
Tornado和Celery介绍
1.Tornado
Tornado是一个用python编写的一个强大的、可扩展的异步HTTP服务器,同时也是一个web开发框架。tornado是一个非阻塞式web服务器,其速度相当快。得利于其非阻塞的方式和对 epoll的运用,tornado每秒可以处理数以千计的连接,这意味着对于实时web服务来说,tornado是一个理想的web框架。它在处理严峻的网络流量时表现得足够强健,但却在创建和编写时有着足够的轻量级,并能够被用在大量的应用和工具中。
进一步了解和学习tornado可移步:tornado官方文档
2.Celery
Celery 是一个简单、灵活且可靠的,处理大量消息的分布式系统,它是一个专注于实时处理的任务队列, 同时也支持任务调度。Celery 中有两个比较关键的概念:
Worker: worker 是一个独立的进程,它持续监视队列中是否有需要处理的任务;
Broker: broker 也被称为中间人或者协调者,broker 负责协调客户端和 worker 的沟通。客户端向 队列添加消息,broker 负责把消息派发给 worker。
3.RabbitMQ
RabbitMQ是实现AMQP(高级消息队列协议)的消息中间件的一种,最初起源于金融系统,用于在分布式系统中存储转发消息,在易用性、扩展性、高可用性等方面表现不俗。
RabbitMQ主要是为了实现系统之间的双向解耦而实现的。当生产者大量产生数据时,消费者无法快速消费,那么需要一个中间层。保存这个数据。
例如一个日志系统,很容易使用RabbitMQ简化工作量,一个Consumer可以进行消息的正常处理,另一个Consumer负责对消息进行日志记录,只要在程序中指定两个Consumer所监听的queue以相同的方式绑定到同一exchange即可,剩下的消息分发工作由RabbitMQ完成。
一般情况下,一个工具库或者一个框架都是独立的,有自己的feature或者功能点,可能依赖其他的库,但绝不依赖于其他服务。但是celery是一个特例,如果celery没有broker这个服务,那就完全不能用了。celery 支持多种 broker, 但主要以 RabbitMQ 和 Redis 为主,其他都是试验性的,虽然也可以使用, 但是没有专门的维护者。官方推荐使用rabbitmq作为生产环境下的broker,redis虽然也在官方指名的broker之列,但是实际使用上有可能还会出现以下莫名其妙的问题。
Celery的配置和使用方法详见:官方文档
从Tornado的异步讲起
tornado的同步阻塞
用tornado进行web开发的过程中(实际上用任何语言或者框架开发都会遇到),开发者可能会发现有时候tornado的响应会变慢,追根溯源会发现原因之一就是因为该请求被其他请求阻塞了。这就有问题了啊!!!tornado不是标榜自己是异步Http Web Server吗?不是号称自己解决了C10K问题了吗?这是欺骗消费者啊!!!
但是,深入了解tornado之后才发现,人家说的异步非阻塞是有条件的,只有按照它说的来,才能实现真正的异步非阻塞。。。
我们先来看一个小例子:
1#!/bin/env python 2 3import tornado.httpserver 4import tornado.ioloop 5import tornado.options 6import tornado.web 7import tornado.httpclient 8import torndb 9import time1011from tornado.options import define, options12define("port", default=8000, help="run on the given port", type=int)1314db = torndb.Connection('127.0.0.1:3306', 'user_db', 'username', 'passwd')1516class MysqlHandler(tornado.web.RequestHandler):17 def get(self, flag):18 self.write(db.query('select * from table where flag=%s', flag))1920class NowHandler(tornado.web.RequestHandler):21 def get(self):22 self.write("i want you, right now!")2324if __name__ == "__main__":25 tornado.options.parse_command_line()26 app = tornado.web.Application(handlers=[27 (r"/mysql_query/(\d+)", MysqlHandler), 28 (r"/i_want_you_now", NowHandler)])29 http_server = tornado.httpserver.HTTPServer(app)30 http_server.listen(options.port)31 tornado.ioloop.IOLoop.instance().start()
当我们先请求/mysql_query接口时再请求/i_want_you_now接口,会发现原来可以立刻返回的第二个请求却被一直阻塞到第一个接口执行完之后才返回。为什么?因为大部分web框架都是使用的同步阻塞模型来处理请求的,tornado的默认模型也不例外。但是tornado可是一个异步http服务器啊,不会这么弱吧?而且不上场景下都有一些相当耗时的操作,这些操作就会阻塞其他一些普通的请求,应该怎么解决这个问题?
