
转: https://www.cnblogs.com/sodawoods-blogs/p/8969513.html
(1)生产者概览
(1)不同的应用场景对消息有不同的需求,即是否允许消息丢失、重复、延迟以及吞吐量的要求。不同场景对Kafka生产者的API使用和配置会有直接的影响。
例子1:信用卡事务处理系统,不允许消息的重复和丢失,延迟最大500ms,对吞吐量要求较高。
例子2:保存网站的点击信息,允许少量的消息丢失和重复,延迟可以稍高(用户点击链接可以马上加载出页面即可),吞吐量取决于用户使用网站的频度。
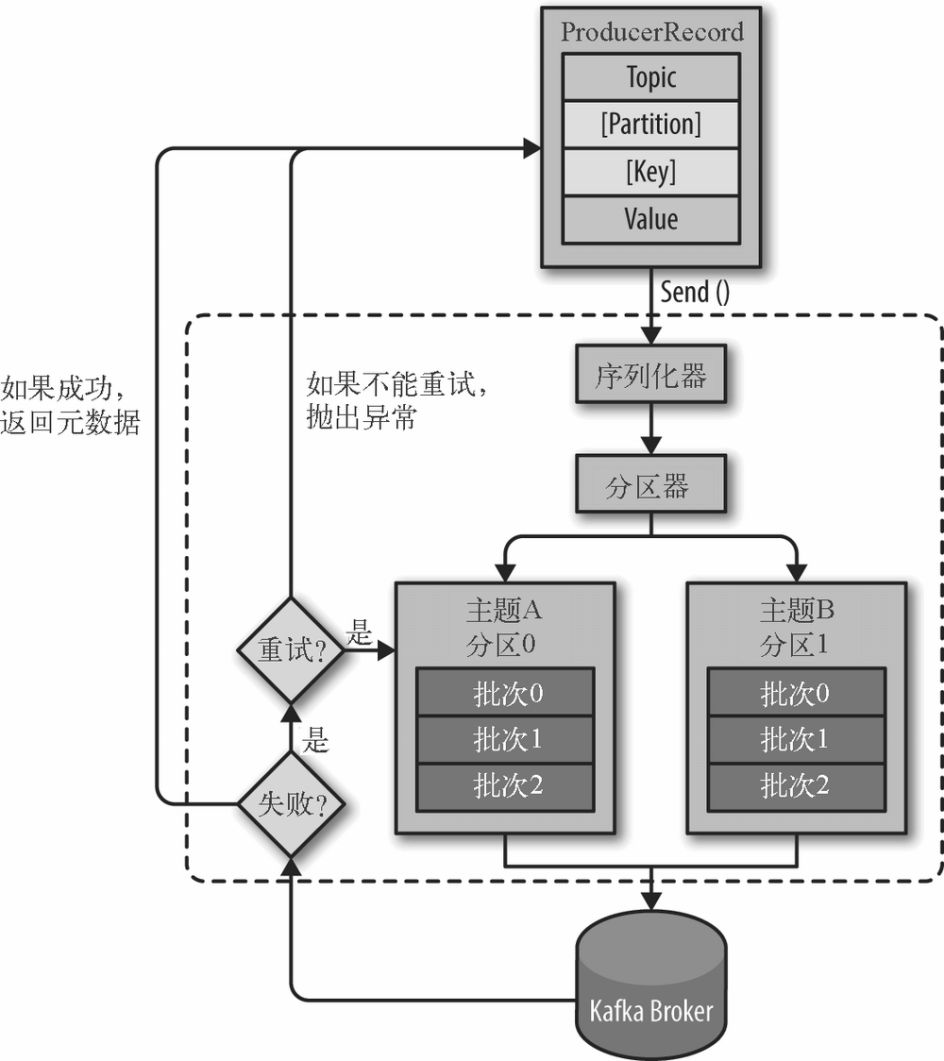
(2)Kafka发送消息的主要步骤
消息格式:每个消息是一个ProducerRecord对象,必须指定消息所属的Topic和消息值Value,此外还可以指定消息所属的Partition以及消息的Key。
1:序列化ProducerRecord
2:如果ProducerRecord中指定了Partition,则Partitioner不做任何事情;否则,Partitioner根据消息的key得到一个Partition。这是生产者就知道向哪个Topic下的哪个Partition发送这条消息。
3:消息被添加到相应的batch中,独立的线程将这些batch发送到Broker上
4:broker收到消息会返回一个响应。如果消息成功写入Kafka,则返回RecordMetaData对象,该对象包含了Topic信息、Patition信息、消息在Partition中的Offset信息;若失败,返回一个错误
(3)Kafka的顺序保证。Kafka保证同一个partition中的消息是有序的,即如果生产者按照一定的顺序发送消息,broker就会按照这个顺序把他们写入partition,消费者也会按照相同的顺序读取他们。
例子:向账户中先存100再取出来 和 先取100再存进去是完全不同的,因此这样的场景对顺序很敏感。
如果某些场景要求消息是有序的,那么不建议把retries设置成0,。可以把max.in.flight.requests.per.connection设置成1,会严重影响生产者的吞吐量,但是可以保证严格有序。
(2)创建Kafka生产者
要往Kafka中写入消息,需要先创建一个Producer,并设置一些属性。
Properties kafkaProps = new Properties();
kafkaProps.put("bootstrap.servers", "broker1:port1, broker2:port2");
kafkaProps.put("key.serializer", "org.apache.kafka.common.StringSerializer");
kafkaProps.put("value.serializer", "org.apache.kafka.common.StringSerializer");
producer = new KafkaProducer<String, String>(kafkaProps);
Kafka的生产者有如下三个必选的属性:
(1)bootstrap.servers,指定broker的地址清单
(2)key.serializer必须是一个实现org.apache.kafka.common.serialization.Serializer接口的类,将key序列化成字节数组。注意:key.serializer必须被设置,即使消息中没有指定key。
(3)value.serializer,****将value序列化成字节数组
(3)发送消息到Kafka
(1)同步发送消息
ProducerRecord<String, String> record = new ProducerRecord<>("CustomCountry", "Precision Products", "France");//Topic Key Value
try{
Future future = producer.send(record);
future.get();//不关心是否发送成功,则不需要这行。
} catch(Exception e) {
e.printStackTrace();//连接错误、No Leader错误都可以通过重试解决;消息太大这类错误kafkaProducer不会进行任何重试,直接抛出异常
}
(2)异步发送消息
ProducerRecord<String, String> record = new ProducerRecord<>("CustomCountry", "Precision Products", "France");//Topic Key Value
producer.send(record, new DemoProducerCallback());//发送消息时,传递一个回调对象,该回调对象必须实现org.apahce.kafka.clients.producer.Callback接口
private class DemoProducerCallback implements Callback {
@Override
public void onCompletion(RecordMetadata recordMetadata, Exception e) {
if (e != null) {//如果Kafka返回一个错误,onCompletion方法抛出一个non null异常。
e.printStackTrace();//对异常进行一些处理,这里只是简单打印出来
