
在实际的业务中,我们经常会遇到数据迟到的情况,这个时候基于窗口进行计算的结果就不对了,Flink中watermark就是为了解决这个问题的,理解watermark之前,先来说一下flink中的三个与流数据相关的概念,ProcessTime、EventTime、IngestionTime,不然很难理解watermark是怎么回事.
我们先来看一下官网给出的一张图,非常形象地展示了Process Time、Event Time、Ingestion Time这三个时间分别所处的位置,如下图所示:
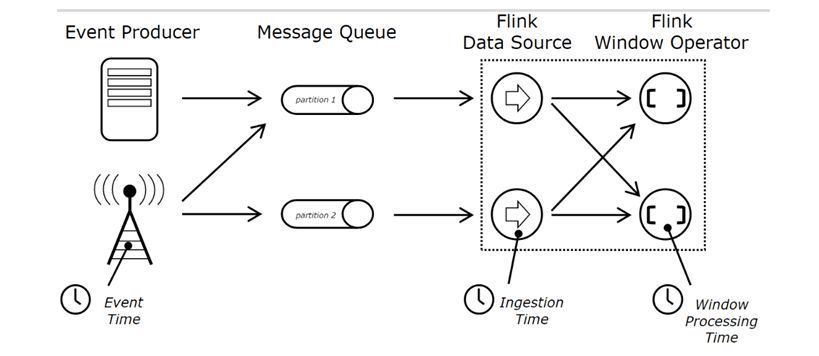
我们按照上图从左到右的顺序介绍这几个概念,依次是event time,ingestion time,processing time.
Event Time
事件时间:事件时间是每条事件在它产生的时候记录的时间,该时间记录在事件中,在处理的时候可以被提取出来。小时的时间窗处理将会包含事件时间在该小时内的所有事件,而忽略事件到达的时间和到达的顺序事件时间对于乱序、延时、或者数据重放等情况,都能给出正确的结果。事件时间依赖于事件本身,而跟物理时钟没有关系。利用事件时间编程必须指定如何生成事件时间的watermark,这是使用事件时间处理事件的机制。机制是这样描述的:事件时间处理通常存在一定的延时,因此自然的需要为延时和无序的事件等待一段时间。因此,使用事件时间编程通常需要与处理时间相结合。
Ingestion Time
摄入时间:摄入时间是事件进入flink的时间,在source operator中,每个事件拿到当前时间作为时间戳,后续的时间窗口基于该时间。摄入时间在概念上处于事件时间和处理时间之间,与处理时间相比稍微昂贵一点,但是能过够给出更多可预测的结果。因为摄入时间使用的是source operator产生的不变的时间,后续不同的operator都将基于这个不变的时间进行处理,但是处理时间使用的是处理消息当时的机器系统时钟的时间。与事件时间相比,摄入时间无法处理延时和无序的情况,但是不需要明确执行如何生成watermark。在系统内部,摄入时间采用更类似于事件时间的处理方式进行处理,但是有自动生成的时间戳和自动的watermark。
Process Time
处理时间:当前机器处理该条事件的时间流处理程序使用该时间进行处理的时候,所有的操作(类似于时间窗口)都会使用当前机器的时间,例如按照小时时间窗进行处理,程序将处理该机器一个小时内接收到的数据。处理时间是最简单的概念,不需要协调机器时间和流中事件相关的时间。他提供了最小的延时和最佳的性能。但是在分布式和异步环境中,处理时间不能提供确定性,因为它对事件到达系统的速度和数据流在系统的各个operator之间处理的速度很敏感。
基于处理时间的系统
对于这个例子,我们期望消息具有格式值,timestamp,其中value是消息,timestamp是在源生成此消息的时间。由于我们正在构建基于处理时间的系统,因此以下代码忽略了时间戳部分。
val text = senv.socketTextStream("localhost", 9999)
情况1:消息到达不间断
假设源分别在时间13秒,第13秒和第16秒产生类型a的三个消息。(小时和分钟不重要,因为窗口大小只有10秒)。