相信很多使用过tornado的人会想到@tornado.web.asynchronous这个装饰器,但是这就是tornado官方鸡贼的地方了!!!装饰器 web.asynchronous 只能用在verb函数之前(即get/post/delete等),并且需要搭配tornado异步客户端使用,如httpclient.AsyncHTTPClient,或者,你需要异步执行的那个函数(操作)必须也是异步的。。。(我是怨念满满的粗体!!!),而且加上这个装饰器后,开发者必须在异步回调函数里显式调用 RequestHandler.finish 才会结束这次 HTTP 请求。(因为tornado默认在函数处理返回时会自动关闭客户端的连接)
什么意思呢?就是说,tornado:老子只给你提供异步的入口,你要是真想异步操作,要不你就使用我提供的一些异步客户端来搞,不然你就自己实现一个异步的操作。
以操作MongoDB为例,如果你的函数中含有调用mongo的调用(使用pymongo库),那么这时候你加asynchronous这个装饰器就没有任何效果了,因为你的mongo调用本身是同步的,如果想做成异步非阻塞的效果,需要使用mongo出品的另一个python driver -- motor,这个driver支持异步操作mongo,这时候你再加asynchronous装饰器并操作mongo就可以实现异步非阻塞的效果了。
异步非阻塞的实现
所以,如果要使用tornado的异步调用,第一,使用tornado内置的异步客户端如httpclient.AsyncHTTPClient等;第二,可参考内置异步客户端,借助tornado.ioloop.IOLoop封装一个自己的异步客户端,但开发成本并不小。
然而,天无绝人之路,还是有办法可以用较低的成本实现tornado的异步非阻塞的,那就是借助celery项目。前面说了,它是一个分布式的实时处理消息队列调度系统,tornado接到请求后,可以把所有的复杂业务逻辑处理、数据库操作以及IO等各种耗时的同步任务交给celery,由这个任务队列异步处理完后,再返回给tornado。这样只要保证tornado和celery的交互是异步的,那么整个服务是完全异步的。至于如何保证tornado和celery之间的交互是异步的,可以借助tornado-celery这个适配器来实现。
celery配合rabbitmq的工作流程如下:
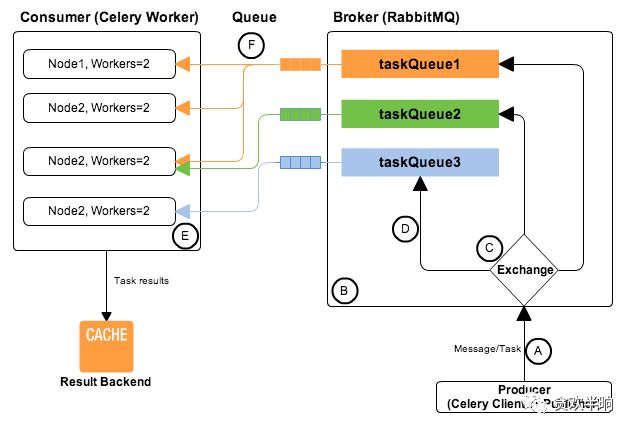
这里我们来使用这几个组件重写前面的同步阻塞的例子:
1#!/bin/env python 2 3import tornado.httpserver 4import tornado.ioloop 5import tornado.options 6import tornado.web 7import tornado.httpclient 8 9import time10import tcelery, tasks11from tornado.options import define, options12tcelery.setup_nonblocking_producer()13define("port", default=8000, help="run on the given port", type=int)1415class AsyncMysqlHandler(tornado.web.RequestHandler):16 @tornado.web.asynchronous17 @tornado.gen.coroutine18 def get(self, flag):19 res = yield tornado.gen.Task(tasks.query_mysql.apply_async, args=[flag])20 self.write(res.result)21 self.finish()2223class NowHandler(tornado.web.RequestHandler):24 def get(self):25 self.write("i want you, right now!")2627if __name__ == "__main__":28 tornado.options.parse_command_line()29 app = tornado.web.Application(handlers=[30 (r"/mysql_query/(\d+)", AsyncMysqlHandler), 31 (r"/i_want_you_now", NowHandler)])32 http_server = tornado.httpserver.HTTPServer(app)33 http_server.listen(options.port)34 tornado.ioloop.IOLoop.instance().start()
这里有个新的tornado.gen.coroutine装饰器, coroutine是3.0之后新增的装饰器.以前的办法是用回调函数的方式进行异步调用,如果使用回调函数的方式,则代码如下:
