用yield,否则一return,上次计算结果就没了
本文分享自微信公众号 - AI算法与图像处理(AI_study)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。