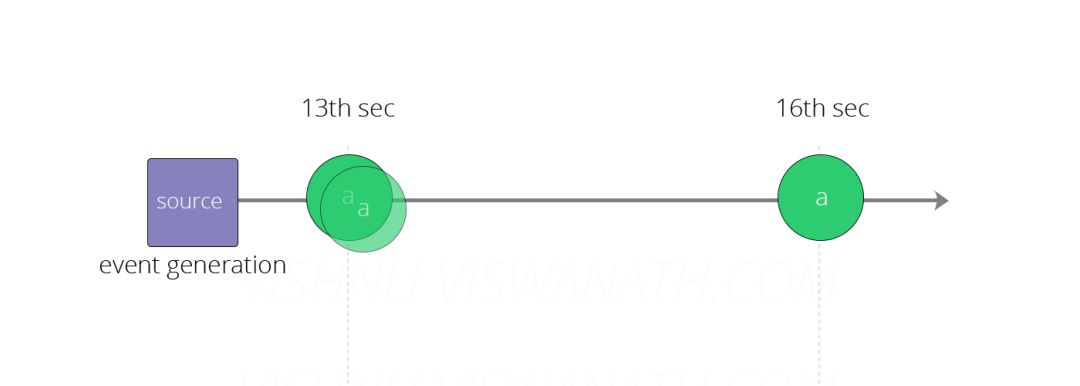
这些消息将落入Windows中,如下所示。在第13秒产生的前两个消息将落入窗口1 [5s-15s]和window2 [10s-20s],第16个时间生成的第三个消息将落入window2 [ 10s-20s]和window3 [15s-25s] ]。每个窗口发出的最终计数分别为(a,2),(a,3)和(a,1)。
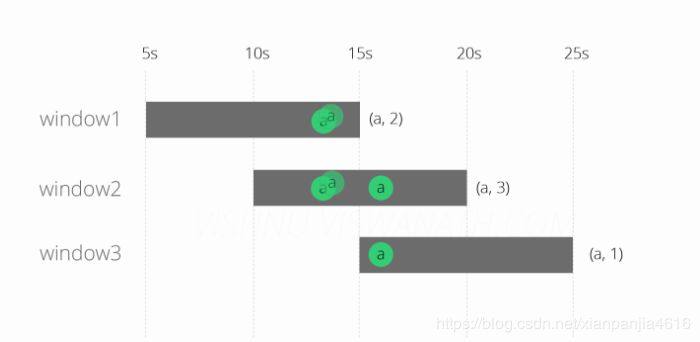
该输出可以被认为是预期的行为。现在我们将看看当一个消息到达系统的时候会发生什么。
情况2:消息到达延迟
现在假设其中一条消息(在第13秒生成)到达延迟6秒(第19秒),可能是由于某些网络拥塞。你能猜测这个消息会落入哪个窗口?
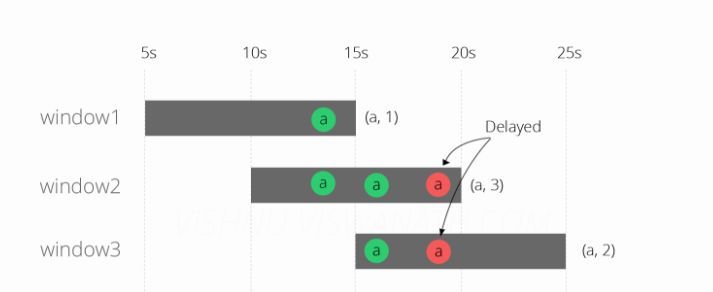
延迟的消息落入窗口2和3,因为19在10-20和15-25之间。在window2中计算没有任何问题(因为消息应该落入该窗口),但是它影响了window1和window3的结果。那怎么办呢?我们现在将尝试使用EventTime处理来解决这个问题。
基于EventTime的系统
我们现在需要设置这个时间戳提取器,并将TimeCharactersistic设置为EventTime。其余的代码与ProcessingTime的情况保持一致。
senv.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
要启用EventTime处理,我们需要一个时间戳提取器,从消息中提取事件时间信息。请记住,消息是格式值,时间戳。该extractTimestamp方法获取时间戳部分并将其作为一个长期。现在忽略getCurrentWatermark方法,我们稍后再回来。
class TimestampExtractor extends AssignerWithPeriodicWatermarks[String] with Serializable {
运行上述代码的结果如下图所示
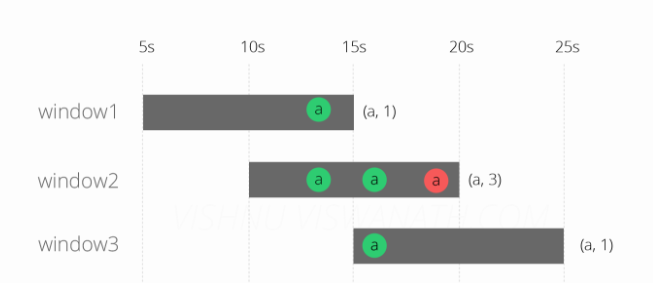
结果看起来更好,窗口2和3现在发出正确的结果,但是window1仍然是错误的。Flink没有将延迟的消息分配给窗口3,因为它现在检查了消息的事件时间,并且理解它不在该窗口中。但是为什么没有将消息分配给窗口1?原因是在延迟的信息到达系统时(第19秒),窗口1的评估已经完成了(第15秒)。现在让我们尝试通过使用水印来解决这个问题。请注意,在窗口2中,延迟的消息仍然位于第19秒,而不是第13秒(事件时间)。该图中的描述是故意表示窗口中的消息不会根据事件时间进行排序。
Watermark
watermark是用于处理乱序事件的,而正确的处理乱序事件,通常用watermark机制结合window来实现。
我们知道,流处理从事件产生,到流经source,再到operator,中间是有一个过程和时间的。虽然大部分情况下,流到operator的数据都是按照事件产生的时间顺序来的,但是也不排除由于网络、背压等原因,导致乱序的产生(out-of-order或者说late element)。
但是对于late element,我们又不能无限期的等下去,必须要有个机制来保证一个特定的时间后,必须触发window去进行计算了。这个特别的机制,就是watermark。