}
}
}
(4)生产者的配置
(1)acks指定必须要有多少个partition副本收到消息,生产者才会认为消息的写入是成功的。
acks=0,生产者不需要等待服务器的响应,以网络能支持的最大速度发送消息,吞吐量高,但是如果broker没有收到消息,生产者是不知道的
acks=1,leader partition收到消息,生产者就会收到一个来自服务器的成功响应
acks=all,所有的partition都收到消息,生产者才会收到一个服务器的成功响应
(2)buffer.memory,设置生产者内缓存区域的大小,生产者用它缓冲要发送到服务器的消息。
(3)compression.type,默认情况下,消息发送时不会被压缩,该参数可以设置成snappy、gzip或lz4对发送给broker的消息进行压缩
(4)retries,生产者从服务器收到临时性错误时,生产者重发消息的次数
(5)batch.size,发送到同一个partition的消息会被先存储在batch中,该参数指定一个batch可以使用的内存大小,单位是byte。不一定需要等到batch被填满才能发送
(6)linger.ms,生产者在发送消息前等待linger.ms,从而等待更多的消息加入到batch中。如果batch被填满或者linger.ms达到上限,就把batch中的消息发送出去
(7)max.in.flight.requests.per.connection,生产者在收到服务器响应之前可以发送的消息个数
(5)序列化器
在创建ProducerRecord时,必须指定序列化器,推荐使用序列化框架Avro、Thrift、ProtoBuf等,不推荐自己创建序列化器。
在使用 Avro 之前,需要先定义模式(schema),模式通常使用 JSON 来编写。
(1)创建一个类代表客户,作为消息的value
class Custom {
private int customID;
private String customerName;
public Custom(int customID, String customerName) {
super();
this.customID = customID;
this.customerName = customerName;
}
public int getCustomID() {
return customID;
}
public String getCustomerName() {
return customerName;
}
}
(2)定义schema
{
"namespace": "customerManagement.avro",
"type": "record",
"name": "Customer",
"fields":[
{
"name": "id", "type": "string"
},
{
"name": "name", "type": "string"
},
]
}
(3)生成Avro对象发送到Kafka
Properties props = new Properties();
props.put("bootstrap", "loacalhost:9092");
props.put("key.serializer", "io.confluent.kafka.serializers.KafkaAvroSerializer");
props.put("value.serializer", "io.confluent.kafka.serializers.KafkaAvroSerializer");
props.put("schema.registry.url", schemaUrl);//schema.registry.url指向射麻的存储位置
String topic = "CustomerContacts";
Producer<String, Customer> produer = new KafkaProducer<String, Customer>(props);
//不断生成消息并发送
while (true) {
Customer customer = CustomerGenerator.getNext();
ProducerRecord<String, Customer> record = new ProducerRecord<>(topic, customer.getId(), customer);
producer.send(record);//将customer作为消息的值发送出去,KafkaAvroSerializer会处理剩下的事情
}
(6)Partition
ProducerRecord可以只包含Topic和消息的value,key默认是null,但是大多数应用程序会用到key,key的两个作用:
(1)作为消息的附加信息
(2)决定消息该被写到Topic的哪个partition,拥有相同key的消息会被写到同一个partition。
如果key为空,kafka使用默认的partitioner,使用RoundRobin算法将消息均衡地分布在各个partition上;
如果key不为空,kafka使用自己实现的hash方法对key进行散列,相同的key被映射到相同的partition中。只有在不改变partition数量的前提下,key和partition的映射才能保持不变。
kafka也支持用户实现自己的partitioner,用户自己定义的paritioner需要实现Partitioner接口。