1#!/bin/env python 2 3import tornado.httpserver 4import tornado.ioloop 5import tornado.options 6import tornado.web 7import tornado.httpclient 8import time 9import tcelery, tasks10from tornado.options import define, options11tcelery.setup_nonblocking_producer()12define("port", default=8000, help="run on the given port", type=int)1314class AsyncMysqlHandler(tornado.web.RequestHandler):15 @tornado.web.asynchronous16 def get(self, flag):17 tasks.query_mysql.apply_async(args=[flag], callback=self.on_result)1819 def on_result(self, response):20 self.write(response.result)21 self.finish()2223class NowHandler(tornado.web.RequestHandler):24 def get(self):25 self.write("i want you, right now!")2627if __name__ == "__main__":28 tornado.options.parse_command_line()29 app = tornado.web.Application(handlers=[30 (r"/mysql_query/(\d+)", AsyncMysqlHandler), 31 (r"/i_want_you_now", NowHandler)])32 http_server = tornado.httpserver.HTTPServer(app)33 http_server.listen(options.port)34 tornado.ioloop.IOLoop.instance().start()
使用callback的话始终觉得会是的代码结构变得比较混乱,试想如果有大量异步回调,每一个都写一个回调函数的话,势必导致项目代码结构变得不那么清晰和优雅,毕竟回调这种反人类的写法还是很多人不喜欢的,但也看个人喜好,不喜欢callback风格的可以使用yield来进行异步调用。
tasks.py集中放置开发者需要异步执行的函数。
1import time 2import torndb 3from celery import Celery 4 5db = torndb.Connection('127.0.0.1:3306', 'user_db', 'username', 'passwd') 6app = Celery("tasks", broker="amqp://guest:guest@localhost:5672") 7app.conf.CELERY_RESULT_BACKEND = "amqp://guest:guest@localhost:5672" 8 9@app.task(name='task.query_users')10def query_mysql(flag):11 return db.query('select * from table where flag=%s', flag)1213if __name__ == "__main__":14 app.start()
然后启动celery worker监听任务队列(消费者会从任务队列中取走一个个的task并执行):
1celery -A tasks worker --loglevel=info
自此,依靠这种架构,可以实现tornado处理请求的完全异步调用。
问题及优化
1.队列过长问题
使用上述方案的异步非阻塞可能会依赖于celery的任务队列长度,若队列中的任务过多,则可能导致长时间等待,降低效率。
解决方案:
启动多个celery worker监听任务队列,使用多进程并发消费任务队列,celery命令可以通过-concurrency参数来指定用来执行任务而prefork的worker进程,如果所有的worker都在执行任务,那么新添加的任务必须要等待有一个正在执行的任务完成后才能被执行,默认的concurrency数量是机器上CPU的数量。另外,celery是支持好几个并发模式的,有prefork,threading,协程(gevent,eventlet),prefork在celery的介绍是,默认是用了multiprocess来实现的;可以通过-p参数指定其他的并发模型,如gevent(需自己配置好gevent环境)。
建立多个任务queue,把大量的任务分发到不同的queue中,减轻单个queue时可能出现的任务数量过载。
2.水平扩展优化
前面说了celery是一个分布式系统,也就是说,基于celery的项目可无痛实现分布式扩展,前面写的tornado和celery配合的demo,也可以实现独立部署,即tornado server和celery server其实可以分开部署,即分布在不同的服务器上,celery server部署自己的tasks.py任务,并启动celery worker监听,然后在tornado server上添加以下代码:
1from celery import Celery2app = Celery(broker = "amqp://",)
并使用Celery的send_task函数调用任务:
1app.send_task('function_name', args=[param1, param2, param3...])
即可实现tornado和celery的完全解耦。
后续:
另外,了解到tornado.concurrent.futures(py3自带这个库,py2需单独安装)这个module可以实现自定义函数的异步化,目前还没有深入了解这个东西,有时间去研究一下这个东西,有心得再分享一下这个module相关的知识。
本文分享自微信公众号 - 潘建锋(R136a1_Pan)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。