水印本质上是一个时间戳。当Flink中的运算符接收到水印时,它明白(假设)它不会看到比该时间戳更早的消息。因此,在“EventTime”中,水印也可以被认为是一种告诉Flink它有多远的一种方式。
为了这个例子的目的,把它看作是一种告诉Flink一个消息延迟多少的方式。在最后一次尝试中,我们将水印设置为当前系统时间。因此,不要指望任何延迟的消息。我们现在将水印设置为当前时间-5秒,这告诉Flink希望消息最多有5s的延迟,这是因为每个窗口仅在水印通过时被评估。由于我们的水印是当前时间-5秒,所以第一个窗口[5s-15s]将仅在第20秒被评估。类似地,窗口[10s-20s]将在第25秒进行评估,依此类推。
override def getCurrentWatermark(): Watermark = {
通常最好保持接收到的最大时间戳,并创建具有最大预期延迟的水印,而不是从当前系统时间减去。
进行上述更改后运行代码的结果是:
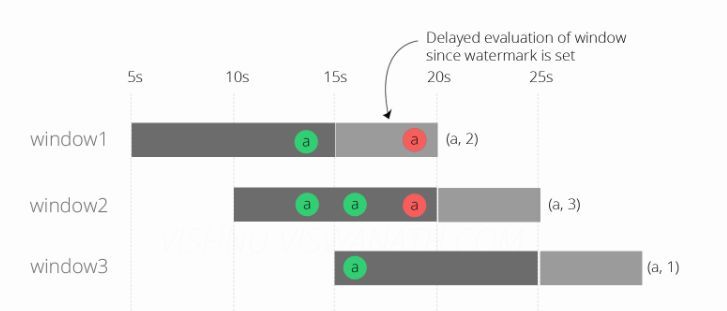
最后我们得到了正确的结果,所有这三个窗口现在都按照预期的方式发射计数,这是(a,2),(a,3)和(a,1)。
allowedLateness
allowedLateness也是Flink处理乱序事件的一个特别重要的特性,默认情况下,当wartermark通过window后,再进来的数据,也就是迟到或者晚到的数据就会别丢弃掉了,但是有的时候我们希望在一个可以接受的范围内,迟到的数据,也可以被处理或者计算,这就是allowedLateness产生的原因了,简而言之呢,allowedLateness就是对于watermark超过end-of-window之后,还允许有一段时间(也是以event time来衡量)来等待之前的数据到达,以便再次处理这些数据。
默认情况下,如果不指定allowedLateness,其值是0,即对于watermark超过end-of-window之后,还有此window的数据到达时,这些数据被删除掉了。
注意:对于trigger是默认的EventTimeTrigger的情况下,allowedLateness会再次触发窗口的计算,而之前触发的数据,会buffer起来,直到watermark超过end-of-window + allowedLateness()的时间,窗口的数据及元数据信息才会被删除。再次计算就是DataFlow模型中的Accumulating的情况。
同时,对于sessionWindow的情况,当late element在allowedLateness范围之内到达时,可能会引起窗口的merge,这样,之前窗口的数据会在新窗口中累加计算,这就是DataFlow模型中的AccumulatingAndRetracting的情况。
下面看一下完整的代码:
package flink
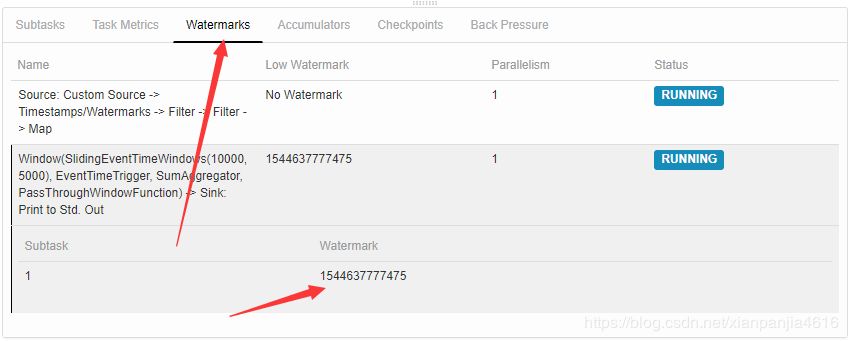
提交后到web,ui上面可以看到watermark的如下图所示:


本文分享自微信公众号 - 大数据技术与架构(import_bigdata)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。












